并发编程之无锁

其中的关键是compareAndSet,它的简称就是CAS(也有Compare And Swap的说法),它必须是原子操作。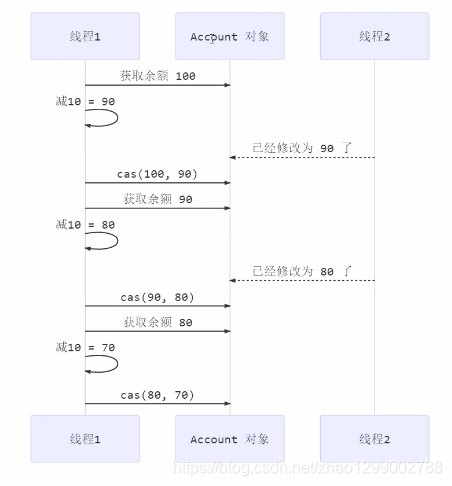
注意
其实CAS的底层是lock cmpxchg指令(X86架构),在单核CPU和多核CPU下都能够保证【比较-交换】的原子性。
- 在多核状态下,某个核执行到带lock的指令时,CPU会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
volatile
获取共享变量时,为了保证变量的可见性,需要使用volatile修饰。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作volatile变量都是直接操作主存。即一个线程对volatile变量的修改,对另一个线程可见。
注意 :
volatile仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS必须借助volatile才能读取到共享变量的最新值来实现【比较并交换】的效果
为什么无锁效率高 - 无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而synchronized会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。打个比喻
- 线程就好像高速跑道上的赛车,高速运行时,速度超快,一旦发生上下文切换,就好比赛车要减速、熄火,等被唤醒又得重新打火、启动、加速…恢复到高速运行,代价比较大
- 但无锁情况下,因为线程要保存运行,需要额外CPU的支持,CPU在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,任然会进入可运行状态,还是会导致上下文切换。
CAS的特点
结合CAS和volatile可以实现无锁并发,适用于线程数少、多核CPU的场景下。 - CAS是基于乐观锁的思想 :最客观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试。
- synchronized是基于悲观锁的思想 :最悲观的估计,提防着其他线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
- CAS体现的是无锁并发、无阻塞并发
- 因为没有使用synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
package com.example.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
import java.util.function.Consumer;
import java.util.function.Supplier;
public class Test4 {
public static void main(String[] args) {
demo(
() -> new AtomicLong(0),
(adder) -> adder.getAndIncrement()
);
demo(
() -> new LongAdder(),
(adder) -> adder.increment()
);
}
/**
*
* @param adderSupplier : () -> 结果 提供累加器对象
* @param action : (参数) -> void 执行累加操作
* @param <T>
*/
private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) {
T adder = adderSupplier.get();
List<Thread> threadList = new ArrayList<>();
// 4个线程,每人累加50万
for (int i = 0; i < 4; i++) {
threadList.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
long start = System.nanoTime();
threadList.forEach(t -> t.start());
long end = System.nanoTime();
System.out.println(adder + " cost : " + (end - start));
}
}
package com.example.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.function.BiConsumer;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Supplier;
public class Test3 {
public static void main(String[] args) {
}
/**
* 参数1,提供数组,可以是线程不安全数组或线程安全数组
* 参数2,获取数组长度的方法
* 参数3,自增方法,回传array,index
* 参数4,打印数组的方法
*
* @param arraySupplier : 提供者 无中生有 () -> 结果
* @param lengthFun : 函数 一个参数一个结果 (参数) -> 结果 ,BiFunction(参数1,参数2) -> 结果
* @param putConsumer : 消费者 (参数1,参数2) -> void
* @param printConsumer : 消费者 (参数) -> void
* @param <T>
*/
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer
) {
List<Thread> threadList = new ArrayList<>();
T array = arraySupplier.get();
Integer length = lengthFun.apply(array);
for (int i = 0; i < length; i++) {
// 每个线程对数组做10000次操作
threadList.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j % length);
}
}));
}
threadList.forEach(thread -> thread.start());
}
}
输出
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Thread-0累加 Cel【0】,而Thread-1累加Cell【1】。。。最后将结果汇总。这样它们在累加时操作的不同的Cell变量,因此减少了CAS重试失败,从而提高性能。
LongAdder类有几个关键域
- 原理之伪共享
其中Cell即为累加单元
缓存与内存的速度比较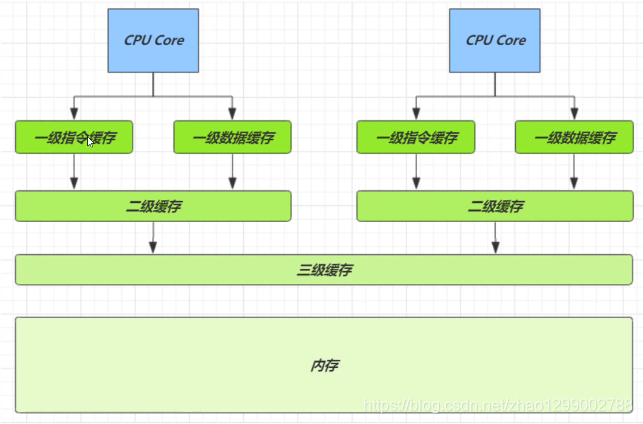

因为CPU与内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是64byte(8个long)
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中,CPU要保证数据的一致性,如果某个CPU核心更改了数据其它CPU核心对应的整个缓存行必须失效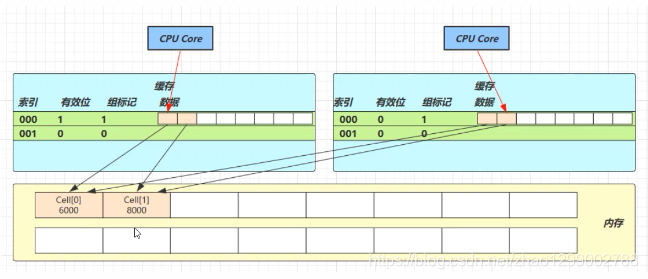
因为Cell是数组形式,在内存中是连续存储的,一个Cell为24字节(16字节的对象头和8字节的value),因此缓存行可以存下2个的Cell对象。这样问题来了 : - Core-0要修改Cell【0】
- Core-1要修改Cell【1】
无论谁修改成功,都会导致对方Core的缓存行失效,比如Core-0中Cell【0】=6000,Cell【1】=8000 要累加Cell【0】=6001,Cell【1】=8000,这时会让Core-1的缓存行失效
@sun.misc.Contended用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加128字节大小的padding,从而让CPU将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效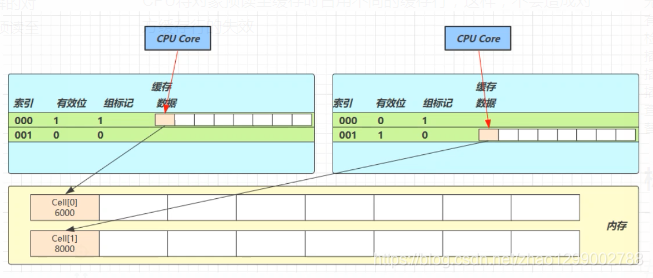
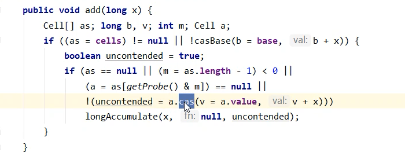
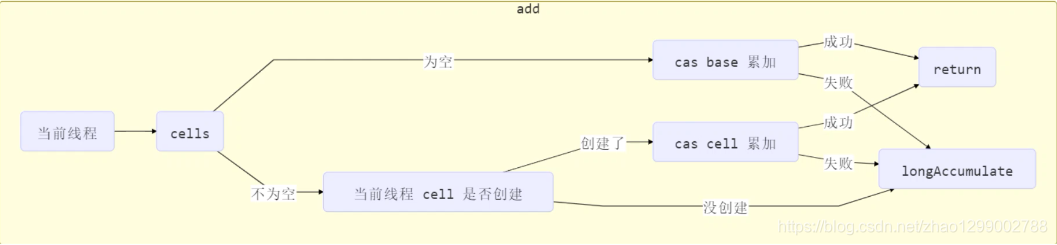

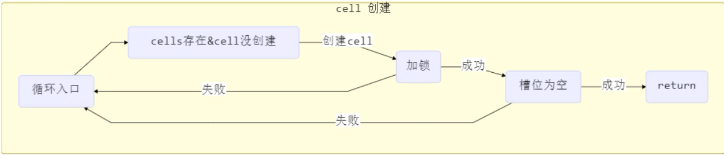
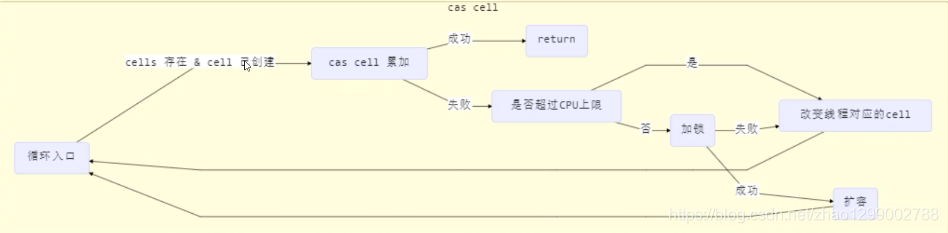
获取最终结果通过sun方法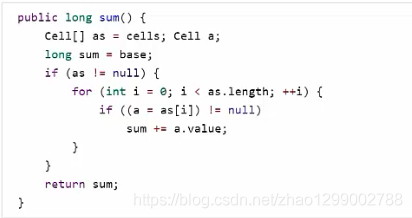
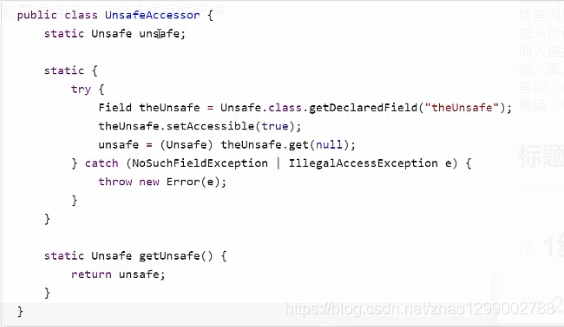
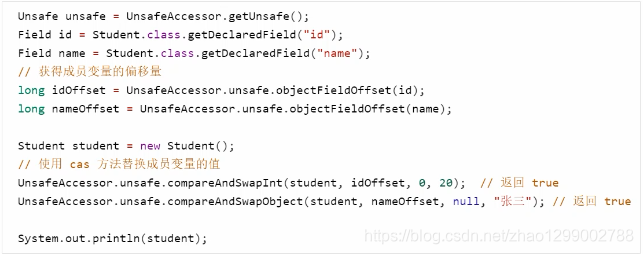
概述
Unsafe对象提供了非常底层的,操作内存、线程的方法,Unsafe对象不能直接调用,只能通过反射获得