提供性能:
.服务器往往具有强大的计算能力和速度。
.避免把大量的数据下载到客户端,减少网络上的传输量。
第一章 T-SQL 语句
1.1数据类型
1.2 常量和变量
1.3.运算符
1.4.流程控制
第二章 数据库的定义与操作(自定义表,系统表)
2.1.列约束
2.2. 批量插入
2.3. 创建临时表
2.4 系统表
2.5 临时表与表变量
第三章 数据查询
3.1 group by
3.2 having 和 order by
3.3 运算符(可以用于where 与 if,while ,case等语句中)
3.4 .函数(聚合函数,over):
3.5. 关联查询 UNION
第五章 游标,存储过程和函数,事务
5.1 游标
5.2 存储过程
第七章 XML
第一章 T-SQL 语句
1.1数据类型
文本类型
char(10)和 nchar(10)
- char(10) 10个字符,每个字符占用一个字节,可以存放10个字母,5个汉子
- nchar(10)20个字符,每个字符占用两个字节,可以放10个字母(字母用一个字节,还剩的一个字节用空格补充),10个汉子
char(10)和varchar(10)
- char(10)多余的字节以空格填充
- varchar(10)如果字符长度不够,根据实际长度,如果字符长度超过10,则截取
- varchar(10)和char(10)最长可以存10个字节,若数据过长,会截取长度;
- varchar(max)--不确定文本
sql 中支持两种字符数据类型,普通字符和unicode字符,unicode字符包括Nchar和Nvarchar,用于存储汉字
查询要加‘N’
select id, errormsg,jiqibianma,filedate from Chengxingj_Data_log_cuowu where errormsg=N'E001704 (100) D1 热电偶异常。请按解除键。'
日期型:插入日期数据时候用字符串表示
- DateTime (1753.1.1-9999.12.31 )8字节
- DateTime 2 (7) --数据库常用,存储的精度比DateTime大
- smallDateTime --存储到分钟,基本不用
- time(0) :以字符串形式记录一天的某个时间,格式“hh:mm:ss[.nnnnnnn]”
- 存储日期:date
取得系统时间:Getdate()
整数数字类型
(1).int --4个字节
(2).tinyint --1个字节(2^8,0~255)
(3)bit --1个字节,通常表示bool
浮点数据类型--浮点类型的四舍五入 和 除数运算(*1.0)
(1)float--8 个字节
(2).decimal[(p[,s])]和numeric[(p[,s]) :p 表示位数,s表示精度
ps:如果在数据库中存数据,建议使用decimal类型,使用real和float 类型可能会造成小数点后很多位
decimal(18,5) //共18位,其中5位是小数
四舍五入
select convert(decimal(18,2),12.345) -- 12.35
ps :sql 除法运算,要* 1.0,否则结果都是0
uniqueidentifier
全局唯一标识符 (GUID)
该类型一般用来做为主键使用,可用SQL语法的newid()来生成一个唯一的值。
ps:对应 c#的代码是 Guid 类型
1.2 常量和变量
日期和时间常量
SQL规定日期、时间和时间间隔的常量被指定为字符串常量。eg:'1990-05-06'
局部变量定义与变量赋值
--定义变量,变量名要以@开头
declare @songname char(10) --赋值方式有两种 --1.select 赋值 select @songname=课程内容 from course where 课程类别='艺术类' --当有多个结果时候,取最后一条数据 print @songname --2. set 赋值 set @songname='选项'
ps .
- 使用select,如果查询出多个值,变量中只存最后一个值,不会存一组值
- 必须要先定义才能赋值
全局变量
- SQL事先定义好的,以@@开头的
- @@ERROR 返回上条T-SQL 语句返回的错误代码
- @@IDENTITY 返回最近一次插入的identity列的数值,返回值是numeric。
- @@ROWCOUNT 返回最近一次插入受影响的行数
1.3.运算符
使用<>代替!>
- between ...and 相当于 (>=...<=)
- is null 来判断控制,is not null 来判断不是
- exists 和 not exists :exists 只注重查询语句是否返回行,如果返回一个或多个,则为真值。多用于if 语句中
select * from dbo.demo where age<(select AVG(age) from dbo.demo ) and exists(select * from demo where age=120)
if (object_id('pro_page', 'P') is not null) --P 表示存储过程
ps: 可用于所有判断语句中,不仅是where,还有if ,while 等
1.4.流程控制
三大语句:顺序,选择,循环;跳出循环语句的break和continue
BEGIN...END相当与{}
选择
- 选择包括 if....else 和 case ...end两种,第二种用在select 的字段上
- IF...ELSE
declare @ x int,@y int set @x=8 set @y=3 if @x>@y print '@X 大于 @y' else print ‘@x 小于 @y’
ps:如果 if或者else 后跟着两条以上的语句,要用begin ....end
- 条件判断 case (列转行)
CASE sex
WHEN 表达式1 THEN result
WHEN 表达式2 THEN result
ELSE 表达式2 END
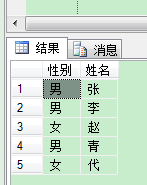
SELECT 性别= CASE sex WHEN 1 THEN '男' WHEN 2 THEN '女'
ELSE '其他'
END, CAST(name AS VARCHAR(2)) AS '姓名' FROM dbo.demo
循环 while
DECLARE @n INT,@sum INT SET @sum=0 SET @n=1 --注意 不能写成 set @sum=0,@n=1 WHILE @n<=10 BEGIN SET @sum=@sum+@n SET @n=@n+1 END PRINT @sum
ps:
- 每句的结尾不以;结尾
- set 其实相当于; ,告诉程序上局结束,这句开始了
while ...continue...break
DECLARE @n INT,@sum INT SET @sum=0 SET @n=2 WHILE @n<10 BEGIN SET @n=@n+1 IF @n%2=0 SET @sum=@sum+@n ELSE BREAK --注意 相当于 else {break} PRINT '只有@n是偶数才输出这句话' END PRINT @sum
break 跳出循环,continue 跳出此次循环,程序遇到break 或者continue 后,下面的程序就会终止执行
1.5 go
每个被GO分隔的语句都是一个单独的事务,一个语句执行失败不会影响其它语句执行。例如以下列子,图2加了go之后,即使第一条语句出错,第二条语句照样执行
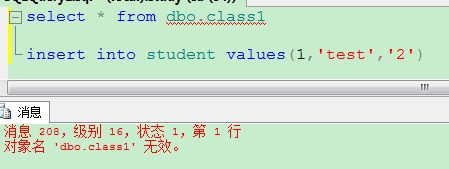

图1 图2
1.6 常用命令
print--可以用于调试
1.7 字段命名如果是关键字可以用[]
第二章 数据库的定义与操作(自定义表,系统表)
2.1.列约束
每一列可以有一个或多个约束
- primary key :约束所有的列值必须是唯一的,且列不能包含Null 值,相当于主键
- unique :约束列中所有值必须是不同的值,但 null 是容许的
- not null: 约束列中这个列不允许有null 值
- check:约束列输入的数据,例如约束 “年龄”列值不允许小于零
- default :给列默认值
use student create table loving ( 学号 varchar(8), 姓名 varchar(10) unique, 年龄 int check(年龄>=0) )
2.2. 批量插入
insert into course(list1,list2)select list1,list2 from course
select * into course1 from course // 复制一张表
2.3. 创建临时表
方法一:
create table #临时表名(字段1 约束条件,
字段2 约束条件,
.....)
create table ##临时表名(字段1 约束条件,
字段2 约束条件,
.....)
方法二:
select * into #临时表名 from 你的表;
select * into ##临时表名 from 你的表;
注:使用临时表时候要先判断当前系统中是否存在要创建的临时表,有就删除
1、局部临时表(#开头)只对当前连接有效,当前连接断开时自动删除。
2、全局临时表(##开头)对其它连接也有效,在当前连接和其他访问过它的连接都断开时自动删除。
3、不管局部临时表还是全局临时表,只要连接有访问权限,都可以用drop table #Tmp(或者drop table ##Tmp)来显式删除临时表。
创建的临时表存在于tempdb数据库中,数据库如果重新启动的话或者系统修复时候会被自动删除
所以临时表使用完要删除
2.4 系统表
- sys.objects--存放数据库的所有表名,视图,存储过程,约束,触发器等信息都在此表中
- 从sys.objects 查询某个表或者视图存不存在 可以
select object_id from sys.objects where name='student' and type='U' 可以简化写 select object_id('student','U') --u表示用户表
2.5 临时表与表变量
(1)表变量
表变量可以在 SELECT,DELETE,UPDATE,INSERT语句中使用,但是表变量不能在类似"SELECT select_list INTO table_variable"这样的语句中使用。
而在SQL Server2000中,表变量也不能用于INSERT INTO table_variable EXEC stored_procedure这样的语句中。
但是可以用 insert into table1 select list from table2 这样的语句
考虑表变量是存放在内存中的,所以一般是用在数据比较小的时候(小于100数据)
DECLARE @tb1 Table ( Id int, Name varchar(20), Age int ) INSERT INTO @tb1 VALUES(1,'刘备',22) SELECT * FROM @tb1
ps:
1)表变量是存储在内存中的,当用户在访问表变量的时候,SQL Server是不产生日志的,而在临时表中是产生日志的;
2)表变量是不允许创建索引
3)表变量不产生日志
4)表变量是不允许有default默认值,也不允许有约束;
ALTER TABLE @tb1 ADD CONSTRAINT CN_AccountAge CHECK (Account_Age > 18); -- 插入年龄必须大于18
SQL Server提示错误如下:

第三章 数据简单查询
where ---- group by all having -
select -- distinct ,top ,over
order by
3.1 group by
- group by:group by 必须包含所有 select 查询的所有非聚合字段;
- group by 会默认去掉 聚合函数为0 的行,加 all 就会显示所有的 行
- 使用group by 会构建出一张新的表,以后having ,order by 会在此表上进行操作
-- group by 后必须要包含select 中所有非聚合函数的字段
select sex ,name,sum(age) from student where age>10 group by all sex,name
- group by all:显示出所有分组的数据,即使聚合函数计算的结果为0
select safetystocklevel,count(productid) as productcount from Production.Product where finishedgoodsflag=1 group by safetystocklevel --图1
select safetystocklevel,count(productid) as productcount from Production.Product where finishedgoodsflag=1 group by all safetystocklevel --图2


3.2 having 和 order by
- having:对查询的结果再进行筛选
- 聚合函数不能出现在where 语句中,只能出现在having中
- order by:desc 降序,默认是升序
3.4 .函数:
(1)聚合函数:可以与group by合用,也可以不合用
avg(numeric_expr)返回组中各值的平均值
max(express)---返回表达式的最大值
min(express)---返回表达式的最小值
sum(express) -返回表达式中所有值的和
count(*) 与 count(列名),count(distinct 列名) 区别
count(*) 会把null列也计算在内,count(columname) 只把列内容不是null的计算
count(distinct column_name): 会去除重复列,返回指定列的不同值的数目
(2)字符串处理函数
charindex()---寻找指定的字符串在另一个字符串中的起始位置
select charindex("sql","my sql hello") --4 select charindex("sql" ,"my sql hello", 2) --4 ,2是指定起始位置 select charindex("sql" ,"my sql hello", 8) --0 ,找不到显示0
len()--计算长度
select len("hello world")--12
lower()和upper()--大小写转换
ltrim() 和 rtrim() --去除左右空格
left(),right(),substring(expression,start,len)---截取子串
select right("my sql",3) --sql
reverse()--返回字符串翻转后的新字符串
replace,stuff--替换字符串
select stuff("hello world",2,2,"sql")--hesqlo world ,stuff 删除指定位置,指定长度的字符并且替换成新的字符
倒顺操作字符串
ps:substring (express,start,len):第一个字符从 1开始,如果查询不到返回 0;start 不支持负数
(3)日期类型
日期类型:'1990-05-06' --这样在sql 中可以表示日期类型,也可以表示字符串类型
getdate() --获取当前系统时间
dateadd()--给指定的日期添加
select dateadd(day,5,'1990-05-06')--1990 05 11
datediff()--计算相差多少个年月日
select datediff(year,'1990-05-06',getdate) --26
datepart()和 datename()--日期的部分,datepart和datename 用法一样唯一的区别是weekday的显示
select DATENAME(weekday,'2015-08-15') --星期六
select DATEPART(weekday,'2015-08-15') --7
day(),year(),month()
日期格式:使用convert()
(4)系统类型
Convert(data-type [(length)], expression[,style]))---将一种数据类型转换为另一种数据类型
SELECT CONVERT(Varchar(20), GETDATE()) SELECT CONVERT(Varchar(20), GETDATE(), 101)
Isnull(检查表达式,替换值)---将null替换为指定的替换值
Nullif(表达式,表达式)如果二者不等价,则返回第一个表达式;否则返回null值---如果两个表达式等价,则返回null值
Scope_Identity()---返回插入到同一范围内的IDENTITY列中的上一个IDENTITY值
CAST() 与 Convert() 等价
CAST函数用于将某种数据类型的表达式显式转换为另一种数据类型
SELECT CAST(name AS varchar(2)) FROM dbo.demo
newid ()生成guid
- guid 生成id :select newid(),guid:根据mac地址和时间(精确到纳秒)等计算生成,同台计算机每次生成的guid都不可能是相同的,不同计算机生成的guid也不可能相同
- sql server 关键字大小写不敏感
3.5. 关联查询 UNION
将两张表合并到同一张表(两张表可以没有任何的关联)
- 两个select 语句选择列表中的列数必须一样多,并且对应位置上的列的数据类型必须相同或者兼容
- 列的名字或者别名是由第一个select语句的选择列表决定的
- order by 必须在新表上进行操作
-
-- 去除重复行,求并集
select * from dbo.demo union select * from demo2
--显示所有列 select * from dbo.demo union all select * from demo2
--排序 select * from dbo.demo union all select * from demo2 order by age>10
--转换 select id, str(sex),name from dbo.demo union select 学号,姓名 ,str(年龄) from loving
ps:except 求两个集合的差集,union 取并集 ,INTERSECT 求两个集合的交集
SQL定义了集合运算之间的优先级:INTERSECT最高,UNION和EXCEPT相等。
换句话说:首先会计算INTERSECT,然后按照从左至右的出现顺序依次处理优先级相同的运算。(加括号更好理解)
-- 集合运算的优先级 select country, region, city from Production.Suppliers except select country, region, city from hr.Employees intersect select country, region, city from sales.Customers;
上面这段SQL代码,因为INTERSECT优先级比EXCEPT高,所以首先进行INTERSECT交集运算。因此,这个查询的含义是:返回没有出现在员工地址和客户地址交集中的供应商地址。
3.7 over 的用法
ROW_NUMBER() OVER ( order by ChengXingj_Dianj.id desc) --先对表按id 倒叙排序,后编号
第四章 游标,存储过程和函数
5.1 游标
DECLARE @ID int --定义游标 DECLARE MyCursor CURSOR FOR SELECT ID FROM tbclass_1 --打开一个游标 OPEN MyCursor --循环一个游标 FETCH NEXT FROM MyCursor INTO @ID WHILE @@FETCH_STATUS =0 BEGIN --sql代码块 FETCH NEXT FROM MyCursor INTO @ID END CLOSE MyCursor --关闭游标 DEALLOCATE MyCursor --释放游标
5.2 存储过程
(1)语法
--单条语句的存储过程创建
create proc | procedure pro_name [{@参数数据类型} [=默认值] , {@参数数据类型} [=默认值] [output], .... ] as SQL_statements
-- 多条语句的存储过程创建
if (exists (select * from sys.objects where name = 'proc_get_student')) drop proc proc_get_student go create proc proc_get_student as
begin select * from student;
delete from student;
end
ps:
- as后如果有多条语句就要加 begin ....end
- output可以作为返回值来使用,Output 此参数只用于将信息从存储过程传输回应用程序
5.3 创建function
create function dbo.bmrs(@bmh as int) returns int as begin declare @bmrs int select @bmrs=count(工号) from 销售人员 where 部门号=@bmh return @bmrs end go exec sp_help 销售人员
第 五章 触发器
触发器 能不用就不要用它,很难管理
第六章 XML
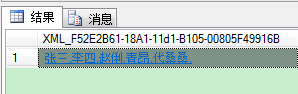
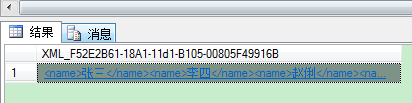
for xml path
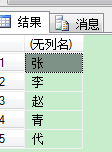
SELECT name+',' FROM demo FOR XML PATH('') --图1
SELECT name FROM demo FOR XML PATH('') --图2
6.1 取别名
SELECT sex ,name AS myname FROM demo FOR XML PATH('mytable')--根节点用在 path()中,字段用as 取别名
