机器学习系统设计
确定执行的优先权(Prioritizing what to work on:Spam classification example)
问自己两个关键测试的问题:
1、当一个专家看到了这些特征量x,他能很有信心的预测出y值吗?
2、我们能获得庞大的训练数据集吗,并用很多参数去训练学习算法?
误差分析(Error analysis)
当你遇到一个机器学习的问题时,推荐的方法:
1、从能迅速实现的简单算法开始。实现它并基于交叉验证集测试它;
2、画学习曲线,决定更多数据、或者更多特征等方法是否可能有帮助;
3、误差分析(使用交叉验证集,而不是测试集):人工分析出现错误的验证集的样本,查看是否在某些类型的样本上出现系统性出错趋势。单一规则的数值评价指标算法的评估误差度量值

不对称分类的误差评估(Error metrics for skewed classes)
问题来源,以癌症例子为例,算法误差1%,但只有0.5%的病人是真正有癌症的,比误差还小。
这就是,负样本的数量远远少于正样本的数量,这就是偏斜类问题。这样中问题,总是预测0或预测1,就会是误差很小。只用之前的预测精确度评估算法好不好就显得捉襟见肘了。
因此,需要一个不同的测量标准。
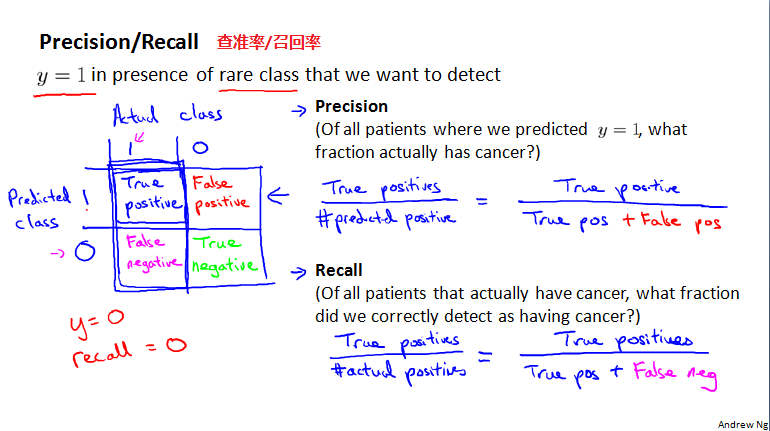
查准率(精确度)和召回率:
精确率:预测有病(y=1)的人中,有多少真有病。
召回率:真正有病的人中,有多少是预测对了的,叫病人回来,给予治疗。
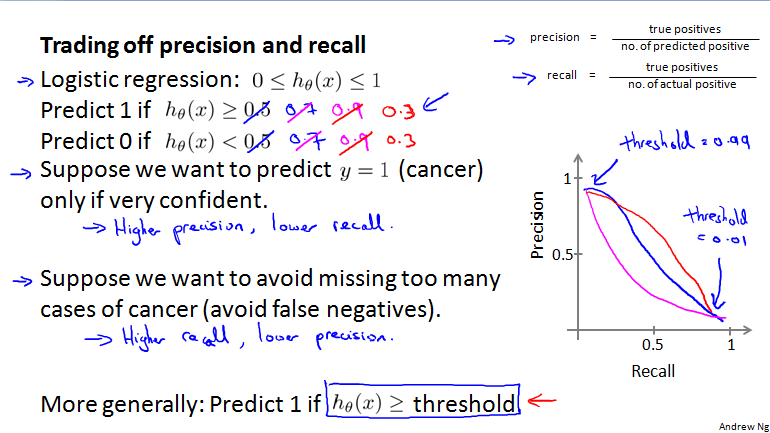
查准率和召回率的权衡(Trading off precision and recall)
如何权衡查准率和召回率?高查准率以及高召回率才是我们的选择
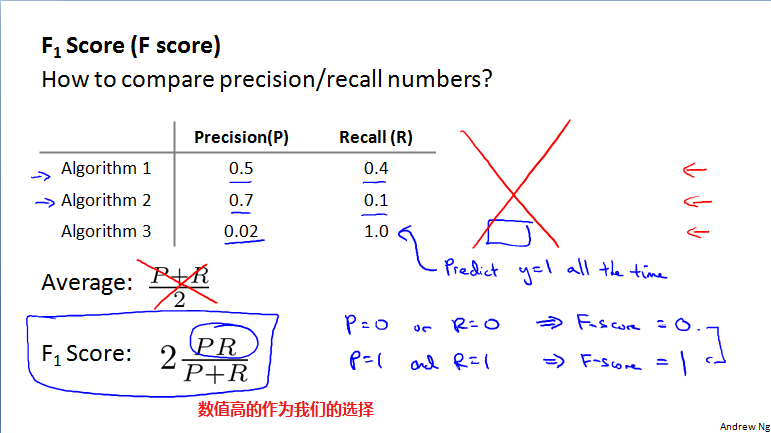
使用F score公式来选择算法的好与不好
机器学习数据(Data for machine learning)
有足够的特征量以及很多类函数,保证低偏差。
有大量的数据,保证低方差。
这两个条件,可以使你得到一个高性能的学习算法。
Andrew总是问自己两个关键测试的问题:
1、当一个专家看到了这些特征量x,他能很有信心的预测出y值吗?
2、我们能获得庞大的训练数据集吗,并用很多参数去训练学习算法?