阅读目录
一、模块和包
模块(module)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(module)。
使用模块有哪些好处?
1、最大的好处就是大大提高了代码的可维护性。
2、编写代码不必从零开始。当一个模块编写完成,就可以被其他地方调用。我们在编写程序的时候,也经常饮用其他模块,包括Python内置的模块和来自第三方的模块。
模块一共分为三种:
1、python标准库
2、第三方模块
3、应用程序自定义模块
注意:
使用模块还可以避免函数名跟变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们在自己编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
二、模块的导入方法
1、import语句
import module1,[module2[,...moduleN]]
当我们使用import语句的时候,Python解释器是怎样找到对应的文件?答案就是解释器有自己的搜索路径,存在sys.path里。
import sys
print(sys.path)
运行结果如下:
['G:\python_s3\day21', 'G:\python_s3', 'C:\Python35\python35.zip', 'C:\Python35\DLLs', 'C:\Python35\lib', 'C:\Python35', 'C:\Python35\lib\site-packages', 'D:\Program Files (x64)\pycharm软件安装\config\PyCharm 2018.3\helpers\pycharm_matplotlib_backend']
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块没屏蔽掉。
2、from...import ...语句
from modname import name1[,name2[, ... nameN]]
这个声明不会把整个modulename模块导入到当前的命名空间中,只会讲它里面的name1或name2单个引入到执行这个声明的模块的全局符号表。
3、from...import*语句
from modname import *
4、运行本质
1、import test
2、from test import add
无论1还是2,首先通过sys.path找到test.py,然后执行test脚本,区别是1会将test这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
5、包(package)
1、如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,成为包(Package)。
举个例子:一个abc.py的文件就是一个名字叫abc的模块,一个simon.py的文件就是一个叫simon的模块。
现在,假设我们的abc和simon这两个模块名字和其他模块起冲突了,于是我们可以通过包来组织模块,从而避免冲突。方法就是选择一个顶层包名:
2、引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
注意点(important)
调用包就是执行包下的__init__.py文件

#1--------------------------------
在node1中import hello是找不到的,有人说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
import sys,os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR) #临时修改
import hello
hello.hello1()
#2、--------------
if __name__=='__main__':
print('ok')
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么"__name__ == '__main__' "是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__.
这个功能还有一个用处:调试代码的时候,在"if __name__ == '__main__' "中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
##-------------cal.py
def add(x,y):
return x+y
##-------------main.py
import cal #from module import cal
def main():
cal.add(1,2)
##--------------bin.py
from module import main
main.main()
注意:
# from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本, # sys.path里有bin.py的当前环境。即/Users/simon/Desktop/whaterver/project/web这层路径, # 无论import what , 解释器都会按这个路径找。所以当执行到main.py时,import cal会找不到,因为 # sys.path里没有/Users/simon/Desktop/whaterver/project/web/module这个路径,而 # from module/. import cal 时,解释器就可以找到了。
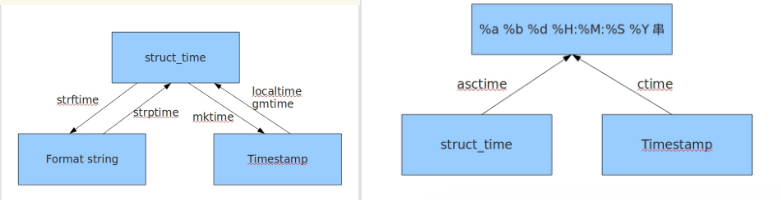
三、time模块(* * * *)
三种时间表示
在Python中,通常有这几种方式来表达时间:
1、时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2、格式化的时间字符串
3、元祖(struct_time):struct_time元祖共有9个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
#1、time(): 返回当前时间的时间戳
print(time.time())
运行结果如下:
C:Python35python3.exe G:/python_s3/day21/example.py
1555996405.5020845
#2、localtime(secs): 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
print(time.localtime())
运行结果如下:
C:Python35python3.exe G:/python_s3/day21/example.py
time.struct_time(tm_year=2019, tm_mon=4, tm_mday=23, tm_hour=13, tm_min=18, tm_sec=9, tm_wday=1, tm_yday=113, tm_isdst=0)
#3、gmtime([secs])和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
print(time.gmtime())
运行结果如下:
C:Python35python3.exe G:/python_s3/day21/example.py
time.struct_time(tm_year=2019, tm_mon=4, tm_mday=23, tm_hour=5, tm_min=21, tm_sec=25, tm_wday=1, tm_yday=113, tm_isdst=0)
#4、mktime(t): 将一个struct_time转化为时间戳
print(time.mktime(time.localtime())) #
运行结果如下:
C:Python35python3.exe G:/python_s3/day21/example.py
1555998160.0
#5、asctime([t]): 把一个表示时间的元祖或者struct_time表示为这种形式:'Tue Apr 23 13:45:49 2019'
#如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())
运行结果如下:
C:Python35python3.exe G:/python_s3/day21/example.py
Tue Apr 23 13:45:49 2019
#6、ctime([secs]): 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) #Tue Apr 23 14:02:45 2019
print(time.ctime(time.time())) #Tue Apr 23 14:03:50 2019
#7、strftime(format[,t]) #把一个代表时间的元祖或者struct_time(如由time.localtime()和time.gmtime()返回) 转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个元素过界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X",time.localtime())) #2019-04-23 14:11:12
#8、time.strptime(string[, format]) #把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2019-04-23 14:15:07', '%Y-%m-%d %X'))
输出结果为:
time.struct_time(tm_year=2019, tm_mon=4, tm_mday=23, tm_hour=14, tm_min=15, tm_sec=7, tm_wday=1, tm_yday=113, tm_isdst=-1)
#在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
#9、sleep(sesc)
print(time.sleep(3)) #线程推迟指定的时间运行,单位为秒。
#10、clock
# 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是"进程时间",它是用秒表示的浮点数(时间戳)。而在windows中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行时间,即两次时间差。
关系图:
四、random模块(* *)
import random
ret=random.random()
# ret=random.randint(1,3) #[1,3]
# ret=random.randrange(1,3) #[1,3]
# ret=random.choice([11,22,33,44,55])
# ret=random.sample([11,22,33,44,55],2)
# ret=random.uniform(1,4)
# print(ret)
# ret=[1,2,3,4,5]
# random.shuffle(ret)
# print(ret)
item=[1,3,5,7,9]
random.shuffle(item)
print(item)
#随机生成验证码
import random
def v_code():
ret=""
for i in range(5):
num=random.randint(0,9)
alf=chr(random.randint(65,122))
s=str(random.choice([num,alf]))
ret+=s
return ret
print(v_code())
五、os模块(* * * *)
os模块是与操作系统交互的接口
os.getcwd() #获取当前工作目录,即当前python脚本的目录路径
os.chdir("dirname") #改变当前脚本工作目录,相当于shell下cd
os.cudir #返回当前目录:(' . ')
os.pardir #获取当前目录的父目录字符串名:(' . . ')
os.makedirs('dirname1/dirname2') #可生成多层递归目录
os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') #生成单级目录,相当于linux中mkdir dirname
os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错,相当于shell中rmdir dirname
os.listdir('dirname') #列出指定目录下的所有文件和子目录,包含隐藏文件,并以列表的方式打印
os.remove() #删除一个文件
os.rename("oldname","newname") #重命名文件/目录
os.stat('path/filename') #获取文件/目录信息
例:
print(os.stat("sss.py"))
C:Python35python3.exe G:/python_s3/day22/os_test.py
os.stat_result(st_mode=33206, st_ino=11821949021847676, st_dev=2159804260, st_nlink=1, st_uid=0, st_gid=0, st_size=10, st_atime=1556025329, st_mtime=1556025329, st_ctime=1556025302)
os.sep #输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep #输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep #输出用于分隔文件路径的字符 win下为; ,Linux下为:
os.name #输出字符串指示当前使用平台。win-->'nt'; Linux-->'posix'
os.system("bash command") #运行shell命令,直接显示
os.environ #获取系统环境变量
例:
print(os.environ)
environ({'FP_NO_HOST_CHECK': 'NO', 'PUBLIC': 'C:\Users\Public', 'PYCHARM': 'D:\Program Files (x64)\pycharm软件安装\config\PyCharm 2018.3\bin;', 'COMPUTERNAME': 'DELL-PC', 'PYTHONPATH': 'G:\python_s3;D:\Program Files (x64)\pycharm软件安装\config\PyCharm 2018.3\helpers\pycharm_matplotlib_backend', 'PYCHARM_HOSTED': '1', 'PYCHARM_MATPLOTLIB_PORT'
os.path.abspath(path) #返回path规范化的绝对路径
os.path.split(path) #将path分割成目录和文件名二元组返回
例:
print(os.path.split(r"G:python_s3day22sss.py"))
输出结果:
('G:\python_s3\day22', 'sss.py')
os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素
例:
print(os.path.dirname(r"G:python_s3day22sss.py"))
输出结果:
G:python_s3day22
os.path.basename(path) #返回path最后的文件名,如果path以/ 或 结尾,那么就会返回空值。即os.path.split(path) 的第二个元素
例:
print(os.path.basename(r"G:python_s3day22sss.py"))
输出结果:
sss.py
os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) #如果path是绝对路径,返回True
os.path.isfile(path) #如果path是一个存在的文件,返回True,否则返回False
os.path.isdir(path) #如果path是一个存在的目录,则返回True,否则返回False
os.path.join(path1,paht2[, ...]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
例:
a="G:python_s3day22"
b="sss.py"
print(os.path.join(a,b))
输出结果:
G:python_s3day22sss.py
os.path.getatime(paht) #返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
六、sys模块(* * *)
#1、sys.argv 命令行参数List,第一个元素是程序本身路径 #2、sys.exit(n) 退出程序,正常退出时exit(0) #3、sys.version 获取Python解释程序的版本信息 #4、sys.maxint 最大的Int值 #5、sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 #6、sys.platform 返回操作系统平台名称
#7、sys.stdout.write("please:") #标准输出,引出进度条的例子,注意,在py3上不行,可以用print代替
#8、sys.stdout.flush() #刷新缓存
##进度条
import time,sys
for i in range(10):
sys.stdout.write('#')
time.sleep(1)
sys.stdout.flush()
输出结果:
C:Python35python3.exe G:/python_s3/day22/sys_test.py
##########
七、json&pickle模块(* * * *)
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
用于序列化的两个模块
● json,用于任何语言 和 python数据类型间进行转换
● pickle,用于python特有的类型 和 python的数据类型间进行转换
dic='{"name":"simon"}'
f=open('hello','w')
f.write(dic)
f_read=open('hello','r')
data=f_read.read()
print(type(data)) #读到的文件内容是字符串<class 'str'>
data=eval(data) #将字符串转成字典
print(data['name']) #读取字典name对应的值
输出结果为:
C:Python35python3.exe G:/python_s3/day22/json&pickle.py
<class 'str'>
simon
1、什么是序列化?
我们把对象(变量)从内存中变成可储存或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也称之为serialization,marshalling,flattening等。
序列化之后,就可以把序列化后的内容写到磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpicking。
2、json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便的存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
| JSON类型 | Python类型 |
| {} | dict |
| [] | list |
| "string" | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
#1、通过eval处理,只能讲字符串转成字典
dic='{"name":"simon"}'
# f=open('hello','w')
# f.write(dic)
f=open('hello','r')
data=f.read()
print(type(data)) #读到的文件内容是字符串<class 'str'>
data=eval(data) ##将字符串转成字典
print(data["name"]) #读取字典name对应的值
打印:
<class 'str'>
simon
#2、通过json模块处理python字典
import json
dic={"name":"simon"} #----------->{"name":"simon"}-------'{"name":"simon"}'
dic_str=json.dumps(dic)
print(dic_str) #{"name": "simon"}
print(type(dic_str)) #<class 'str'>
f=json.loads(dic_str) #将json字符串通过loads转成字典的过程
print(f) #{'name': 'simon'}
print(type(f)) #<class 'dict'>
print(f["name"]) #simon
打印:
{"name": "simon"}
<class 'str'>
{'name': 'simon'}
<class 'dict'>
simon
#2、通过json模块处理python数字
i=8
i=json.dumps(i) #无论是字典、字符串、列表、整型,json.dumps都会把无论是单引号还是双引号多会转成双引号,然后加单引号变成json字符串
print(i)
p=json.loads(i)
print(type(p))
打印:
8
<class 'str'>
<class 'int'>
#3、通过json模块处理字符串
s='hello' #----------->"hello"----------->'"hello"',json.dumps都会把无论是单引号还是双引号都会转成双引号,然后加单引号变成json字符串
s=json.dumps(s)
print(s)
p=json.loads(s) #通过json.loads将dumps后的json字符串转为json支持的数据类型
print(p)
print(type(p))
打印:
"hello"
hello
<class 'str'>
#4、通过json模块处理列表
l=[1,2,3] #----------->"[1,2,3]"
l=json.dumps(l)
print(l)
print(type(l))
p=json.loads(l)
print(p) #转成json的列表类型
print(type(p))
打印:
[1, 2, 3]
<class 'str'>
[1, 2, 3] #处理后的json列表
<class 'list'>
#5、对于文件的操作dumps方法可以用dump替代
f_read=open("new_hello","r")
data=json.loads(f_read.read()) #等价于data=json.load(f_read)
print(data)
print(type(data))
print(data["name"])
#注意点: import json #dct="{'1':111}"#json 不认单引号 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}' print(json.loads(dct)) #conclusion: # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads 注意点
3、pickle
#--------------------pickle------------------
import pickle
dic={'name':'william','age':24,'sex':'male'}
print(type(dic)) #<class 'dict'>
j=pickle.dumps(dic)
print(type(j)) #<class 'bytes'>
f = open('序列化对象_pickle','wb') #注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #------------------------等价于pickle.dump(dic,f)
# pickle.dump(dic,f)
f.close()
#----------------------------反序列化
f = open('序列化对象_pickle','rb')
data = pickle.loads(f.read()) #等价于data=pickle.load(f)
print(data['age']) #24
pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且不同于其他版本的python彼此版本不兼容,因此,只能用pickle保存那些不重要的数据,不能成功地反序列化也没关系。
八、shelve模块(* * *)
import shelve
f = shelve.open(r'shelve') #目的:将一个字典放入文本 f={}
# f['stu1_info']={'name':'simon','age':'18'}
# f['stu2_info']={'name':'simonn','age':'20'}
# f['school_info']={'website':'baidu.com','city':'beijing'}
#
#
# f.close()
print(f.get('stu1_info')['age']) #18
九、xml模块(* * *)
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
自己创建xml文档:
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
十、re模块(* * * * *)
1、什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在python中)它内嵌在Python中,并通过re模块实现。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1、普通字符:大多数字符和字母都会和自身匹配
>>> re.findall("zhurui","FREWRFVZHURzhuruiSIMONsimon")
['zhurui']
>>>
2、元字符:. ^ $ * + ? {} [] | ()

1、元字符之( . ^ $ * + ? { } )
import re
ret=re.findall('si..n','qwerwrsimonreorerge') #['simon']
print(ret)
ret=re.findall('^s...n','simonreorserpnerge') #['simon']
print(ret)
ret=re.findall('s...n','simonreorserpnerge') #['simon', 'serpn']
print(ret)
ret=re.findall('s...n$','simonreorserpnergesrren') #['srren']
print(ret)
ret=re.findall('^s*','sssasdfgdsjjuresssss') #['sss'],*:表示0到无穷次 +:表示1到无穷次
print(ret)
ret=re.findall('alex*','asdfhfalexxx') #
print(ret) #['alexxx']
ret=re.findall('alex+','asdfhfalexxx') #[1,+oo]
print(ret) #['alexxx']
ret=re.findall('alex*','asdfhfale') #['ale']
print(ret)
ret=re.findall('alex+','asdfhfale') #[]
print(ret)
ret=re.findall('simon?','asdhfsimonnn') #[0,1],?:表示匹配0到1个
print(ret) #['simon']
ret=re.findall('simon{1,3}','asdhfsimonnnnnn') #['simonnn'] 贪婪匹配
print(ret)
注意:前面*,+,?等都是贪婪匹配,也就是尽可能多匹配,后面加?号使其变成惰性匹配
ret=re.findall('abc*?','abcccccc')
print(ret) #['ab']
2、元字符之字符集[ ]:
##---------------------------字符集[]
ret=re.findall('www[simon baidu]','wwwbaidu')
print(ret)
ret=re.findall('x[yz]','xyuuuu')
print(ret)
ret=re.findall('x[yz]','xyuuxzuu') #['xy', 'xz']
print(ret)
ret=re.findall('x[yz]p','xypuuxzpuu') #['xyp', 'xzp']
print(ret)
ret=re.findall('x[y,z]p','xypuuxzpux,pu') #['xyp', 'xzp', 'x,p']
print(ret)
ret=re.findall('q[a*z]','xypuuxzpqaa') #['qa']
print(ret)
ret=re.findall('q[a-z]*','quouuiuni') #['quouuiuni']
print(ret)
ret=re.findall('q[a-z]*','quouuiuni9') #['quouuiuni']
print(ret)
ret=re.findall('q[0-9]*','q8910uouuiuni9') #['q8910']
print(ret)
ret=re.findall('q[0-9]*','q8910uouuiuniq9') #['q8910', 'q9']
print(ret)
ret=re.findall('q[^a-z]*','q821') #['q821']
print(ret)
3、元字符之转义符
反斜杠后边跟元字符去除特殊功能,比如.
反斜杠后边跟普通字符实现特殊功能,比如d
d 匹配任何十进制数;它相当于类 [0-9]。
D 匹配任何非数字字符;它相当于类 [^0-9]。
s 匹配任何空白字符;它相当于类 [
fv]。
S 匹配任何非空白字符;它相当于类 [^
fv]。
w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
匹配一个特殊字符边界,比如空格 ,&,#等
import re
print(re.findall("^I","hello I am LIST"))
print(re.findall(r"I","hello I am LIST")) #['I']
print(re.findall("I\b","hello I am LIST")) #['I']
print(re.findall(r"c\l","abclerwt")) #['c\l']
print(re.findall("c\\l","abclerwt")) #['c\l']
4、元字符之分组()
m = re.findall(r'(ad)+','add')
print(m)
ret=re.search('(?P<id>d{2})/(?P<name>w{3})','23/com')
print(ret.group()) # 23/com
print(ret.group('id')) #23
ret=re.search("(?P<name>[a-z]+)d+","123simon27zhurui24william45").group()
print(ret) #simon27
ret=re.search("(?P<name>[a-z]+)d+","123simon27zhurui24william45").group('name')
print(ret) #simon
ret=re.search("(?P<name>[a-z]+)(?P<age>d+)","123simon27zhurui24william45").group('age') #.group是固定格式
print(ret) #27
5、元字符之 |
ret=re.search('(ab)|d','rabhdg8sdgrui') #ab
print(ret.group())
6、re模块下的常用方法
import re
#方法1
print(re.findall("s","simon zhu")) #['s'],返回所有满足匹配条件的结果,放在列表里
#方法2
ret=re.search("(?P<name>[a-z]+)(?P<age>d+)","123simon27zhurui24william45").group('age') #函数会在字符串内查找模式匹配,只找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None
print(ret) #27
#方法3
print(re.match("d+","23simon24zhurui23will78")) #同search,不过尽在字符串开始处进行匹配
#方法4
ret=re.split("[ab]","abcd") #先按'a'分割得到' ' 和'bcd',在对' '和'bcd'分别按'b'分割
print(ret) #['', '', 'cd']
#方法5
ret=re.sub('d','abc','simon7zhurui9',1)
print(ret) #simonabczhurui9
ret=re.subn('d','abc','alvin5yuan6')
print(ret)#('alvinabcyuanabc', 2)
#方法6
obj=re.compile('d{3}')
ret=obj.search('abc123eeee')
print(ret.group())#123
ret=re.finditer('d','ds3sy4784a')
print(ret) #<callable_iterator object at 0x10195f940>
print(next(ret).group())
print(next(ret).group())
注意:
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret)#['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret)#['www.oldboy.com']
ret=re.findall("www.(baidu|163).com","fddsfsfdwww.baidu.comrerggetbbvfd")
print(ret) #['baidu']
ret=re.findall("www.(?:baidu|163).com","fddsfsfdwww.baidu.comrerggetbbvfd")
print(ret) #['www.baidu.com']
补充:
import re
print(re.findall("<(?P<tag_name>w+)>w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search("<(?P<tag_name>w+)>w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search(r"<(w+)>w+</1>","<h1>hello</h1>"))
补充2:
#匹配出所有的整数
import re
#ret=re.findall(r"d+{0}]","1-2*(60+(-40.35/5)-(-4*3))")
ret=re.findall(r"-?d+.d*|(-?d+)","1-2*(60+(-40.35/5)-(-4*3))")
ret.remove("")
print(ret)