
系列
- 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本
- 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps
- Sentry For React 完整接入详解
- Sentry For Vue 完整接入详解
- Sentry-CLI 使用详解
- Sentry Web 性能监控 - Web Vitals
- Sentry Web 性能监控 - Metrics
- Sentry Web 性能监控 - Trends
- Sentry Web 前端监控 - 最佳实践(官方教程)
- Sentry 后端监控 - 最佳实践(官方教程)
- Sentry 监控 - Discover 大数据查询分析引擎
- Sentry 监控 - Dashboards 数据可视化大屏
- Sentry 监控 - Environments 区分不同部署环境的事件数据
- Sentry 监控 - Security Policy 安全策略报告
- Sentry 监控 - Search 搜索查询实战
- Sentry 监控 - Alerts 告警
- Sentry 监控 - Distributed Tracing 分布式跟踪
- Sentry 监控 - 面向全栈开发人员的分布式跟踪 101 系列教程(一)
Snuba 是一种在 Clickhouse 之上提供丰富数据模型以及快速摄取消费者(直接从 Kafka 获取数据)和查询优化器的服务。
Snuba 最初的开发目的是取代 Postgres 和 Redis 的组合,以搜索和提供有关 Sentry 错误的聚合数据。从那时起,它已经演变成目前的形式,在多个数据集上支持大多数与时间序列相关的 Sentry 功能。
功能
- 为
Clickhouse分布式数据存储提供数据库访问层。 - 提供一个图形逻辑数据模型,客户端可以通过
SnQL语言查询,该语言提供类似于SQL的功能。 - 在单个安装中支持多个单独的数据集。
- 提供基于规则的查询优化器。
- 提供一个迁移系统,将
DDL更改应用于单节点和分布式环境中的Clickhouse。 - 直接从
Kafka摄取数据 - 支持时间点查询和流式查询。
Sentry 中的一些用例:
events数据集为Issue Page等功能提供支持。此处的搜索功能由Snuba以及所有聚合(aggregation)函数提供支持。discover数据集为所有性能监控(Performance Monitoring)相关功能提供支持。sessions数据集为发布(Releases)功能提供支持。 具体来说,该数据集会摄取大量数据点并存储预先聚合的数据,以允许对大量数据进行快速查询。outcomes数据集为统计页面(Stats page)提供支持。
开始使用 Snuba
这是在 Sentry 开发环境中快速启动 Snuba 的指南。
必要条件
Snuba 假设如下:
- 一个
Clickhouse服务器端点位于CLICKHOUSE_HOST(默认localhost)。 - 在
REDIS_HOST(默认localhost)上运行的redis实例。在端口6379上。
让这些服务运行的快速方法是设置 sentry,然后使用:
sentry devservices up --exclude=snuba
请注意,Snuba 假设一切都在 UTC 时间运行。否则,您可能会遇到时区不匹配的问题。
Sentry + Snuba
在 ~/.sentry/sentry.conf.py 中添加/更改以下几行:
SENTRY_SEARCH = 'sentry.search.snuba.EventsDatasetSnubaSearchBackend'
SENTRY_TSDB = 'sentry.tsdb.redissnuba.RedisSnubaTSDB'
SENTRY_EVENTSTREAM = 'sentry.eventstream.snuba.SnubaEventStream'
运行:
sentry devservices up
访问原始 clickhouse client(类似于 psql):
docker exec -it sentry_clickhouse clickhouse-client
数据写入表 sentry_local: select count() from sentry_local;
设置
设置可以在 settings.py 中找到
CLUSTERS:提供集群列表以及应该在每个集群上运行的主机名(hostname)、端口(port)和存储集(storage sets)。每个集群也设置了本地与分布式(Local vs distributed)。REDIS_HOST:redis正在运行此处。
Snuba 架构概述
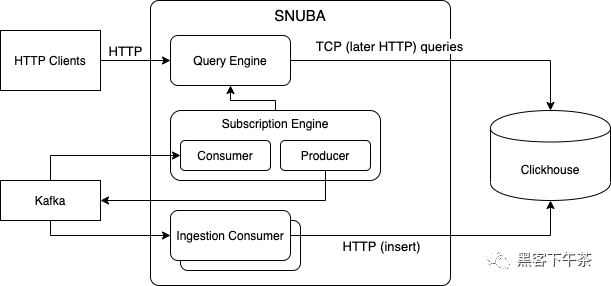
Snuba 是一个由 Clickhouse 支持的面向时间序列的数据存储服务,它是一个列式存储分布式数据库,非常适合 Snuba 服务的查询类型。
数据完全存储在 Clickhouse 表和物化(materialized)视图中,它通过输入流(目前只有 Kafka topic)摄取,并且可以通过时间点查询或流式查询(subscriptions)进行查询。
存储
之所以选择 Clickhouse 作为后备存储,是因为它在 Snuba 需要的实时性能、分布式和复制性质、存储引擎方面的灵活性和一致性保证之间提供了良好的平衡。
Snuba 数据存储在 Clickhouse 表和 Clickhouse 物化视图(materialized views)中。根据表的目标使用多个 Clickhouse 存储引擎。
Snuba 数据组织在多个数据集中,这些数据集表示数据模型的独立分区。更多细节见 Snuba 数据模型部分。
摄取
Snuba 不提供用于插入行的 api 端点(除非在调试模式下运行)。 数据从多个输入流加载,由一系列消费者处理并写入 Clickhouse 表。
一个 consumer 消费一个或多个 topic 并写入一个或多个表。到目前为止,还没有多个消费者写入表。 这允许下面讨论的一些一致性保证。
数据摄取(Data ingestion)在批处理中最有效(对于 Kafka 但尤其是对于 Clickhouse)。 我们的 consumer 支持批处理并保证从 Kafka 获取的一批事件至少传递给 Clickhouse 一次。通过正确选择 Clickhouse 表引擎对行进行重复数据删除,如果我们接受最终一致性,我们可以实现恰好一次语义。
查询
最简单的查询系统是时间点。查询以 SnQL 语言(SnQL 查询语言)表示,并作为 HTTP post 调用发送。 查询引擎处理查询(Snuba 查询处理中描述的过程)并将其转换为 ClickHouse 查询。
流式查询(通过订阅引擎完成)允许客户端以推送方式接收查询结果。在这种情况下,HTTP 端点允许客户端注册流查询。然后订阅 Consumer 消费到用于填充相关 Clickhouse 表以进行更新的 topic,通过查询引擎定期运行查询并在订阅 Kafka topic 上生成结果。
数据一致性
不同的一致性模型在 Snuba 中并存以提供不同的保证。
默认情况下,Snuba 是最终一致的。 运行查询时,默认情况下,不能保证单调读取(monotonic reads),因为 Clickhouse 是多领导者(multi-leader),查询可以命中任何副本,并且不能保证副本是最新的。此外,默认情况下,不能保证 Clickhouse 会自行达到一致状态。
通过强制 Clickhouse 在执行查询之前达到一致性(FINAL keyword),并强制查询命中 consumer 写入的特定副本,可以在特定查询上实现强一致性。这本质上使用 Clickhouse,就好像它是一个单一的领导系统(single leader system),它允许顺序一致性(Sequential consistency)。
Sentry 部署中的 Snuba
本节解释了 Snuba 在展示主要数据流的 Sentry 部署中扮演的角色。如果您单独部署 Snuba,这对您没有用处。

Errors 和 Transactions 数据流
图表顶部的主要部分说明了 Events 和 Transactions 实体的摄取过程。这两个实体为 Sentry 和整个 Performance 产品中的大多数问题/错误(issue/errors)相关功能提供服务。
只有一个 Kafka topic(events)在 errors 和 transactions 之间共享,为这条管道提供信息。此 topic 包含 error 消息和 transaction 消息。
Errors consumers 使用 events topic,在 Clickhouse errors 表中写入消息。提交后,它还会生成关于 snuba-commit-log topic 的记录。
错误警报由 Errors Subscription Consumer 生成。这是同步消费者(synchronized consumer),它同时消费主 events topic 和 snuba-commit-log topic,因此它可以与主 consumer 同步进行。
synchronized consumer 然后通过查询 Clickhouse 生成警报,并在 result topic 上生成结果。
transactions 存在于一个相同但独立的管道。
Errors 管道还有一个额外的步骤:写入 replacements topic。Sentry 在 events topic 上产生 Errors mutations(合并/取消合并/再处理/等等)。然后,Errors Consumer 将它们转发到 replacements topic,并由 Replacement Consumer 执行。
events topic 必须按 Sentry project id 在语义上进行分区,以允许按顺序处理项目中的事件。 目前为止,这是 alerts 和 replacements 的要求。
Sessions 与 Outcomes
Sessions 和 Outcomes 以非常相似和更简单的方式工作。特别是 Sessions 增强 Release Health 功能,而 Outcomes 主要向 Sentry 统计页面提供数据。
两个管道都有自己的 Kafka topic,Kafka consumer,它们在 Clickhouse 中写自己的表。
变更数据捕获管道
这条管道仍在建设中。它使用 cdc topic 并填充 Clickhouse 中的两个独立表。