
Linkerd 提供了许多功能,如:自动 mTLS、自动代理注入、分布式追踪、故障注入、高可用性、HTTP/2 和 gRPC 代理、负载均衡、多集群通信、重试和超时、遥测和监控、流量拆分(金丝雀、蓝/绿部署)等。
Linkerd 2.10 中文手册持续修正更新中:
Linkerd 2.10 系列
功能概述
自动 mTLS:Linkerd 自动为网格应用程序之间的所有通信启用相互传输层安全性 (TLS)。自动代理注入:Linkerd 会自动将数据平面代理注入到基于 annotations 的 pod 中。容器网络接口插件:Linkerd 能被配置去运行一个 CNI 插件,该插件自动重写每个 pod 的 iptables 规则。仪表板和 Grafana:Linkerd 提供了一个 Web 仪表板,以及预配置的 Grafana 仪表板。分布式追踪:您可以在 Linkerd 中启用分布式跟踪支持。故障注入:Linkerd 提供了以编程方式将故障注入服务的机制。高可用性:Linkerd 控制平面可以在高可用性 (HA) 模式下运行。HTTP、HTTP/2 和 gRPC 代理:Linkerd 将自动为 HTTP、HTTP/2 和 gRPC 连接启用高级功能(包括指标、负载平衡、重试等)。Ingress:Linkerd 可以与您选择的 ingress controller 一起工作。负载均衡:Linkerd 会自动对 HTTP、HTTP/2 和 gRPC 连接上所有目标端点的请求进行负载平衡。多集群通信:Linkerd 可以透明且安全地连接运行在不同集群中的服务。重试和超时:Linkerd 可以执行特定于服务的重试和超时。服务配置文件:Linkerd 的服务配置文件支持每条路由指标以及重试和超时。TCP 代理和协议检测:Linkerd 能够代理所有 TCP 流量,包括 TLS 连接、WebSockets 和 HTTP 隧道。遥测和监控:Linkerd 会自动从所有通过它发送流量的服务收集指标。流量拆分(金丝雀、蓝/绿部署):Linkerd 可以动态地将一部分流量发送到不同的服务。
HTTP、HTTP/2 和 gRPC 代理
Linkerd 可以代理所有 TCP 连接,并将自动为 HTTP、HTTP/2 和 gRPC 连接
启用高级功能(包括指标、负载平衡、重试等)。
- 由于早期版本中的 bug,使用 grpc-go 的 gRPC 应用程序必须使用 1.3 或更高版本。
- 由于早期版本中的 bug,使用 @grpc/grpc-js 的 gRPC 应用程序必须使用 1.1.0 或更高版本。
TCP 代理和协议检测
Linkerd 能够代理所有 TCP 流量,包括 TLS 连接、WebSockets 和 HTTP 隧道。
大多数情况下,Linkerd 无需配置即可完成此操作。
为此,Linkerd 执行 protocol detection(协议检测) 以确定
流量是 HTTP 还是 HTTP/2(包括 gRPC)。如果 Linkerd 检测到连接
是 HTTP 或 HTTP/2,Linkerd 将自动提供 HTTP 级别的指标(metrics)和路由(routing)。
如果 Linkerd 不能确定连接是使用 HTTP 还是 HTTP/2,
Linkerd 会将连接代理为普通 TCP 连接,
应用 mTLS 并像往常一样提供字节级指标(byte-level metrics)。
客户端启动的 HTTPS(Client-initiated HTTPS) 将被视为 TCP,而不是 HTTP,
因为 Linkerd 将无法观察连接上的 HTTP 事务。
配置协议检测
在某些情况下,Linkerd 的协议检测无法运行,
因为它没有提供足够的客户端数据。
这可能会导致创建连接延迟 10 秒,
因为协议检测代码会等待更多数据。
在使用“服务器优先(server-speaks-first)”协议或服务器
在客户端发送数据之前发送数据的协议时,经常会遇到这种情况 ,
可以通过为 Linkerd 提供一些额外的配置来避免。
不管底层协议是什么,客户端发起的 TLS 连接不需要任何额外的配置,
因为 TLS 本身是一个客户端优先协议(client-speaks-first)。
配置协议检测有两种基本机制:
不透明端口(opaque ports)和跳过端口(skip ports)。
将端口标记为不透明(opaque)会指示 Linkerd 将连接代理为 TCP 流,而不是尝试协议检测。
将端口标记为跳过(skip)会完全绕过代理。
不透明端口通常是首选(因为 Linkerd 可以提供 mTLS、TCP 级别的指标等),
但至关重要的是,不透明端口只能用于集群内部的服务。
默认情况下,Linkerd 会自动将一些端口标记为不透明,
包括 SMTP、MySQL、PostgresQL 和 Memcache 的默认端口。
使用这些协议、使用默认端口且位于集群内部的服务不需要进一步配置。
下表总结了一些常见的 server-speaks-first 协议以及处理它们所需的配置。
“on-cluster config” 列指的是 destination 在同一个集群时的配置;
当目的地在集群外部时,“集群外配置(off-cluster config)”。
| Protocol | Default port(s) | On-cluster config | Off-cluster config |
|---|---|---|---|
| SMTP | 25, 587 | none* | skip ports |
| MySQL | 3306 | none* | skip ports |
| MySQL with Galera replication | 3306, 4444, 4567, 4568 | opaque ports for 3306, 4444; and skip ports for 4567, 4568 | skip ports |
| PostgreSQL | 5432 | none* | skip ports |
| Redis | 6379 | opaque ports | skip ports |
| ElasticSearch | 9300 | opaque ports | skip ports |
| Memcache | 11211 | none* | skip ports |
* 如果使用标准端口,则无需配置。如果使用非标准端口,则必须将该端口标记为不透明(opaque)。
将端口标记为不透明
您可以使用 config.linkerd.io/opaque-ports 注释将端口标记为不透明。
这指示 Linkerd 跳过该端口的协议检测。
可以在工作负载(workload)、服务(service)或
命名空间(namespace)上设置此注释。
在工作负载上设置它会告诉该工作负载的
被 mesh 的客户端(meshed clients)跳过与工作负载建立的连接的协议检测,
并告诉 Linkerd 在反向代理(reverse-proxying)传入连接时跳过协议检测。
在服务上设置它会告诉被 mesh 的客户端(meshed clients)在代理连接到服务时跳过协议检测。
在命名空间上设置它会将此行为应用于该命名空间中的所有服务和工作负载。
由于此 annotation 通知被 mesh 的 clients 的行为,
因此它可以应用于使用服务器优先(server-speaks-first)协议的服务,即使服务本身没有被网格。
可以在运行 linkerd inject 时使用 --opaque-ports 标志来
设置 opaque-ports annotation。
例如,对于运行在集群上的 MySQL 数据库使用
非标准端口 4406,您可以使用以下命令:
linkerd inject mysql-deployment.yml --opaque-ports=4406
| kubectl apply -f -
linkerd inject mysql-service.yml --opaque-ports=4406
| kubectl apply -f -
可以以逗号分隔的字符串形式提供多个端口。
您提供的值将替换而不是增加不透明端口的默认列表。
跳过代理
有时需要完全绕过代理。例如,当连接到集群外的 server-speaks-first 目的地时,
没有可以设置 config.linkerd.io/opaque-ports annotation 的服务资源。
在这种情况下,您可以在运行 linkerd inject 时
使用 --skip-outbound-ports 标志来配置资源以在
发送到这些端口时完全绕过代理。(类似地,--skip-inbound-ports 标志将
配置资源以绕过代理以连接到这些端口的传入连接。)
跳过代理对于这些情况以及诊断问题很有用,但除此之外几乎没有必要。
与不透明端口一样,可以以逗号分隔的字符串形式提供多个跳过端口。
重试和超时
自动重试是服务网格用于优雅地处理部分或瞬时应用程序故障的最强大和最有用的机制之一。
如果实施不当,重试可能会将小错误放大为系统范围的中断。
出于这个原因,我们确保它们的实施方式可以提高系统的可靠性,同时限制风险。
超时与重试密切相关。一旦请求被重试一定次数,
限制客户端在完全放弃之前等待的总时间就变得很重要。
想象多次重试迫使客户端等待 10 秒。
服务配置文件可以将某些路由定义为可重试或指定路由超时。
这将导致 Linkerd 代理在调用该服务时执行适当的重试或超时。
重试和超时总是在 outbound (client) 端执行。
如果使用无头服务(headless services),则无法检索服务配置文件(service profiles)。
Linkerd 根据目标 IP 地址读取服务发现信息,
如果这恰好是 pod IP 地址,则它无法判断 pod 属于哪个服务。
重试如何出错
传统上,在执行重试时,您必须在放弃之前指定最大重试次数。
不幸的是,以这种方式配置重试有两个主要问题。
选择最大重试次数是一个猜谜游戏
你需要选择一个足够高的数字来产生影响;
允许多次重试通常是谨慎的,如果您的服务不太可靠,您可能希望允许多次重试。
另一方面,允许过多的重试尝试会在系统上产生大量额外的请求和额外的负载。
执行大量重试也会严重增加需要重试的请求的延迟。
在实践中,您通常会从一顶帽子中选择一个最大的重试次数(3?),
然后通过反复试验来调整它,直到系统大致按照您希望的方式运行。
以这种方式配置的系统容易受到重试风暴的攻击
当一项服务启动(出于任何原因)遇到比正常故障率更高的故障率时,
retry storm 就开始了。
这会导致其客户端重试那些失败的请求。
重试带来的额外负载会导致服务进一步减慢速度并导致更多请求失败,
从而触发更多重试。如果将每个客户端配置为最多重试 3 次,
则发送的请求数量可能会增加四倍!更糟糕的是,
如果任何客户端的客户端配置了重试,重试次数就会成倍增加,
并且可以将少量错误变成自我造成的拒绝服务攻击。
重试预算来救援
为了避免重试风暴和任意重试次数的问题,使用重试预算配置重试。
Linkerd 不是为每个请求指定固定的最大重试次数,
而是跟踪常规请求和重试之间的比率,并将此数量保持在可配置的限制以下。
例如,您可以指定您希望重试最多增加 20% 的请求。
Linkerd 将在保持该比率的同时尽可能多地重试。
配置重试总是在提高成功率和不给系统增加太多额外负载之间进行权衡。
重试预算通过让您指定系统愿意从重试中接受多少额外负载来明确权衡。
自动 mTLS
默认情况下,Linkerd 通过在 Linkerd 代理之间建立和验证安全的私有 TLS 连接,
为网状 Pod 之间的大多数 TCP 流量自动启用相互传输层安全性 (mTLS)。
这意味着 Linkerd 可以向您的应用程序添加经过身份验证的加密通信,
而您只需做很少的工作。由于 Linkerd 控制平面也在数据平面上运行,
这意味着 Linkerd 控制平面组件之间的通信也通过 mTLS 自动保护。
它是如何工作的?
简而言之,Linkerd 的控制平面向代理颁发 TLS 证书,
这些证书的范围限定为包含 Pod 的
Kubernetes ServiceAccount,
并每 24 小时自动轮换一次。代理使用这些证书来加密和验证到其他代理的 TCP 流量。
为此,Linkerd 在集群中维护了一组凭据:信任锚(trust anchor)、
颁发者证书(issuer certificate)和私钥(private key)。
这些凭据在安装时由 Linkerd 本身生成,或者由外部源
(例如 Vault 或
cert-manager。
颁发者证书和私钥放置在
Kubernetes Secret 中。
默认情况下,Secret 放置在 linkerd 命名空间中,
并且只能由 Linkerd 控制平面 的 identity 组件使用的服务帐户读取。
在数据平面方面,每个代理都在环境变量中传递信任锚(trust anchor)。
在启动时,代理会生成一个私钥,
存储在
tmpfs emptyDir
中,该私钥留在内存中并且永远不会离开 pod。
代理连接到控制平面的身份(identity)组件,验证与信任锚的身份(identity)连接,
并发出证书签名请求 (CSR)。
CSR 包含一个初始证书,其身份设置为 pod 的
Kubernetes ServiceAccount,
以及实际的服务帐户令牌,以便该身份可以验证 CSR 是否有效。
验证后,签名的信任包将返回给代理,代理可以将其用作客户端和服务器证书。
这些证书的范围为 24 小时,并使用相同的机制动态刷新。
当注入 Pod 的代理从应用程序容器接收到出站连接时,
它会通过使用 Linkerd 控制平面查找该 IP 地址来执行服务发现。
当目的地在 Kubernetes 集群中时,控制平面为代理提供目的地的端点地址以及元数据。
当身份名称包含在此元数据中时,这向代理表明它可以启动双向 TLS。
当代理连接到目标时,它会发起 TLS 握手,验证目标代理的证书是否已针对预期的身份名称进行签名。
维护
linkerd install 生成的信任锚在 365 天后过期,
必须手动轮换。
或者,您可以自己提供信任锚并控制到期日期。
默认情况下,颁发者证书和密钥不会自动轮换。
您可以使用 cert-manager 设置自动轮换。
注意事项和未来工作
Linkeder 自动加密和验证集群中所有通信的能力存在一些已知的缺陷。
这些缺口将在以后的版本中修复:
-
Linkerd 目前不强制执行 mTLS。网格内的任何未加密请求都将随机升级到 mTLS。
Linkerd 不会自动对来自网格内部或外部的任何请求进行 mTLS。
这将在未来的 Linkerd 版本中解决,可能作为选择加入行为,
因为它可能会破坏一些现有的应用程序。 -
理想情况下,Linkerd 使用的 ServiceAccount 令牌不会
与该令牌的其他潜在用途共享。
在未来的 Kubernetes 版本中,Kubernetes 将
支持 audience/time-bound 的 ServiceAccount 令牌,
Linkerd 将使用这些令牌。
Ingress
为简单起见,Linkerd 没有提供自己的 ingress controller。
相反,Linkerd 旨在与您选择的 ingress controller 一起工作。
遥测和监控
Linkerd 最强大的功能之一是其围绕可观察性(observability)的广泛工具集—
在网格应用程序中测量和报告观察到的行为。
虽然 Linkerd 没有直接洞察服务代码的内部结构,
但它对服务代码的外部行为有着巨大的洞察力。
要访问 Linkerd 的可观察性功能,您只需要安装 Viz 扩展:
linkerd viz install | kubectl apply -f -
Linkerd 的遥测和监控功能会自动运行,无需开发人员进行任何工作。这些功能包括:
- 记录 HTTP、HTTP/2 和 gRPC 流量的顶级(“黄金”)指标(请求量、成功率和延迟分布)。
- 记录其他 TCP 流量的 TCP 级别指标(输入/输出字节等)。
- 报告每个服务、每个调用方(caller)/被调用方(callee)对或每个路由/路径(使用服务配置文件)的指标。
- 生成拓扑图,显示服务之间的运行时关系。
- 实时、按需请求采样。
可以通过多种方式使用这些数据:
- 通过 Linkerd CLI,
例如:使用linkerd viz stat和linkerd viz routes。 - 通过 Linkerd dashboard 和 pre-built Grafana dashboards。
- 直接来自 Linkerd 的内置 Prometheus 实例
黄金指标
成功率
这是一个时间窗口(默认为 1 分钟)内成功请求的百分比。
在命令 linkerd viz routes -o wide 的输出中,
此度量分为 EFFECTIVE_SUCCESS 和 ACTUAL_SUCCESS。
对于配置了重试的路由,前者计算重试后的成功百分比(客户端感知),
后者计算重试前的成功率(可能暴露服务的潜在问题)。
流量(每秒请求数)
这概述了对 service/route 的需求量。
与成功率一样,linkerd viz routes --o wide 将此指标
拆分为 EFFECTIVE_RPS 和 ACTUAL_RPS,分别对应于重试前后的比率。
延迟
每个 service/route 的服务请求所花费的时间分为第 50、95 和 99 个百分位数。
较低的百分位数可让您大致了解系统的平均性能,而尾部百分位数有助于捕捉异常行为。
Linkerd 指标的生命周期
Linkerd 并非设计为长期历史指标存储。
虽然 Linkerd 的 Viz 扩展确实包含一个 Prometheus 实例,
但该实例会在很短的固定时间间隔(目前为 6 小时)内使指标过期。
相反,Linkerd 旨在补充(supplement)您现有的指标存储。
如果 Linkerd 的指标有价值,您应该将它们导出到您现有的历史指标存储中。
负载均衡
对于 HTTP、HTTP/2 和 gRPC 连接,
Linkerd 会自动在所有目标端点之间对请求进行负载平衡,无需任何配置。
(对于 TCP 连接,Linkerd 会平衡连接。)
Linkerd 使用一种称为 EWMA 或
指数加权移动平均(exponentially weighted moving average)的算法来自动将请求发送到最快的端点。
这种负载平衡可以改善端到端(end-to-end)延迟。
服务发现
对于不在 Kubernetes 中的目的地,Linkerd 将在 DNS 提供的端点之间进行平衡。
对于 Kubernetes 中的目的地,Linkerd 将在 Kubernetes API 中查找 IP 地址。
如果 IP 地址对应于一个服务,Linkerd 将在该服务的端点之间进行负载平衡,
并应用该服务的服务配置文件中的任何策略。
另一方面,如果 IP 地址对应一个 Pod,
Linkerd 将不会执行任何负载均衡或应用任何服务配置文件。
如果使用无头服务(headless services),则无法检索服务的端点。
因此,Linkerd 不会执行负载均衡,而是只路由到目标 IP 地址。
负载均衡 gRPC
Linkerd 的负载均衡对于 Kubernetes 中的 gRPC(或 HTTP/2)服务特别有用,
对于这些服务,Kubernetes 的默认负载均衡是无效的。
自动代理注入
当命名空间或任何工作负载(例如部署或 Pod)上存在
linkerd.io/inject: enabled annotation 时,
Linkerd 会自动将数据平面代理添加到 Pod。这称为“代理注入(proxy injection)”。
代理注入也是代理配置发生的地方。
虽然很少需要,但您可以通过在注入之前在资源级别
设置额外的 Kubernetes annotations 来配置代理设置。
细节
代理注入是作为 Kubernetes admission
webhook 实现的。
这意味着代理会添加到 Kubernetes 集群本身内的 pod 中,
而不管 pod 是由 kubectl、CI/CD 系统还是任何其他系统创建的。
对于每个 pod,注入两个容器:
linkerd-init,一个 Kubernetes Init
Container,它配置iptables以通过代理自动转发所有传入和传出的 TCP 流量。
(请注意,如果 Linkerd CNI Plugin 已启用,则此容器不存在。)linkerd-proxy,Linkerd 数据平面代理本身。
请注意,简单地将 annotation 添加到具有预先存在的 pod 的资源不会自动注入这些 pod。
您将需要更新 pod(例如使用 kubectl rollout restart 等)以便注入它们。
这是因为 Kubernetes 在需要更新底层资源之前不会调用 webhook。
覆盖注入
通过添加 linkerd.io/inject: disabled annotation,
可以为 pod 或部署禁用自动注入,否则将为其启用。
手动注入
linkerd inject CLI 命令是一个文本转换,
默认情况下,它只是将 inject annotation 添加到给定的 Kubernetes 清单。
或者,这个命令也可以使用 --manual 标志在客户端执行完全注入。
这是 Linked2.4 之前的默认行为;
但是,向集群侧注入数据可以更容易地确保
数据平面始终存在并正确配置,而不管 pod 是如何部署的。
容器网络接口插件
Linkerd installs 可以配置去运行一个
CNI plugin,
该插件自动重写每个 pod 的 iptables 规则。
通过 pod 的 linkerd-proxy 容器路由网络流量需要重写 iptables。
启用 CNI 插件后,单个 Pod 不再需要包含需要 NET_ADMIN 功能来执行重写的 init 容器。
这在集群管理员限制该功能的集群中很有用。
安装
使用 Linkerd CNI 插件需要先在集群上成功安装 linkerd-cni DaemonSet,
然后再安装 Linkerd 控制平面。
使用 CLI
要安装 linkerd-cni DaemonSet,请运行:
linkerd install-cni | kubectl apply -f -
一旦 DaemonSet 启动并运行,所有包含 linkerd-proxy 容器(包括 Linkerd 控制平面)
的后续安装都不再需要包含 linkerd-init 容器。
init 容器的省略由控制平面安装时的 --linkerd-cni-enabled 标志控制。
安装 Linkerd 控制平面,使用:
linkerd install --linkerd-cni-enabled | kubectl apply -f -
这将在 linkerd-config ConfigMap 中设置 cniEnabled 标志。
所有后续代理注入都将读取此字段并省略 init 容器。
使用 Helm
首先确保您的 Helm 本地缓存已更新:
helm repo update
helm search linkerd2-cni
NAME CHART VERSION APP VERSION DESCRIPTION
linkerd-edge/linkerd2-cni 20.1.1 edge-20.1.1 A helm chart containing the resources needed by the Linke...
linkerd-stable/linkerd2-cni 2.7.0 stable-2.7.0 A helm chart containing the resources needed by the Linke...
运行以下命令安装 CNI DaemonSet:
# install the CNI plugin first
helm install linkerd2-cni linkerd2/linkerd2-cni
# ensure the plugin is installed and ready
linkerd check --pre --linkerd-cni-enabled
对于低于 v3 的 Helm 版本,必须专门传递 --name 标志。
在 Helm v3 中,它已被弃用,并且是上面指定的第一个参数。
此时,您已准备好在启用 CNI 的情况下安装 Linkerd。
您可以按照使用 Helm 安装 Linkerd 来执行此操作。
附加配置
linkerd install-cni 命令包括可用于自定义安装的附加标志。
有关更多信息,请参阅 linkerd install-cni --help。
请注意,许多标志类似于运行 linkerd 注入时可用于配置代理的标志。
如果在运行 linkerd install-cni 时更改了默认值,
则需要确保在运行 linkerd inject 时进行相应的更改。
最重要的标志是:
--dest-cni-net-dir: 这是 CNI 配置所在节点上的目录。 默认为:/etc/cni/net.d。--dest-cni-bin-dir: 这是 CNI 插件二进制文件所在的节点上的目录。默认为:/opt/cni/bin。--cni-log-level: 将此设置为debug将允许更详细的日志记录。
要查看 CNI 插件日志,您必须能够查看kubelet日志。
一种方法是登录节点并使用journalctl -t kubelet。
字符串linkerd-cni:可用作查找插件日志输出的搜索。
升级 CNI 插件
由于 CNI 插件基本上是无状态的,因此不需要单独的 upgrade 命令。
如果您使用 CLI 升级 CNI 插件,您可以执行以下操作:
linkerd install-cni | kubectl apply --prune -l linkerd.io/cni-resource=true -f -
请记住,如果您是从实验版本(experimental version)升级插件,则需要卸载并重新安装。
仪表板和 Grafana
除了命令行界面,
Linkerd 还提供了一个 Web 仪表板和预配置的 Grafana 仪表板。
要访问此功能,您需要安装 Viz 扩展:
linkerd viz install | kubectl apply -f -
Linkerd 仪表板
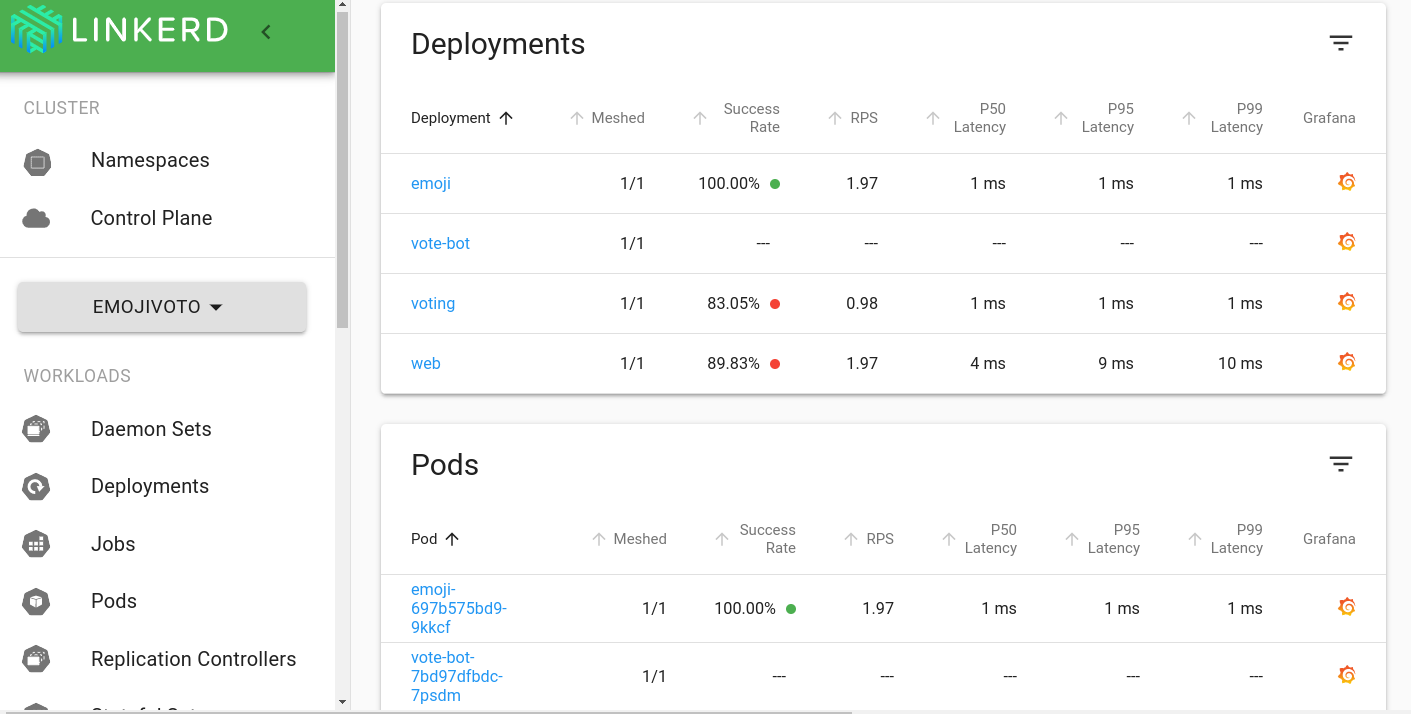
Linkerd 仪表板提供实时服务发生情况的高级视图。
它可用于查看“黄金”指标(成功率、请求/秒和延迟)、
可视化服务依赖关系并了解特定服务路由的健康状况。
拉起它的一种方法是从命令行运行 linkerd viz dashboard。
Grafana
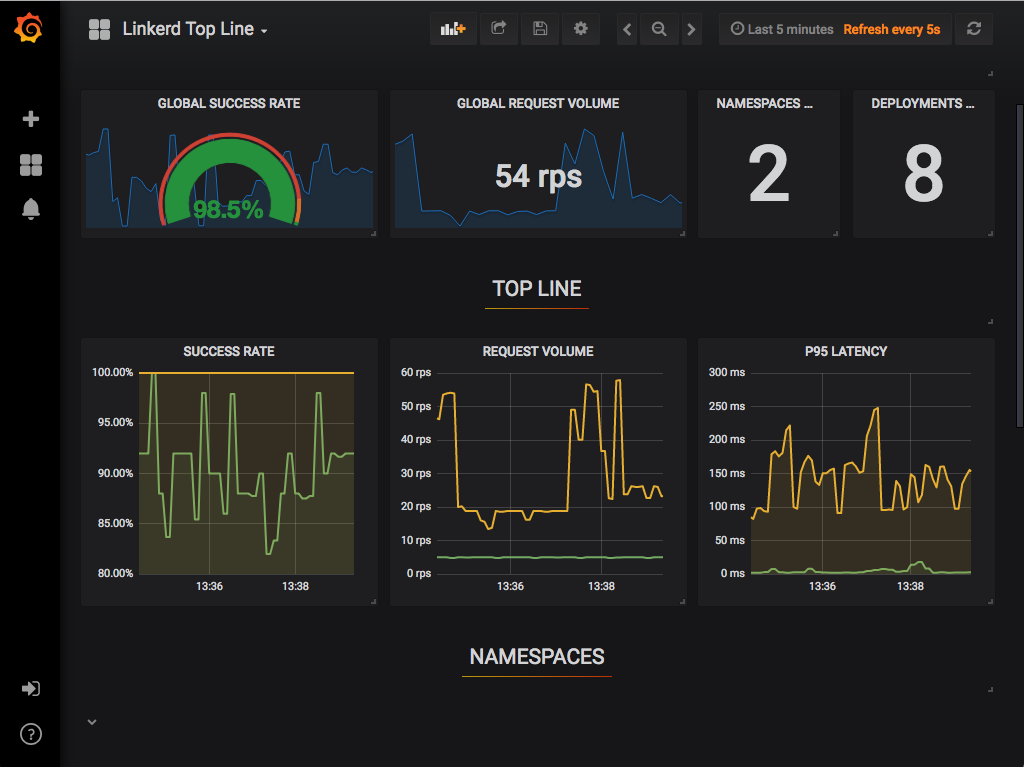
作为控制平面的一个组件,Grafana 为您的服务提供开箱即用的可操作仪表板。
可以查看高级指标并深入了解细节,甚至是 pod。
开箱即用的仪表板包括:
Top Line Metrics
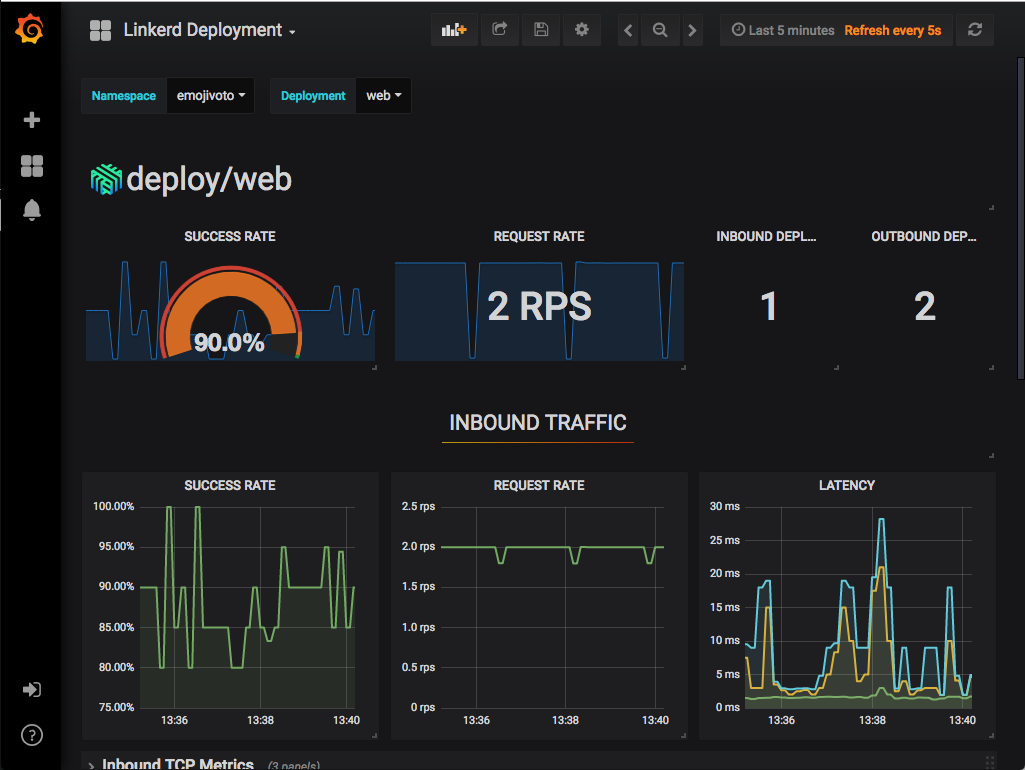
Deployment Detail
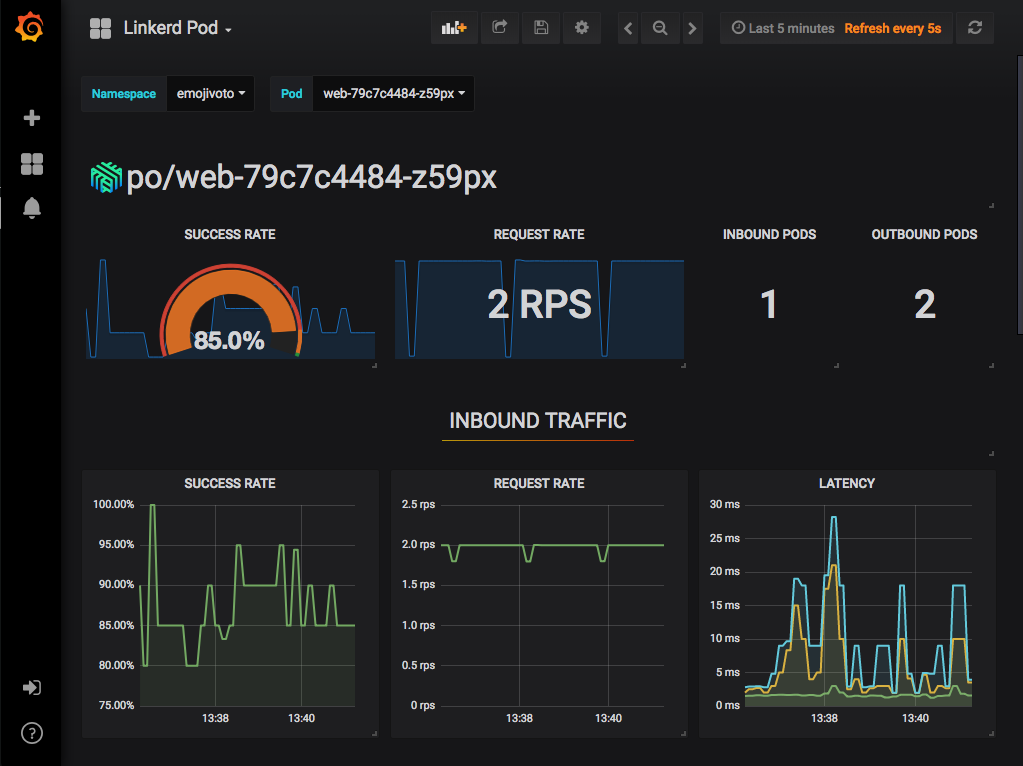
Pod Detail
Linkerd Health
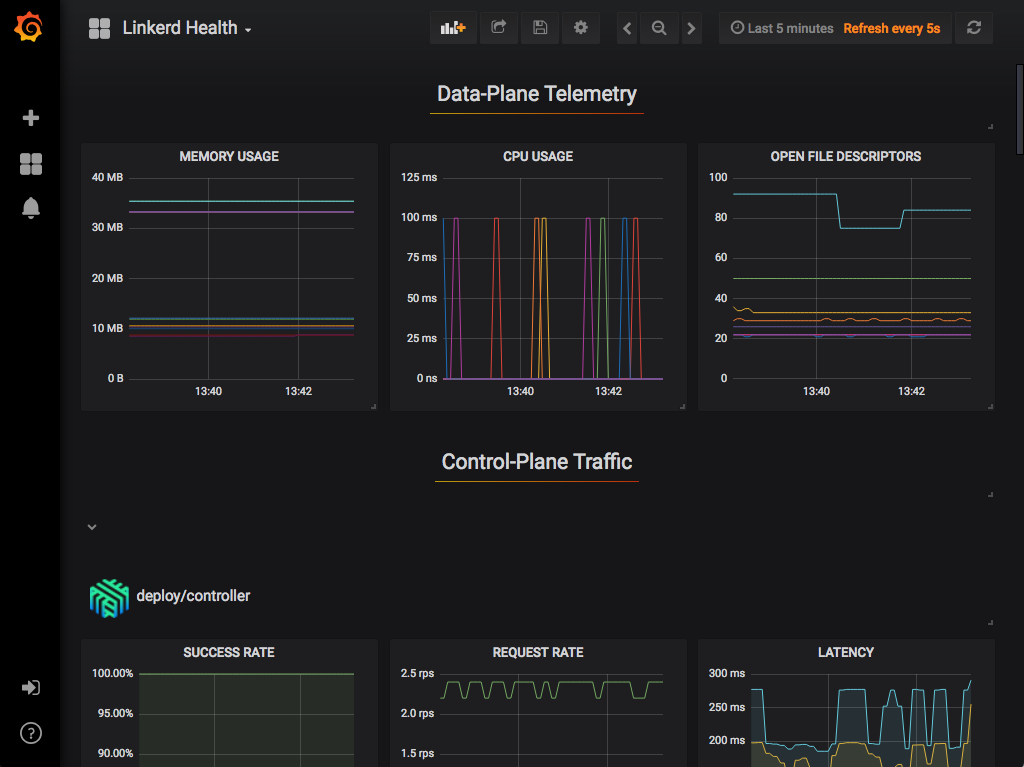
分布式追踪
跟踪可以成为调试分布式系统性能的宝贵工具,
尤其是用于识别瓶颈和了解系统中每个组件的延迟成本。
Linkerd 可以配置为从代理发出跟踪跨度,
允许您准确查看请求和响应在内部花费的时间。
与 Linkerd 的大多数功能不同,分布式跟踪需要更改代码和配置。
此外,Linkerd 提供了许多通常与分布式跟踪相关的功能,无需配置或应用程序更改,包括:
- 实时服务拓扑和依赖关系图
- 聚合服务运行状况、延迟和请求量
- 聚合 path / route 运行状况、延迟和请求量
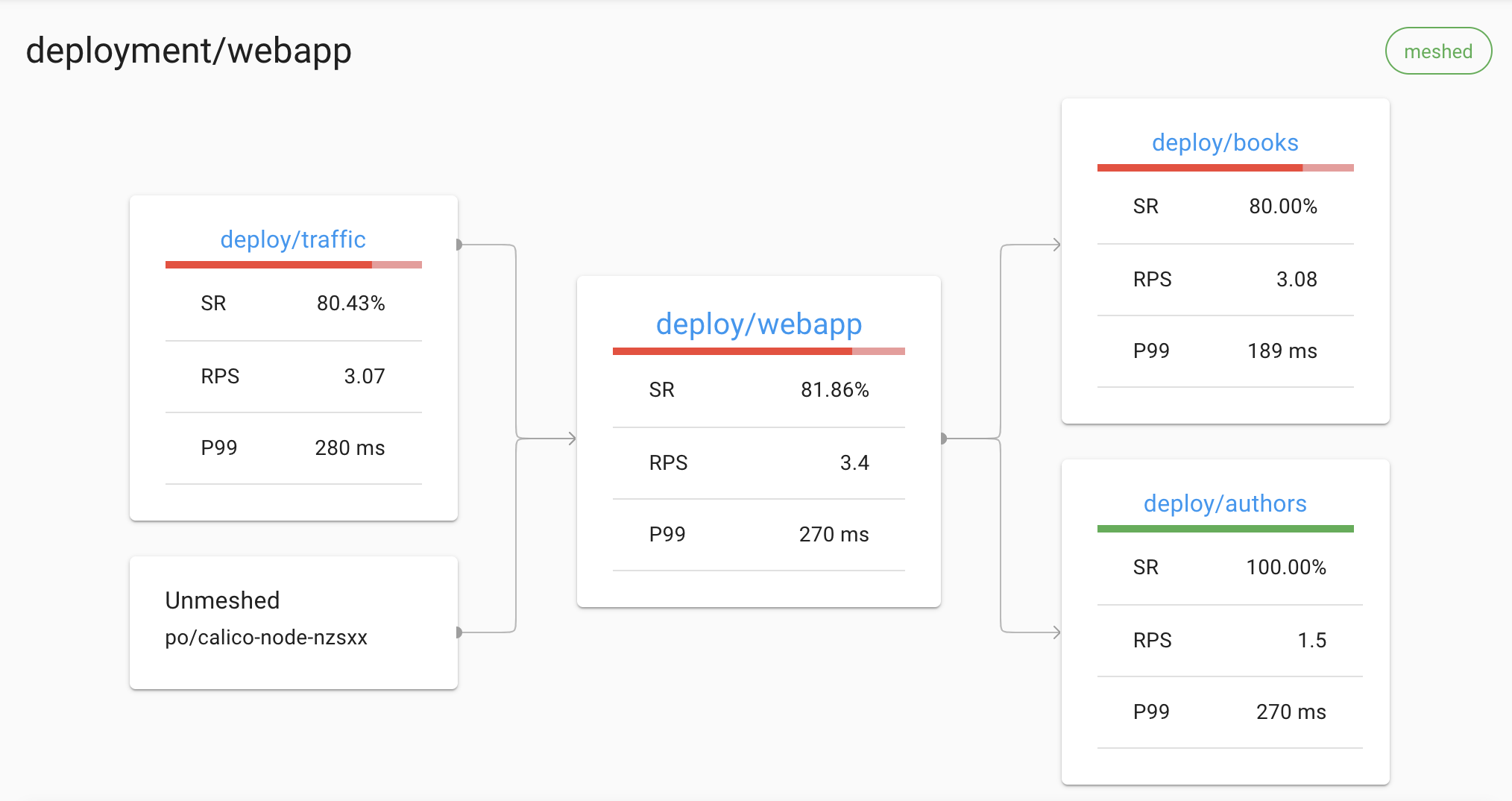
例如,Linkerd 可以显示服务的所有传入和传出依赖项的实时拓扑,
而无需分布式跟踪或任何其他此类应用程序修改:
Linkerd 仪表板显示自动生成的拓扑图
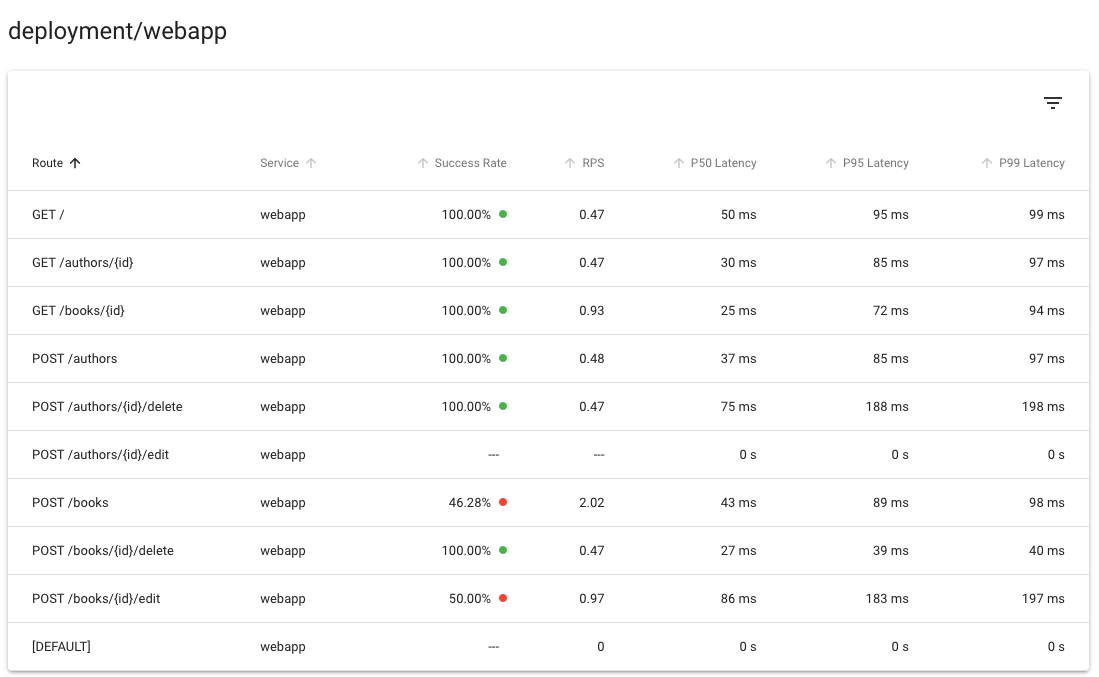
同样,Linkerd 可以为每个服务和每个 route 提供黄金指标,
同样不需要分布式跟踪或任何其他此类应用程序修改:
Linkerd 仪表板显示自动生成的路由指标
使用分布式跟踪
也就是说,分布式跟踪肯定有其用途,Linkerd 使这尽可能简单。
Linkerd 在分布式跟踪中的作用实际上非常简单:
当 Linkerd 数据平面代理(data plane proxy)在代理的 HTTP 请求中
看到跟踪头(tracing header)时,
Linkerd 将为该请求发出跟踪范围(trace span)。
此跨度将包括有关在 Linkerd 代理中花费的确切时间量的信息。
当与软件配合使用来收集、存储和分析这些信息时,
这可以提供对 mesh 行为的重要洞察。
要使用此功能,您还需要引入几个额外的系统中的组件,
包括启动特定请求跟踪的入口层(ingress layer)、
应用程序的客户端库(或传播跟踪头的机制)、
收集跨度数据并将其转换为跟踪的跟踪收集器,
以及跟踪后端存储跟踪数据并允许用户查看/查询它。
故障注入
故障注入是混沌工程的一种形式,通过人为地增加服务的错误率来观察对整个系统的影响。
传统上,这需要修改服务的代码,以添加一个执行实际工作的错误注入库。
Linkeder 可以做到这一点,而不需要任何服务代码更改,只需要一点配置。
高可用性
对于生产工作负载,Linkerd 的控制平面可以在高可用性 (HA) 模式下运行。 这种模式:
- 运行关键控制平面组件的三个副本。
- 在控制平面组件上设置生产就绪(production-ready) CPU 和内存资源请求。
- 在数据平面代理上设置生产就绪的 CPU 和内存资源请求
- 要求 proxy auto-injector 可用于任何要调度的 pod。
- 在关键控制平面组件上设置反关联性策略(anti-affinity
policies),
以确保在可能的情况下,默认情况下将它们安排在单独的节点和单独的区域中。
启用 HA
您可以在控制平面安装时使用 --ha 标志启用 HA 模式:
linkerd install --ha | kubectl apply -f -
另请注意,可视化扩展还支持具有类似特征的 --ha 标志:
linkerd viz install --ha | kubectl apply -f -
您可以在安装时通过将其他标志传递给 install 命令来覆盖 HA 行为的某些方面。
例如,您可以使用 --controller-replicas 标志覆盖关键组件的副本数:
linkerd install --ha --controller-replicas=2 | kubectl apply -f -
请参阅完整的 install CLI 文档以供参考。
linkerd upgrade 命令可用于在现有控制平面上启用 HA 模式:
linkerd upgrade --ha | kubectl apply -f -
代理注入器故障策略
HA 代理注入器(proxy injector)部署了更严格的故障策略(failure policy),
以强制执行 automatic proxy injection。
此设置可确保在没有 Linkerd 代理的情况下,
不会意外安排带注解的工作负载在您的集群上运行。(当代理注入器关闭时可能会发生这种情况。)
如果在准入阶段由于无法识别或超时错误导致代理注入过程失败,
则工作负载准入将被 Kubernetes API 服务器拒绝,部署将失败。
因此,始终至少有一个运行在集群上的代理注入器的健康副本非常重要。
如果您不能保证集群上健康的代理注入器的数量,
您可以通过将其值设置为 Ignore 来放松 webhook 故障策略,如 Linkerd
Helm chart所示。
有关准入 webhook 失败策略的更多信息,请参阅 Kubernetes
documentation。
排除 kube-system 命名空间
根据 Kubernetes documentation
的建议,应该为 kube-system 命名空间禁用代理注入器。
这可以通过使用以下标签标记 kube-system 命名空间来完成:
kubectl label namespace kube-system config.linkerd.io/admission-webhooks=disabled
在具有此标签的命名空间中工作负载的准入阶段,Kubernetes API 服务器不会调用代理注入器。
Pod 反关联规则
所有关键控制平面组件都部署了 pod 反关联性(anti-affinity)规则以确保冗余。
Linkerd 使用 requiredDuringSchedulingIgnoredDuringExecution pod anti-affinity 规则
来确保 Kubernetes 调度程序不会将关键组件的副本并置在同一节点上。
还添加了一个 preferredDuringSchedulingIgnoredDuringExecution pod anti-affinity 规则,
以尝试在可能的情况下在不同区域中安排副本。
为了满足这些反关联(anti-affinity)规则,HA 模式假设 Kubernetes 集群中始终至少有三个节点。
如果违反此假设(例如,集群缩小到两个或更少的节点),则系统可能会处于非功能(non-functional)状态。
请注意,这些反关联性规则不适用于 Prometheus 和 Grafana 等附加组件。
缩放 Prometheus
Linkerd Viz 扩展提供了一个预配置的 Prometheus pod,但对于生产工作负载,
我们建议设置您自己的 Prometheus 实例。
在规划存储 Linkerd 时间序列数据的内存容量时,通常的指导是每个网格 pod 5MB。
如果您的 Prometheus 由于来自数据平面的数据量而遇到定期 OOMKilled 事件,
则可以调整的两个关键参数是:
storage.tsdb.retention.time定义将采样保留多长时间。
更高的值意味着需要更多的内存来将数据保存更长时间。
降低此值将减少OOMKilled事件的数量,因为数据保留的时间较短storage.tsdb.retention.size定义可以为块存储的最大字节数。
较低的值也将有助于减少OOMKilled事件的数量
使用 Cluster AutoScaler
Linkerd 代理将其 mTLS 私钥存储在
tmpfs emptyDir 卷中,
以确保此信息永远不会离开 pod。
这会导致 Cluster AutoScaler 的默认设置无法缩小具有注入工作负载副本的节点。
解决方法是使用 cluster-autoscaler.kubernetes.io/safe-to-evict: "true" annotation 来注入工作负载。
如果您可以完全控制 Cluster AutoScaler 配置,
则可以使用 --skip-nodes-with-local-storage=false 选项启动 Cluster AutoScaler。
多集群通信
Linkerd 可以以安全、对应用程序完全透明且独立于网络拓扑的方式
跨集群边界连接 Kubernetes 服务。这种多集群功能旨在提供:
- 统一的信任域。 在集群边界内和跨集群边界的每一步都验证源和目标工作负载的身份。
- 单独的故障域。 一个集群的故障允许剩余的集群运行。
- 支持异构网络。 由于集群可以跨越云、VPC、本地数据中心及其组合,
Linkerd 不会引入除网关连接(gateway connectivity)之外的任何 L3/L4 要求。 - 集群通信中的统一模型。 Linkerd 为集群内通信提供的可观测性(observability)、可靠性(reliability)
和安全特性(security)也扩展到了跨集群通信。
就像集群内连接一样,Linkerd 的跨集群连接对应用程序代码是透明的。
无论通信发生在集群内、数据中心或 VPC 内的集群之间,
还是通过公共互联网,Linkerd 都会在集群之间建立连接,
该连接在双方都使用 mTLS 进行加密和身份验证。
工作原理
Linkerd 的多集群支持通过在集群之间“镜像(mirroring)”服务信息来工作。
由于远程服务被表示为 Kubernetes 服务,
Linkerd 的完整可观察性、安全性和路由功能统一
适用于集群内和集群调用,应用程序不需要区分这些情况。
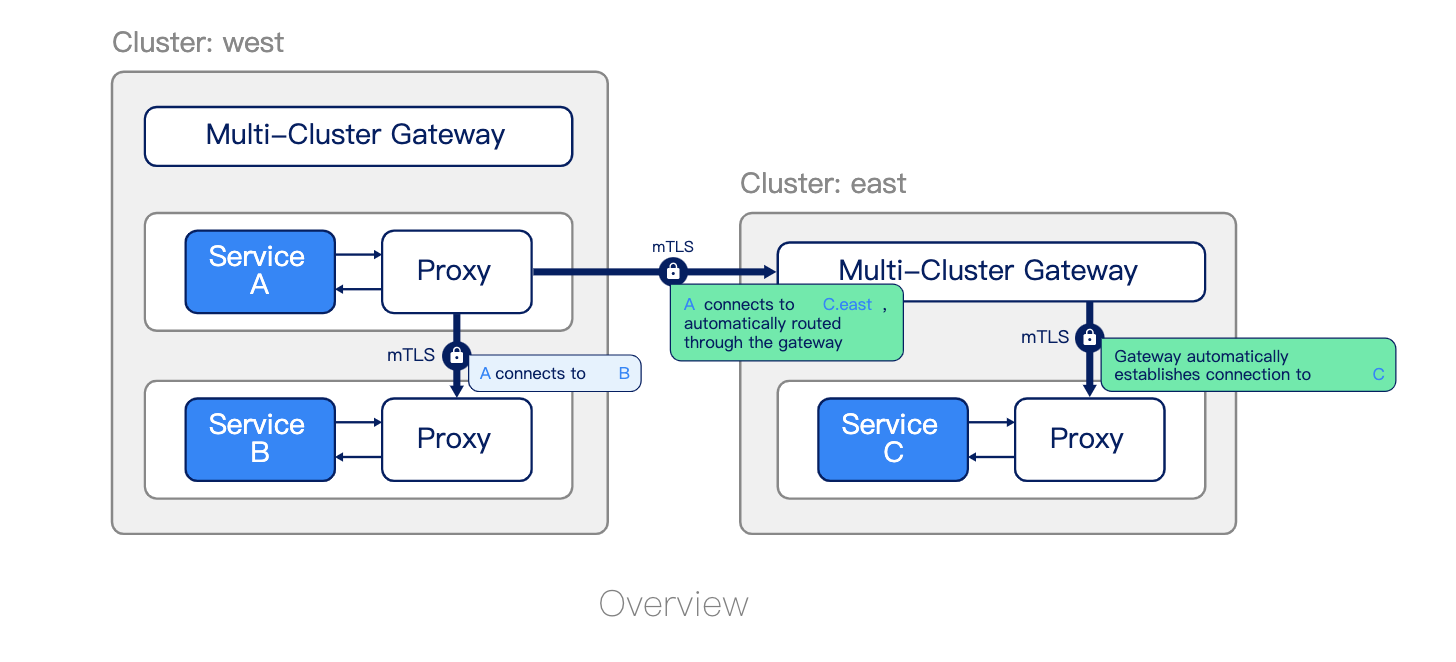
Linkerd 的多集群功能由两个组件实现:服务镜像(service mirror)和网关(gateway)。
服务镜像(service mirror)组件监视目标集群中的服务更新,并在源集群上本地镜像这些服务更新。
这提供了对目标集群的服务名称的可见性,以便应用程序可以直接寻址它们。
多集群网关组件为目标集群提供了一种从源集群接收请求的方式。(这允许 Linkerd 支持分层网络)
安装这些组件后,可以将与标签选择器(label selector)匹配的 Kubernetes Service 资源导出到其他集群。
服务配置文件
服务配置文件是一种自定义 Kubernetes 资源 (CRD),
可以提供有关服务的 Linkerd 附加信息。
特别是,它允许您定义服务的路由列表。
每个路由都使用一个正则表达式来定义哪些路径应该与该路由匹配。
定义服务配置文件使 Linkerd 能够报告每个路由的指标,
还允许您启用每个路由的功能,例如重试和超时。
如果使用无头服务,则无法检索服务配置文件。
Linkerd 根据目标 IP 地址读取服务发现信息,
如果这恰好是 pod IP 地址,则它无法判断 pod 属于哪个服务。
流量拆分(金丝雀、蓝/绿部署)
Linkerd 的流量拆分功能允许您将目的地为 Kubernetes 服务的流量的任意部分动态转移到不同的目的地服务。
此功能可用于实施复杂的部署策略,例如
金丝雀部署和
蓝/绿部署,
例如,通过缓慢地将流量从旧版本的服务转移到新版本。
如果使用无头服务,则无法检索流量拆分。
Linkerd 根据目标 IP 地址读取服务发现信息,
如果这恰好是 pod IP 地址,则它无法判断 pod 属于哪个服务。
Linkerd 通过 Service Mesh Interface (SMI)
TrafficSplit API 公开此功能。
要使用此功能,您需要按照 TrafficSplit 规范中的描述创建一个 Kubernetes 资源,Linkerd 负责其余的工作。
通过将流量拆分与 Linkerd 的指标相结合,可以实现更强大的部署技术,
自动考虑新旧版本的成功率和延迟。
有关此示例的一个示例,请参阅 Flagger 项目。
我是为少
微信:uuhells123
公众号:黑客下午茶
加我微信(互相学习交流),关注公众号(获取更多学习资料~)