所有模块要经历的两个步骤:
(1)要操作的概念本身; 例如:正则表达式,时间
(2)使用模块去操作它; 例如:re模块,time模块
在python中永远不要创建一个和模块名相同名字的文件
re模块
正则表达式:一种匹配字符串的规则
正则表达式是一种独立语法,和python没有关系
正则表达式的功能:
(1)定制一个规范:确认一个字符串是否符合规则;从大段的字符串中找到符合规则的内容
(2)程序领域:登录注册页的表单验证;爬虫(把这个网页下载下来,从里面提取一些信息,找到我要的所有信息做数据分析);自动换行,日志分析
元字符:
字符组:个性化的定制
[0-9] 筛选0到9的数据
[a-z] 筛选a到z小写英文字母
[A-Z] 筛选A到Z大写英文字母
[0-9][A-Z][a-z]必须按照数字大写字母小写字母顺序的对应顺序来匹配
[0-9a-zA-Z]不按照顺序匹配一个字符
[abc0-9]匹配abc三个字母中的一个加上一个0到9之间的数字
\d == [0-9] 匹配一个数字 \D 匹配非数字
\w == [0-9a-zA-Z_] 匹配一个数字,字母或下划线 \W 匹配非数字,字母和下划线
\s == [\s\t] 匹配任意的空白字字符(包括enter,空格和tab) \S 匹配一个非空白的字符
[\s\S]或[\d\D]或[\w\W]匹配所有
...\b(\b...) 匹配一个...的结尾(开头)的字符串 例:hellow word \bw =>w 1个匹配结果 d\b =>d 1个匹配结果
^ 匹配字符串的开始 必须xie在开头
$ 匹配字符串的结尾 必须写在结尾 ^hellow$ => hellow
a|b 匹配a或b一个字符串 如果a b有重合的部分必须把长字符放在前面
() 表示分组
[^... ] 表示除了...字符组的所有字符
. 表示除了换行符之外的任意字符 爬虫用的比较多,表单用的少
[...] 匹配...字符组中的字符
量词:
{n} 重复n词
{n,}重复至少n词 尽量多的匹配(贪婪匹配)
{n,m} 重复n到m词
?重复零次或一次
+重复至少一次
*重复零次或更多次
在量词后面加?:表示取消贪婪匹配即非贪婪匹配(惰性匹配)
贪婪匹配内部执行回溯算法
.*?...表示匹配到任意字符知道找到一个...
转译 "\"表示转译例如\.表示. r\. 表示不转译 .
例: 身份证号 : [1-9]{14}(\d{2}[0-9x])?
例: 小数和整数:\d+(\.\d+)?
转译符: \表示转译符
在字符组中[]中的一些特殊字符会现原形 例:[()*+-/$.]
[-]-只有写在字符组的首位表示负号 在其他位置表示范围 想要匹配减号就必须加\转译
re模块的常用方法:
匹配:
1.findall 会优先选择分组()内的内容,取消优先选择(?:正则表达式)
语法:re.findall(正则表达式,待匹配的内容)
返回值类型:列表没有值是空列表
返回值内容:匹配上的所有项
2.search 如果search中有分组中通过group(n)就能拿到group中匹配的内容
语法:re.search(正则表达式,待匹配内容) 通过group来获取匹配到的第一个结果
返回值类型:正则匹配结果的对象,如果没有匹配就返回None
返回值内容:只返回第一个匹配上的结果
3.math
语法:re.math(正则表达式,待匹配内容)
相当于search的正则表达式前面加上一个"^"
替换:
1.sub
语法:re.sub(正则表达式,替换值,待匹配内容)
也可以指定替换次数:在待匹配对象后面加上次数
返回值类型:字符串
2.subn
语法:re.subn(正则表达式,替换值,待匹配内容)
返回值内容:替换后结果和替换次数
返回值类型:元组
3.split 切割时遇到分组保留分组中替换的内容
语法:re.split(正则表达式,待匹配内容)
返回值类型:列表
compile 节省时间
语法:re.compile(正则表达式)
只有在多次使用某一个相同的正则表达式的时候,compile会帮助我们节省时间
finditem 节省空间
语法:re.finditem(正则表达式,待匹配内容)
返回值类型:生成器 可以for循环 拿到对象通过group方法拿到内容
分组使用进阶:
1.命名
(?P<name>正则表达式) 分组命名 :
(?P=name)使用这个分组,这里匹配到的内容和分组中的内容完全相同:
2.索引
(\n)表示使用第n组,表示匹配到的内容必须和第n组内容相同
random模块
随机:在某一个范围内取到每一个值的概率是相等的
随机小数:
random.random() 0-1之间的任意小数
random.uniform(任意范围) 任意范围内的随机小数
随机整数:
random.randint(1,2) [1,2]1-2包括1和2范围内的整数
random.randrange(1,2) [1,2)1-2包括1不包括2范围内的整数
random.randrange(1,10,2) [1,10)1-10包括1不包括10范围内的奇数
随机抽取:
random.choice(列表) 随机抽取列表中的一个值
random.sample(列表,n) 随机抽取列表中的n个值
打乱顺序:
random.shuffle(列表) 打乱列表顺序
time 模块
时间戳时间\格林威治时间(给机器看的):float数据类型
语法:time.time() 表示从英国伦敦时间:1970.1.1 0:0:0 (北京时间:1970.1.1 8:0:0)开始计算到现在有多少秒
结构化时间\时间对象(从给机器看到给人看的过程): 时间对象能通过属性来获取对象中的值
语法:time.localtime() 返回值类型:元组 通过time.localtime().tm_year获取年份
格式化时间\字符串时间(给人看的时间):str数据类型
语法:time.strftime("%Y-%m-%d %H:%M:%S") 可以根据你需要的格式来显示时间
例:
import time
print(time.time())
print(time.localtime())
print(time.strftime("%Y-%m-%d %H:%M:%S")) #大写Y显示2018 小写y显示18
结果:
1533716311.5736582
time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=16, tm_min=18, tm_sec=31, tm_wday=2, tm_yday=220, tm_isdst=0)
2018-08-08 16:18:31
时间戳时间--结构化时间--格式化时间之间关系:
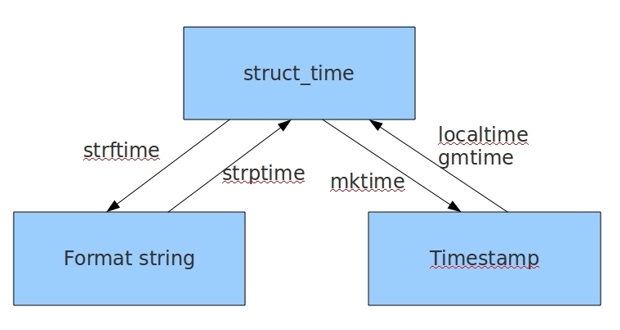
例:找到本月1号的时间戳时间
第一种方法:
import time
locals_time = time.localtime()
ret = time.strptime("%s-%s-1" %(locals_time.tm_year,locals_time.tm_mon),"%Y-%m-1")
print(time.mktime(ret)) ==>1533052800.0
第二种方法:
import time
ret = time.strftime("%Y-%m-1")
tim = time.strptime(ret,"%Y-%m-%d")
print(time.mktime(tim)) ==>1533052800.0
sys 模块:
sys.path 返回模块的搜索路径,初始化时使用pythonpath环境变量的值
sys.modules 返回所有在当前这个python程序中导入的模块的
sys.exit 退出程序
sys.argv 返回一个列表 列表的第一个元素是执行这个文件的时候,写在python后面的第一个值, 之后的元素是在执行python的启动的时候可以写多个值.都会依次添加到列表中
os 模块:和操作系统进行交互的
工作目录相关:
os.getcwd() 在那执行文件就获取当前文件地址
例:
import os
print(os.getcwd()) ==>F:\面向对象\180808
os.chdir(新地址) 修改当前文件目录,相当于 shell下cd
例:
import os
print(os.getcwd())
os.chdir(r"F:\面向对象\180807")
print(os.getcwd())
结果:
F:\面向对象\180808
F:\面向对象\180807
os.curdir 返回当前目录 结果: .
os.pardir 获取当前目录的父级目录字符串名 结果: ..
创建文件/文件夹和删除文件/文件夹相关:
os.makedirs(文件名1/文件名2) 可生成多层递归目录
os.removedirs(文件1/文件2) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,一次类推
os.mkdir(文件名) 生成单级目录 ,相当于shell中mkdir dirname
os.rmdir(文件名) 删除单级目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(文件名) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove(文件名) 删除文件
os.rename(oldname,newname) 重命名文件名
和操作系统差异相关:
os.stat(路径) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符, win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符, win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串, win下为";",Linux下为":"
os.name 输出字符串指示当前使用平台, win下为"nt",Linux下为"posix"
使用pyth来和操作系统命令交互:
os.system("base command") 运行shell命令,直接显示
os.popen("base command").read() 运行shell命令,获取执行结果
查看环境变量:
os.environ 获取系统环境变量
os.path
os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割目录和文件名二元组返回
os.path.dirname(path) 返回path的目录,其实就是os.path.split(path)的第一个元素 os.path.basename(path)返回path最后文件名.如果path以"/"或"\"结尾,那么就会返回空值
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True,否则返回False
os.path.isdir(path) 如果path是一个存在的目录,返回True,否则返回False
os.path.join(path1[,path2[,path3[,...]]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
例:获取文件的路径
import os
print(__file__)
print(os.path.dirname(__file__))
print(os.path.dirname(os.path.dirname(__file__)))
结果:
F:/面向对象/180808/课堂练习.py
F:/面向对象/180808
F:/面向对象
序列化模块:json pickle shelve
序列化:将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化.
序列化的目的:1.把内容写入文件;2.网络传输数据
json模块:
json. dumps(dict) 将字典转化成字符串
例:
import json
dic = {"a":1,"b":2,"c":3}
str_dic = json.dumps(dic)
print(str_dic,type(str_dic)) ==>{"a": 1, "b": 2, "c": 3} <class 'str'>
json.loads(str) 将字符串转化成字典
例:
import json
str_dic = '{"a": 1, "b": 2, "c": 3}'
dic = json.loads(str_dic)
print(dic,type(dic)) ==>{'a': 1, 'b': 2, 'c': 3} <class 'dict'>
json.dump(dict) 将字典写成字符串写入文件
例:
import json
dic = {"a":1,"b":2,"c":3}
with open("json_dumps",mode="w",encoding="utf-8")as f:
json.dump(dic,f)
json.load(句柄) 从文件中读取并转化成字符串
例:
import json
with open("json_dumps",mode="r",encoding="utf-8")as f:
print(json.load(f)) ==>{'a': 1, 'b': 2, 'c': 3}
json能处理的数据类型有限,限制比较多
限制:
1.json格式中字典的key必须是字符串数据类型
2.如果是数字为key,那么dump之后会强转成字符串数据类型
3.对元组做value的字典会把元组强制转换成列表
4.json不支持元组做key会报错
5.json处理文件中的字符串必须是双引号
6.能多次dump数据到文件中但不能load出来 多次写入数据到文件中用dumps从文件中读出数据用loads
7.json中集合不能使用dump/dumps方法
8.json中dumps元组类型会将元组强转成列表再转化成字符串
例: 中文格式的写入文件中的编码ensure_ascii
import json
dic = {"abc":1,"country":'中国'}
ret = json.dumps(dic,ensure_ascii=False)
print(ret) ==>{"abc": 1, "country": "中国"}
sort_keys对字典的key的首字母做排序
indent设置缩进
separators根据标点符号来换行
ensure_ascii 显示中文
例:
import json
dic = {"name":'小白','age':'18','hobby':["听歌",'画画']}
ret = json.dumps(dic,sort_keys=True,indent=4,separators=(",",":"),ensure_ascii=False)
print(ret)
结果:
{
"age":"18",
"hobby":[
"听歌",
"画画"
],
"name":"小白"
}
json的其他参数是为了用户看着更方便,但是会相对浪费时间
pickle模块: 与文件相关模式:rb,wb
pickle支持几乎所有的对象的序列化
pickle.dumps的结果是bytes类型
例:
import pickle
dic = {1:(2,3,4),('a','b'):4}
pic_dic = pickle.dumps(dic)
print(pic_dic) ==>b'\x80\x03}q\x00(K\x01K\x02K\x03K\x04\x87q\x01X\x01\x00\x00\x00aq\x02X\x01\x00\x00\x00bq\x03\x86q\x04K\x04u.' #bytes类型
new_dic = pickle.loads(pic_dic)
print(new_dic) ==>{1: (2, 3, 4), ('a', 'b'): 4}
一个类的对象也可用pickle.dumps存储起来
例:
import pickle
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
one_person = Student("小白",18)
ret = pickle.dumps(one_person)
print(ret)
new_person = pickle.loads(ret)
print(new_person.name) ==>小白
print(new_person.age) ==>18
例:写入文件
import pickle
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
one_person = Student("小白",18)
with open("pickle_demo","wb")as f:
pickle.dump(one_person,f)
with open("pickle_demo","rb")as f1:
ret = pickle.load(f1)
print(ret.name,ret.age) ==>小白 18
pickle支持几乎所有对象序列化 对象的序列化需要这个对象对应的类在内存中
例:对于多次dump/load的操作做了良好的处理
import pickle
with open("pickle_demo","wb")as f:
pickle.dump({"k1":"v1"},f)
pickle.dump({"k2":"v2"},f)
pickle.dump({"k3":"v3"},f)
with open("pickle_demo","rb")as f1:
while True:
try:
print(pickle.load(f1))
except EOFError:
break
结果:
{'k1': 'v1'}
{'k2': 'v2'}
{'k3': 'v3'}
shelve模块:
对于shelve模块如果写定一个文件并且改动比较少,读文件的操作比较多,且大部分读取都需要基于某个key来获得对应的value才用shelve
例:
import shelve
f = shelve.open("text")
f["key"] = {"k1":(1,2,3),"k2":"v2"}
f.close()
f = shelve.open("text")
content = f["key"]
f.close()
print(content) ==>{'k1': (1, 2, 3), 'k2': 'v2'}
hashlib模块:
定义:能把一个字符串数据类型的变量转换成一个定长的密文的字符串,字符串里的每一个字符都是一个十六进制的数字 且字符串到密文不可逆
对于相同的字符串用相同的算法相同的手段去进行摘要获得的值总是相同的
md5和sha1都是算法它们两个相互独立.
对于同一个字符串不管这个字符串有多长,只要是相同,无论在任何环境下,多少次执行在任何语言中使用相同的算法相同手段得到的结果永远是相同的;反之,只要不是相同的字符串,得到的结果一定不同
md5 32位字符,每个字符都是十六进制
sha1 40位字符,每个字符都是十六进制
例: md5
import hashlib
s = "abcd"
md5_obj = hashlib.md5()
md5_obj.update(s.encode("utf-8"))
ret = md5_obj.hexdigest()
print(ret,len(ret),type(ret)) ==>e2fc714c4727ee9395f324cd2e7f331f 32 <class 'str'>
例: sha1
import hashlib
s = "abcd"
sha1_obj = hashlib.sha1()
sha1_obj.update(s.encode("utf-8"))
ret = sha1_obj.hexdigest()
print(ret,len(ret),type(ret)) ==>81fe8bfe87576c3ecb22426f8e57847382917acf 40 <class 'str'>
md5比sha1快效率高
md5算法相对简单,比较普及 sha1算法相对复杂,计算速度也慢但是安全性更高,因为用的人少.
为了避免撞库问题我们需要对密码进行动态加盐
例:
import hashlib
username = input(">>>>>")
password = input(">>>>>")
md5_obj = hashlib.md5(username.encode("utf-8"))
md5_obj.update(password.encode("utf-8"))
ret = md5_obj.hexdigest()
print(ret)
结果:
>>>>>你好
>>>>>123
36473306e94d8d0f8dc4af5d4d9e17cc
例: 文件是否一致的校验
import hashlib
md5_obj = hashlib.md5()
with open("hashlib_demo1","rb")as f:
md5_obj.update(f.read())
ret = md5_obj.hexdigest()
print(ret)
md5_obj = hashlib.md5()
with open("hashlib_demo2","rb")as f:
md5_obj.update(f.read())
ret1 = md5_obj.hexdigest()
print(ret1)
if ret == ret1:
print("True")
else:
print("False")
configparser模块:
定义:有一种固定格式的配置文件.有一个对应的模块去帮你做这个文件的字符串处理
配置文件后缀.ini
生成配置文件格式:
例:
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
with open('example.ini', 'w') as configfile:
config.write(configfile)
结果:
[DEFAULT] #section
serveraliveinterval = 45 #option
compression = yes #option
compressionlevel = 9 #option
forwardx11 = yes #option
[bitbucket.org] #section
user = hg #option
[topsecret.server.com] #setion
host port = 50022 #option
forwardx11 = no #option
logging模块:
功能:
1.日志格式的规范
2.操作的简化
3.日志的分级管理
logging不能做的事:不能自动生成要打印的内容
需要自己在开发的时候定好,哪些地方需要打印,打印的内容是什么,内容的级别
logging模块的使用方法:
1.普通配置形, 简单的,可定制化差
2.对象配置,复杂的,可定制化强
例:
import logging
logging.basicConfig(level=logging.DEBUG) #不写level默认答应警告以上的所有内容
logging.debug("debug message") #调试
logging.info("info message") #基础信息
logging.warning("warning message")#警告
logging.error("error message") #错误
logging.critical("critical message") #严重错误
结果:
DEBUG:root:debug message
INFO:root:info message
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
例:
import logging
logging.basicConfig(level=logging.DEBUG,
format = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt="%a,%d %b %Y %H:%M:%S",
filename="logging_demo")
logging.debug("debug message") #调试
logging.info("info message") #基础信息
logging.warning("warning message")#警告
logging.error("error message") #错误
logging.critical("critical message") #严重错误
在屏幕上输出不用打印filename
写入文件要在baicconfig中写入文件名
basicconfig不能将一个logging信息即输出到屏幕上又输入到文件中
例: 将一个logging信息即输出到屏幕上又输入到文件中
import logging
logger = logging.getLogger()
fh = logging.FileHandler('test.log',encoding='utf-8') # 创建一个handler,用于写入日志文件
ch = logging.StreamHandler() # 再创建一个handler,用于输出到控制台
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') #创建一个日志输出格式
logger.setLevel(logging.DEBUG) #设置输出内容级别
fh.setFormatter(formatter) #文件管理操作符绑定一个格式
ch.setFormatter(formatter) #屏幕管理操作符绑定一个格式
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')