我们都知道在进行hive的查询的时候,设置合理的reduce个数能够使计算的速度加快。
具体的提高速度的方法有下面这些:
(1) hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
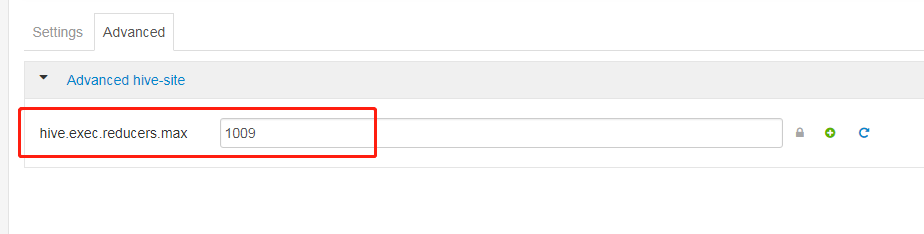
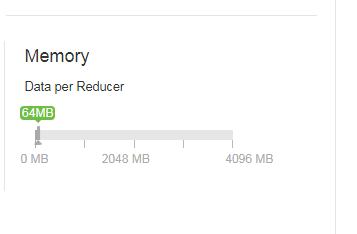
我们公司的集群当中的这两个参数的设置如图所示。
在数据进入到reduce中的时候,在map的输入的时候总的数据量小于这个数的时候,会交给一个reduce去处理。
(2)set mapred.reduce.tasks = 15;
也可以通过设置reduce的个数进行reduce端的设置。截图如下:

虽然设置了reduce的个数看起来好像执行速度变快了。但是实际并不是这样的。
同map一样,启动和初始化reduce也会消耗时间和资源,
另外,有多少个reduce,就会有多少个输出文件,如果生成了很多小文件,那这些小文件作为下一次任务的输入,则也会出现小文件过多的问题。
对于整个sql的优化可以从下面几个步骤去优化:
(1)尽量尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段
(2)单个SQL所起的JOB个数尽量控制在5个以下
(3)慎重使用mapjoin,一般行数小于2000行,大小小于1M(扩容后可以适当放大)的表才能使用,小表要注意放在join的左边。否则会引起磁盘和内存的大量消耗
(4)写SQL要先了解数据本身的特点,如果有join ,group操作的话,要注意是否会有数据倾斜
set hive.exec.reducers.max=200;
set mapred.reduce.tasks= 200;---增大Reduce个数
set hive.groupby.mapaggr.checkinterval=100000 ;--这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
(5) 如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,这样会提升执行的速度。