最近在看关于窗口分析函数的一些东西,在这里总结一下:
(1)head()和 LAG()函数
说明:
head()按照指定的字段,然后取排序后当前行的后面多少行的这个字段的值。
举例:
lead(CREATE_TIME,2) OVER(PARTITION BY ID ORDER BY CREATE_TIME) AS lead_time
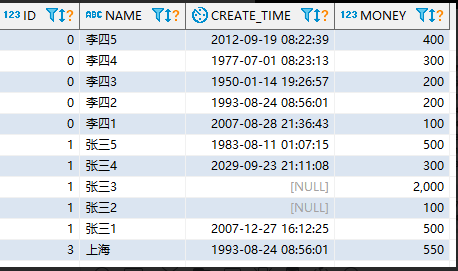
这一句的意思是按照id进行分组,然后按照创建时间进行排序,然后取当前行的下面两个的这个创建时间的值。
LAG()按照指定字段,然后取排序后当前行的前面多少行的这个字段的值。
举例:
LAG(CREATE_TIME,2) OVER(PARTITION BY ID ORDER BY CREATE_TIME) AS lag_time
这一句的意思是按照id进行分组,然后按照创建时间进行排序,然后取当前行上面的这个创建时间的值
SELECT ID, CREATE_TIME, MONEY, ROW_NUMBER() OVER(PARTITION BY ID ORDER BY CREATE_TIME) AS rn, LAG(CREATE_TIME,2) OVER(PARTITION BY ID ORDER BY CREATE_TIME) AS lag_time , lead(CREATE_TIME,2) OVER(PARTITION BY ID ORDER BY CREATE_TIME) AS lead_time FROM TEST1
下面是运行结果:
(1)FIRST_VALUE()
说明:
分组然后统计出,排序字段的第一个value值。
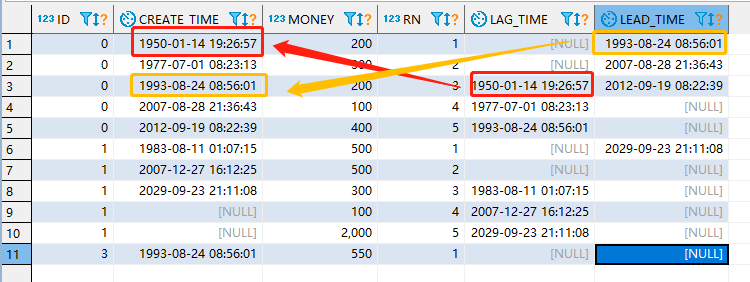
SELECT id,money,FIRST_VALUE( money ) OVER( PARTITION BY id ORDER BY money ) FROM TEST1

(2)SELECT id,money,FIRST_VALUE( money ) OVER( PARTITION BY id ORDER BY money ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) FROM TEST1
在这个函数当中开窗函数当中多了一个参数
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
这个参数的意思是,每行对应的数据窗口是从第一行到最后一行
我们可以对参数其中的数字进行设置,BETWEEN 后面的1可以设置,也就是比如我这里设置为3.也就是前三行的value值都是分组后第一个value值。后面的值直接顺延就可以了。示例如下:
(3)LAST_VALUE() 说明:
分组然后统计出,排序字段的最后一个value值。
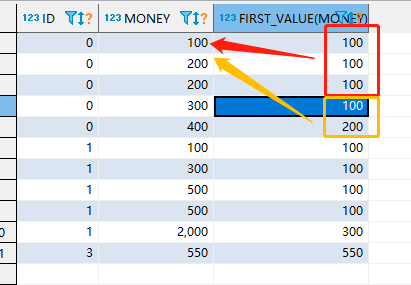
SELECT id,money,LAST_VALUE( money ) OVER( PARTITION BY id ORDER BY money ) FROM TEST1
首先我们来看一下运行结果:
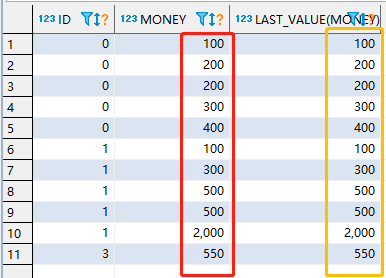
好像从上面我们看不出丝毫的变化,好像只是对对应的字段做了一个排序操作。好像和 FIRST_VALUE()函数有点不一样
如果我们要达到那种效果,我们需要做的操作如下:
SELECT id,money,FIRST_VALUE( money ) OVER( PARTITION BY id ORDER BY money desc) FROM TEST1
直接通过对money进行降序操作。然后达到我们预期的目标

(1)Java当中的method方法。这个是对id进行开平方操作。
select java_method("java.lang.Math","sqrt",cast(id as double)) from TEST1
除了这种我们可能用的比较多的函数就是下面这个
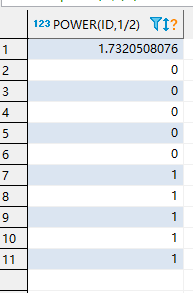
select power(id,1/2) from TEST1
power()函数可以对数据开平方,也可以做数据的二次方。
运行结果如下:
(1)cume_dist()
CUME_DIST 小于等于当前值的行数/分组内总行数–比如,统计小于等于当前薪水的人数,所占总人数的比例
select id,money, cume_dist() over (partition by id order by money) from TEST1
比如:我想统计工资在300以下的人占总人数的比例。具体的sql如下:
WITH mon AS (
select id,money, cume_dist() over (partition by id order by money) from TEST1
)
SELECT * FROM mon WHERE money=300
运行结果如下:

从这里我们可以看出,不同的id对应的工资少于300的人所占的比例在后面。
至此hive的窗口分析函数,总结如上面所示。