meizituSpider
抓取了meizitu萌妹板块的照片,基于BeautifulSoup4。
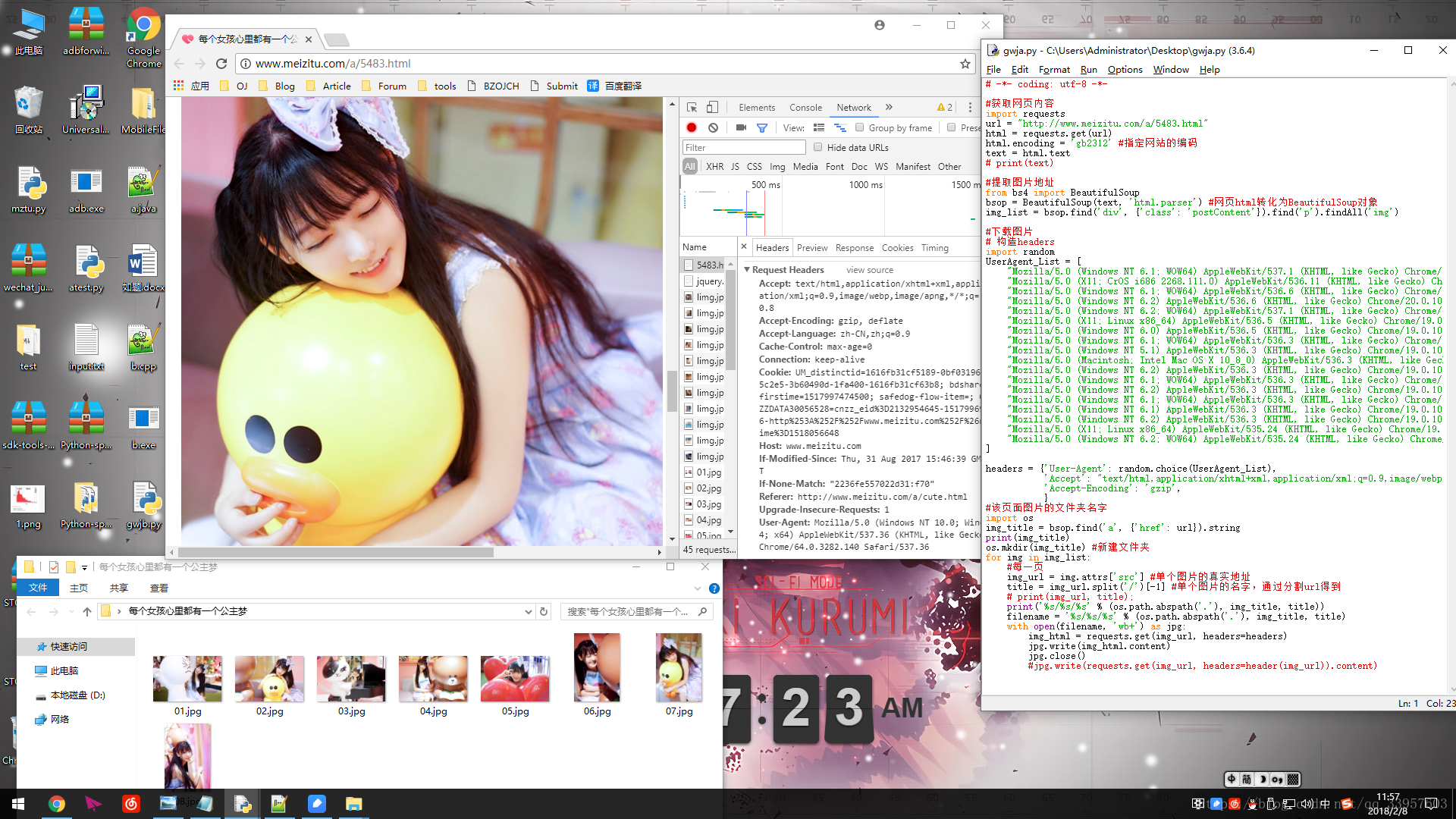
环境:
1、python3.6
2、pip install requests
3、pip install beautifulsoup4
参考资料:
WindwosPip报错:https://www.anaconda.com/download/
scrapy报错:http://blog.csdn.net/code_ac/article/details/71159244
Requests:http://docs.python-requests.org/zh_CN/latest/user/install.html#install
beautifulsoup:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#
Scrapy文档:http://scrapy-chs.readthedocs.io/zh_CN/0.24/index.html
lxml:http://lxml.de/
基础学习:
bs4:https://cuiqingcai.com/1319.html
runoob:http://www.runoob.com/python3/python3-tutorial.html
爬虫教程:
谢科入门:https://www.zhihu.com/question/20899988/answer/24923424
高野良:https://www.zhihu.com/question/20899988/answer/58388759
催庆才:https://cuiqingcai.com/3179.html
陈键冬:https://github.com/chenjiandongx/mzitu
yonggege:https://zhuanlan.zhihu.com/p/26304528?refer=zimei
额:https://zhuanlan.zhihu.com/p/25428493
等等等等。。。。
以下为教程v1.0:
0x10获取网页(得到html文本)
0x11背景知识:html基础
0x12背景知识:Requests, 获取网页的库。 文档传送门
0x13代码实现:
#1获取链接
import requests
url = "http://www.meizitu.com/a/4852.html"
html = requests.get(url) #响应的二进制
html.encoding = 'gb2312' #指定网站的编码
text = html.text0x20分析内容(提取图片地址)
0x21背景知识:beautifulsoup4 官方文档,民间教程
0x22背景知识:正则表达式 教程传送门
0x23代码实现:
#2 获取文本
from bs4 import BeautifulSoup
bsop = BeautifulSoup(text,'html.parser') #创建beautifulsoup4对象。
img_list = bsop.find('div',{'id':'picture'}).findAll('img')#img_list列表的对象是tag0x30保存图片
0x31背景知识:Http请求方法,教程传送门
0x32背景知识:os模块,传送门
0x33代码实现:
#3 下载图片
# 构造headers
import random
UserAgent_List = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
headers = {'User-Agent': random.choice(UserAgent_List),
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
'Accept-Encoding': 'gzip',
}
# 创建文件夹
import os
img_title = bsop.find('a',{'href':url}).string
os.mkdir(img_title)
# 保存每一张图片
count = 1
for img in img_list:
img_url = img.attrs['src'] #图片属性中的'src'标签
filename = '%s/%s/%s.jpg'%(os.path.abspath('.'),img_title,count)
with open(filename,'wb+')as jpg:
jpg.write(requests.get(img_url,headers=headers).content)
count += 10x40封装搞事【可以用的代码】
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import os
import random
UserAgent_List = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
headers = {'User-Agent': random.choice(UserAgent_List),
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
'Accept-Encoding': 'gzip',
}
#1 获取主页列表
def getPage(pageNum):
url = 'http://www.meizitu.com/a/cute_{}.html'.format(pageNum)
html = requests.get(url)
html.encoding = 'gb2312'
text = html.text
bsop = BeautifulSoup(text,'html.parser')
img_list = bsop.find('ul',{'class':'wp-list clearfix'}).findAll('a')
url_list = []
s = set()
for img in img_list:
if(img.attrs['href'] in s):continue
url_list.append(img.attrs['href'])
s.add(img.attrs['href'])
return url_list
# 2~3得到页面图片
def getImg(url):
#2 获取页面链接
html = requests.get(url)
html.encoding = 'gb2312'
text = html.text
bsop = BeautifulSoup(text,'html.parser')
imgs = bsop.find('div',{'id':'picture'}).findAll('img')
img_title = bsop.find('div',{'class':'metaRight'}).find('a').string #创建文件夹
os.mkdir(img_title)
#3 保存页面图片
count = 1
for img in imgs:
img_url = img.attrs['src']
filename = '%s/%s/%s.jpg'%(os.path.abspath('.'),img_title,count)
with open(filename,'wb+')as jpg:
jpg.write(requests.get(img_url,headers=headers).content)
count += 1
#0 主程序开始
if __name__ == '__main__':
pageNum = input(u'请输入页码:')
urls = getPage(pageNum)
for url in urls:
getImg(url)以及,丢到码云上了。