原文:[image classification notes]。
cs231n课程中的一篇介绍性教程,以下为阿幻的学习笔记:
照例,先摘个大纲:
- Intro to Image Classification, data-driven approach, pipeline
- Nearest Neighbor Classifier
- k-Nearest Neighbor
- Validation sets, Cross-validation, hyperparameter tuning(验证集, 交叉验证, 超参数调参)
- Pros/Cons of Nearest Neighbor(最近邻的优劣)
- Summary
- Summary: Applying kNN in practice
- Further Reading(拓展阅读)
介儿下边就是我的笔记喽.
Image Clssesfication
任务:图像分类就是从已有的固定分类标签集合中选择一个并分配给一张图像。
挑战:
- 视角变化(Viewpoint variation)
- 大小变化(Scale variation)
- 形变(Deformation)
- 遮挡(Occlusion)
- 光照条件(Illumination conditions):在像素层面上,光照的影响非常大。
- 背景干扰(Background clutter)
- 类内差异(Intra-class variation)
Data-driven approach
The image classification pipeline.(流程)
- Input: Our input consists of a set of N images, each labeled with one of K different classes. We refer to this data as the training set.
- Learning: Our task is to use the training set to learn what every one of the classes looks like. We refer to this step as training a classifier, or learning a model.
- Evaluation: In the end, we evaluate the quality of the classifier by asking it to predict labels for a new set of images that it has never seen before. We will then compare the true labels of these images to the ones predicted by the classifier. Intuitively, we’re hoping that a lot of the predictions match up with the true answers (which we call the ground truth).
Nearest Neighbor Classifier
Nearest Neighbor Classifier has nothing to do with Convolutional Neural Networks and it is very rarely used in practice.
基本思想是通过将测试图像与训练集带标签的图像进行比较,来给测试图像打上分类标签。
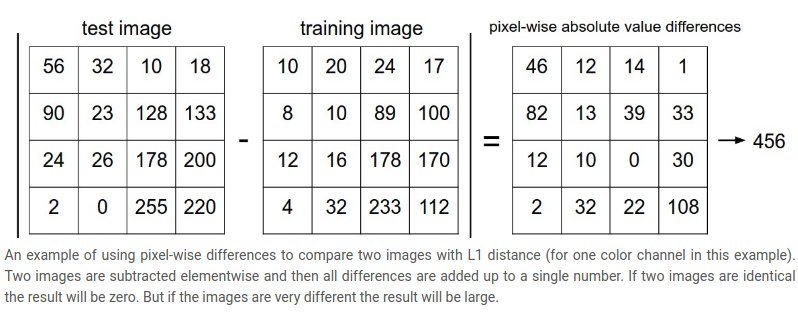
那么具体如何比较两张图片(像素块)呢?
最简单的方法就是逐个像素比较,最后将差异值全部加起来。换句话说,就是将两张图片先转化为两个向量和
,然后计算他们的L1 distance:
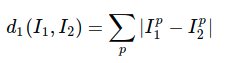
L2 distance, which has the geometric interpretation of computing the euclidean distance between two vectors. (几何学的角度,可以理解为它在计算两个向量间的欧式距离)
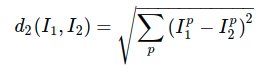
L1和L2比较。比较这两个度量方式是挺有意思的。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。L1和L2都是在p-norm常用的特殊形式。
k - Nearest Neighbor Classifier
k-Nearest Neighbor Classifier. The idea is very simple: instead of finding the single closest image in the training set, we will find the top k closest images, and have them vote on the label of the test image.

上面示例展示了Nearest Neighbor分类器和5-Nearest Neighbor分类器的区别。例子使用了2维的点来表示,分成3类(红、蓝和绿)。不同颜色区域代表的是使用L2距离的分类器的决策边界。白色的区域是分类模糊的例子(即图像与两个以上的分类标签绑定)。需要注意的是,在NN分类器中,异常的数据点(比如:在蓝色区域中的绿点)制造出一个不正确预测的孤岛。5-NN分类器将这些不规则都平滑了,使得它针对测试数据的泛化(generalization)能力更好(例子中未展示)。注意,5-NN中也存在一些灰色区域,这些区域是因为近邻标签的最高票数相同导致的(比如:2个邻居是红色,2个邻居是蓝色,还有1个是绿色)。
Validation sets for Hyperparameter tuning
hyperparameters(超参数)
Evaluate on the test set only a single time, at the very end.(决不能使用测试集来进行调优,测试数据集只使用一次,即在训练完成后评价最终的模型时使用)
不用测试集调优的方法思路是:从训练集中取出一部分数据用来调优,我们称之为验证集。把训练集分成训练集和验证集(validation set)。使用验证集来对所有超参数调优。最后只在测试集上跑一次并报告结果。
Cross-validation(交叉验证)
将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。

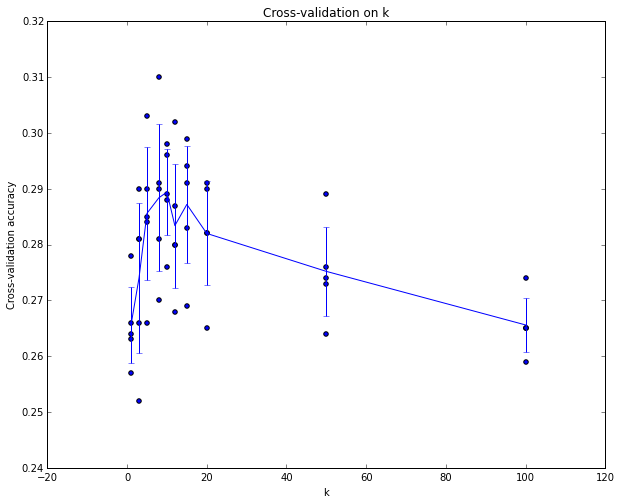
这就是5份交叉验证对k值调优的例子。针对每个k值,得到5个准确率结果,取其平均值,然后对不同k值的平均表现画线连接。本例中,当k=7的时算法表现最好(对应图中的准确率峰值)。如果我们将训练集分成更多份数,直线一般会更加平滑(噪音更少)。In
practice
交叉验证会耗费较多的计算资源。一般直接把训练集按照50%-90%的比例分成训练集和验证集。根据具体情况来定的:如果超参数数量多,你可能就想用更大的验证集,而验证集的数量不够,那么最好还是用交叉验证吧。至于分成几份比较好,一般都是分成3、5和10份。
Pros and Cons of Nearest Neighbor classifier.
优点: Nearest Neighbor分类器易于理解,实现简单。
缺点: (1) 测试花费的时间远远大于训练花费的时间.
算法的训练不需要花时间(因为其训练过程只是将训练集数据存储起来)。然而测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较。
Nearest Neighbor分类器的计算复杂度研究是一个活跃的研究领域,若干Approximate Nearest Neighbor (ANN)算法和库的使用可以提升Nearest Neighbor分类器在数据上的计算速度(比如:FLANN)。这些算法可以在准确率和时空复杂度之间进行权衡,并通常依赖一个预处理/索引过程,这个过程中一般包含kd树的创建和k-means算法的运用。(不懂,看看就好)
(2) Nearest Neighbor分类器在某些特定情况(比如数据维度较低)下,可能是不错的选择。但是在实际的图像分类工作中,很少使用。因为图像都是高维度数据(他们通常包含很多像素),而高维度向量之间的距离通常是反直觉的。下面的图片展示了基于像素的相似和基于感官的相似是有很大不同的:
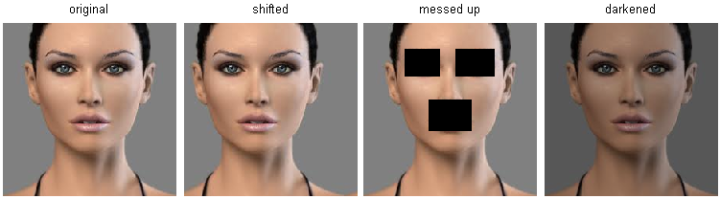
在高维度数据上,基于像素的的距离和感官上的非常不同。上图中,右边3张图片和左边第1张原始图片的L2距离是一样的。很显然,基于像素比较的相似和感官上以及语义上的相似是不同的。
原始图片的距离被背景主导而不是图片语义内容本身主导。
Summary
- 介绍了Image classesfication,即给定带有标签的图像数据集,预测没有标签的图片的类别和算法预测准确度.
- 介绍了Nearest Neighbor classifier,分类器中存在不同的超参数(比如k值或距离类型的选取)
- 选取超参数的正确方法是:将原始训练集分为训练集和验证集(validation set),我们在验证集上尝试不同的超参数,最后保留表现最好那个。
- 如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最优超参数的时候减少噪音。
- 一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
- 最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于耗费计算能力。
- 最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体分身。
Summary: Applying kNN in practice
如果你希望将k-NN分类器用到实处(最好别用到图像上,若是仅仅作为练手还可以接受),那么可以按照以下流程:
- 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。(本小节不讨论,是因为图像中的像素都是同质的,不会表现出较大的差异分布,也就不需要标准化处理了。)
- 如果数据是高维数据,考虑使用降维方法,比如PCA(wiki ref, CS229ref, blog ref)或随机投影。
- 将数据随机分训练集和验证集。按照一般规律,70%-90% 数据作为训练集。这个比例根据算法中有多少超参数,以及这些超参数对于算法的预期影响来决定。如果需要预测的超参数很多,那么就应该使用更大的验证集来有效地估计它们。如果担心验证集数量不够,那么就尝试交叉验证方法。如果计算资源足够,使用交叉验证总是更加安全的(份数越多,效果越好,也更耗费计算资源)。
- 验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
- 如果分类器跑得太慢,尝试使用Approximate Nearest Neighbor库(比如FLANN)来加速这个过程,其代价是降低一些准确率。
- 对最优的超参数做记录。记录最优参数后,千万不要在最终的分类器中使用验证集数据,这样做会破坏对于最优参数的估计。直接使用测试集来测试用最优参数设置好的最优模型,得到测试集数据的分类准确率,并以此作为你的kNN分类器在该数据上的性能表现。
拓展阅读
下面是一些你可能感兴趣的拓展阅读链接:
- A Few Useful Things to Know about Machine Learning,文中第6节与本节相关,但是整篇文章都强烈推荐。
- Recognizing and Learning Object Categories,ICCV 2005上的一节关于物体分类的课程。
demo
Example image classification dataset: CIFAR-10.(点击可以下载,记得下载python格式)
运行结果:
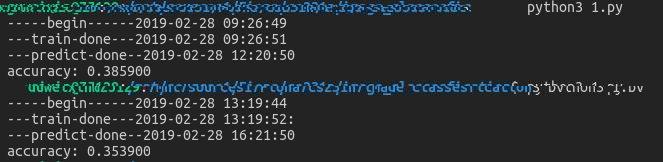
上面为L1距离, 下面是L2距离.
这个预测真的是慢,慢的我以为电脑卡死了(捂脸)
