目录:
一、hive简介
二、Hive语句的执行流程
三、hive和传统数据库的区别
一、Hive简介
1、什么是Hive:hive是一种基于hadoop的数据仓库,能够将结构化的数据映射成一张表,并提供HQL进行查询。其数据是存储在hdfs上,本质是将sql命令转化成MapReduce来执行。

2、Hive节点:用户接口,跨语言服务,元数据库,driver驱动
(1)用户接口:用户接口分为三种,第一种是cli,利用shell命令行操作;第二种是jdbc/odbc,使用sql进行操作;第三种是webui,在浏览器上访问hive。
(2)跨语言服务:一种软件框架,能让不同的语言调用hive的接口。
(3)元数据:存储hive数据的描述信息,例如:表名称和属性,表列和分区属性,表数据所在目录。这里的表属性一般指的是表是内部表还是外部表。
(4)驱动器Driver,编译器Compiler,优化器Optimizer,执行器Executor,Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行。
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器:编译器是将语法树编译为逻辑执行计划
(3) 优化器:优化器是对逻辑执行计划进行优化
(4) 执行器:执行器是调用底层的运行框架执行逻辑执行计划
3、Hive数据组织:
database数据库
table表
external table外部表
patition分区
bucket分桶
https://www.cnblogs.com/frankdeng/p/9381934.html
二、Hive语句的执行流程
1、查看执行流程:

查看hive语句的执行流程:explain select ….from t_table …;
- 查看hive语句的执行流程:explain select ….from t_table …;
- 操作符是hive的最小执行单元
- Hive通过execmapper和execreducer执行MapReduce程序,执行模式有本地模式和分布式模式
- 每个操作符代表一个 HDFS 操作或者 MapReduce 作业
hive的操作符: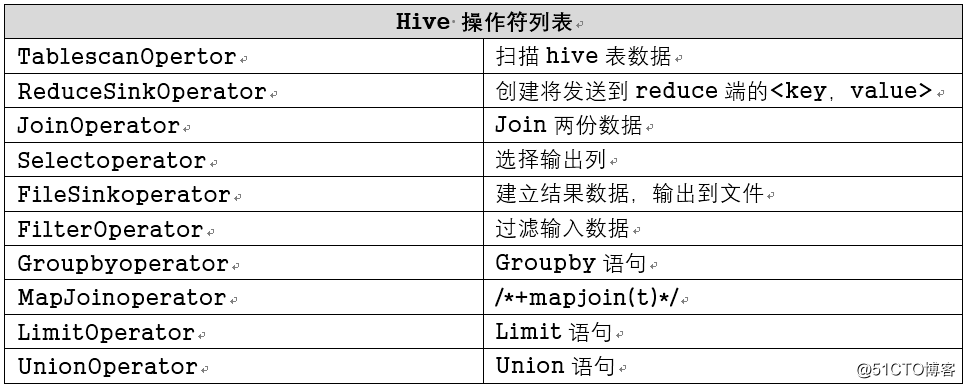
- Hive编译器的工作职责:
- Parser:将Hql语句转换成抽像的语法书(Abstract Syntax Tree)
- Semantic Analyzer:将抽象语法树转换成查询块
- Logic Plan Generator:将查询块,转换成逻辑查询计划
- Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划
- Physical Plan Gernerator:将逻辑执行计划转化为物理计划
- Physical Optimizer:选择最佳的join策略,优化物理执行计划
2、hive执行流程:

执行步骤:
1. 用户提交查询等任务给 Driver。
2. Compiler 编译器获得该用户的任务计划Plan。
3. Compiler 编译器根据用户任务去 MetaStore元数据库 中获取需要的Hive的元数据信息。
4. Compiler编译器 得到元数据信息,对任务进行编译,先将 HiveQL 转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
5. 将最终的计划提交给Driver。
6. Driver 将计划 Plan 转交给 ExecutionEngine执行引擎 去执行,获取元数据信息,提交给 JobTracker作业跟踪器 或者 SourceManager源管理器 执行该任务,任务会直接读取 HDFS 中文件进行相应的操作。
7. 获取执行的结果。
8. 取得并返回执行结果。
参考博客:https://blog.51cto.com/14048416/2342658
三、hive和传统数据库的区别
1、Hive和传统数据库的区别
(1)表数据验证:传统数据库是写模式,hive是读模式。传统数据库在写入数据的时候就去检查数据格式,hive在读取数据的时候检查。因此,写时模式,查询快,读时模式数据加载快。
(2)hive不支持实时处理,并且对索引支持较弱。
(3)hive不支持行级插入、更新、删除和事务。
(4)hive数据结构复杂,例如:数组、映射、结构体。
1、数据存储位置。Hive是建立在Hadoop之上的,所有的Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或本地文件系统中。
2、数据格式。Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:列分隔符,行分隔符,以及读取文件数据的方法。数据库中,存储引擎定义了自己的数据格式。所有数据都会按照一定的组织存储。
3、数据更新。Hive的内容是读多写少的,因此,不支持对数据的改写和删除,数据都在加载的时候中确定好的。数据库中的数据通常是需要经常进行修改。
4、执行延迟。Hive在查询数据的时候,需要扫描整个表(或分区),因此延迟较高,只有在处理大数据是才有优势。数据库在处理小数据是执行延迟较低。
5、索引。Hive没有,数据库有
6、执行。Hive是MapReduce,数据库是Executor
7、可扩展性。Hive高,数据库低
8、数据规模。Hive大,数据库小