前面的内容对netty进行了介绍,写了一个入门例子。作为一个netty的使用者,我们关注更多的还是业务代码。也就是netty中这两种组件:
ChannelHandler和ChannelPipeline---对应于NIO中的客户逻辑实现handleRead/handleWrite(interceptor pattern)
ByteBuf---- 对应于NIO 中的ByteBuffer
我们的业务逻辑要放在handler里面,读写数据用的是ByteBuf。其余的Transport、ServerBootstrap、Channel和EventLoop等等都是套路代码,对于应用程序来说,了解即可,基本上不用管。真正开发过netty项目也知道,项目中大部分都是handler类,其它组件只是占很少一部分。
Transport组件
netty做的比较有适应性的就是,不仅支持NIO,还支持很多传输协议:
OIO -阻塞IO(真正开发阻塞IO项目,其实也没必要用netty了。。。)
NIO -Java NIO
Epoll - Linux Epoll(JNI)
Local Transport - IntraVM调用(通讯的双方在同一个虚拟机之内不再走socket)
Embedded Transport - 供测试使用的嵌入传输
UDS- Unix套接字的本地传输(客户端和服务端都在同一个服务器上就可以使用,效率高)
使用不同个传输协议,只需要在通道里面设置不同的类型即可:

netty中的channel类型如下:
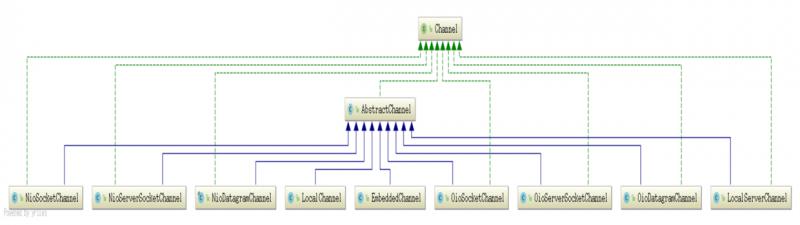
所以netty设置和改变传输协议都是一件很简单的事情。
EventLoopGroup和EventLoop组件
每个EventLoopGroup由多个EventLoop组成,并且多个EventLoop之间没有交互,各做各的事。
每个EventLoop对应一个线程(顶层继承Executor线程池,但是只有一个线程)
所有连接(channel)都将注册到一个EventLoop,并且只注册到一个,整个生命周期中都不会变化
每个EventLoop管理着多个连接(channel)
连接(Channel)上的读写事件是由EventLoop来处理的
服务端创建ServerBootstrap组件的时候,需要配置两个EventLoopGroup,parentGroup(也就是boss)负责处理Accept事件,接收请求,childGroup(也就是worker)负责处理读写事件。客户端的Bootstrap组件只需要一个EventLoopGroup即可。
ByteBuf组件
前面讨论NIO的时候,专门介绍过NIO的Buffer,相对于NIO,netty的ByteBuf更加易于使用:
为读/写分别维护单独的指针,不需要通过flip()进行读/写模式切换
容量自动伸缩(类似于ArrayList,StringBuilder)
Fluent API (链式调用)(ServerBootstrap 组件的配置方式就是链式调用)
除了使用上之外,netty的ByteBuf还拥有更好的性能:
通过内置的CompositeBuffer来减少数据拷贝(Zero copy)
支持内存池,减少GC压力
ByteBuf组件的操作
ByteBuf通过两个索引(reader index、writer index)划分为三个区域:
reader index前面的数据是已经读过的数据,这些数据可以丢弃
从reader index开始,到writer index之前的数据是可读数据
从writer index开始,为可写区域

来看下ByteBuf的主要操作,第一种就是顺序的读写(改变reader/writer index):
writeByte() - 写一个字节
writeLong() - 写八个字节
writeXXX() - 所有write方法会让write index 往前走
readByte() - 读一个字节
readLong() - 读八个字节
readXXX() - 所有read方法会让read index往前走
第二种就是随机读写(不改变read/write index):
getXXX(index)
setXXX(index, byte)
前面NIO中的Buffer操作用,有mark和reset方法,用来标记操作的状态,恢复状态,netty中也有类似的方法:
markReaderIndex()
markWriterIndex()
resetReaderIndex()
resetWriterIndex()
writerIndex(index) - 把write index 放置到参数中的index上面
readerIndex(index) - 把reader index放置到参数中的index上面
reader index前面的部分是已经读过的是不是浪费掉了?netty提供了discardReadBytes方法,把reader index前面的内容丢弃掉,就是把reader index后面的数据往前拷贝,这样空间就可以再利用了。这个方法和前面NIO中的compact方法类似。还有一个方法就是clear方法,把所有数据都清零,读索引和写索引归零:

netty的ByteBuf中还提供了查询方法:
indexOf
bytesBefore
forEachByte(ByteBufProcessor)
查询方法有很多应用,比如在信息中有某个字符的存在,就需要做一些操作,比如每碰到一个换行,就发送一条信息,这种功能在聊天中用的很多。
netty中还有一种衍生缓冲区,就是Derived Buffers,可以理解为类似数据库的视图,是从ByteBuf中衍生出来的,衍生缓冲区与ByteBuf共享底层的存储空间,但是它们两个各自具有各自的index和mark,衍生缓冲区(Derived Buffers)主要的方法:
duplicate()
slice()
slice(start, stop)
nmodifiableBuffer(...),
衍生缓冲区(Derived Buffers)是一种浅拷贝,如果要进行深拷贝怎么用?使用copy或者 copy(int, int) 方法,会返回有独立数据副本的ByteBuf。
ByteBuf组件的类型
根据内存的位置,ByteBuf的类型可以分为HeapByteBuf和DirectByteBuf,这和NIO中的Buffer是一样的,HeapByteBuf位置在堆上,底层基于数组-内部为一个字节数组(byte array),调用hasArray()方法会返回True,调用array()方法返回其内部的数组,可以对数组进行直接操作。DirectByteBuf的位置在堆外内存,可以减少拷贝,具有更好的性能,但是创建和释放的开销更大。Java写网络程序经常分成两个部分,第一个是IO部分,读数据解码等,这些部分用DirectByteBuf效率比较高,因为这部分涉及到向网络发送数据需要拷贝。如果是其它业务相关的部分,可以使用HeapByteBuf。
根据是否使用内存池,ByteBuf的类型可以分为Pooled和Unpooled两种ByteBuf,Unpooled就是不用池,每次都去创建,Pooled类型就是会申请一块内存池,每次分配都从池中分配,每次释放都放回池中。这种主要是针对DirectByteBuf创建和释放开销大来制定的策略,提供一个内存池可以提高效率,减少内存碎片,减少GC压力,这种在NIO的Buffer中是没有的。
根据是否使用Unsafe操作,ByteBuf的类型可以分为Safe和Unsafe两种,我们知道JDK中有个Unsafe类,很多JDK中并发操作的源码中都用到了这个Unsafe类。直接new可以创建一个safe的ByteBuf,如果创建Unsafe类型可以直接用Unsafe类操作,效率上有一点点提升,不过这些都是底层操作大家了解即可,而且也不是所有平台都支持Unsafe操作。
ByteBuf还有一种复合缓冲区(CompositeByteBuf),它是由多个ByteBuf组合成的视图,是一个ByteBuf列表,可动态的添加和删除其中的ByteBuf。在其中可能既包含堆缓冲区,也包含直接缓冲区。
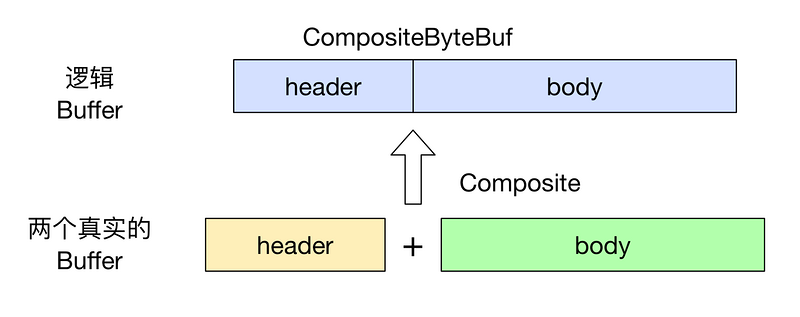
netty把这种结构也解释为一种零拷贝,虽然不是严格意义上的零拷贝,但是确实可以提高效率。
来看另外一个接口ByteBufHolder,里面包含了一个ByteBuf,除此之外,还另外存储一些元数据的属性值。当要拿到里面包含的ByteBuf的时候,就可以拿到这些数据。

比如定义一个数据包的时候,就可以实现这个接口,真正的内容放在ByteBuf里面。
ByteBuf组件的创建
创建的时候,并不需要执行new操作,而是通过ByteBufAllocator分配器来创建,分配器有两个实现,分别是UnpooledByteBufAllocator和PooledByteBufAllocator,从名字可以看出,分配方式就是是否使用内存池的区别。
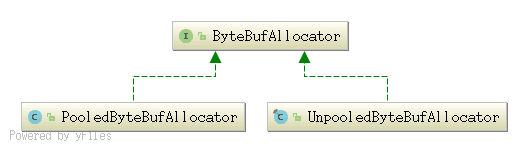
主要的方法如下:

为了简化非池化创建,netty提供了 Unpooled 的工具类,它提供了静态的辅助方法来创建未池化的ByteBuf实例,内部也包含了UnpooledByteBufAllocator的使用,我们创建非池化的ByteBuf直接用工具类即可,主要方法如下:

我们前面介绍netty入门例子的时候,服务端的读取操作完毕的方法中也用到了这个工具类创建一个空ByteBuf:

而且在客户端也用到了,

Unpooled.copiedBuffer方法就是说创建一个ByteBuf,然后把创建的字符串拷贝到ByteBuf中去。
ByteBuf组件随机读写的示例程序
上面介绍了很多特性和操作,下面看一个示例程序,随机读写,不改变读写指针的例子:
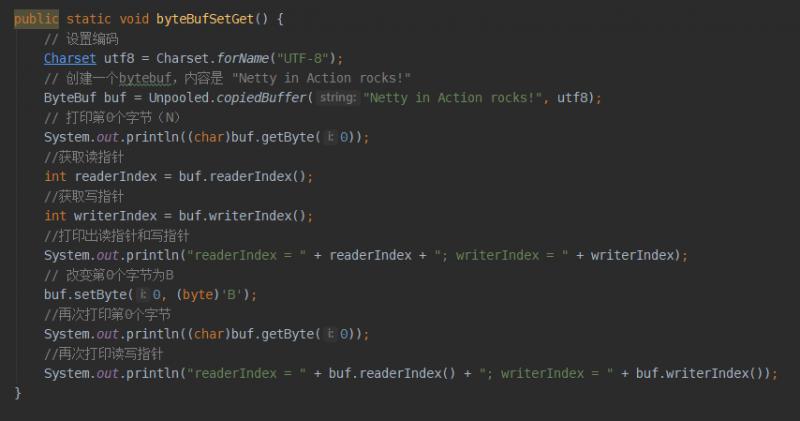
上面的每行代码都有注释,我们看一下结果:
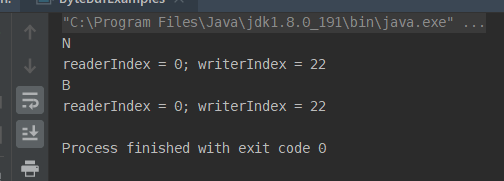
确实指针没有改变。这里我们注意获取读写指针用的方法,和随机读写操作用的方法,以及如何创建的ByteBuf。
ByteBuf组件顺序读写的示例程序
我们再来看一个顺序读写的例子:
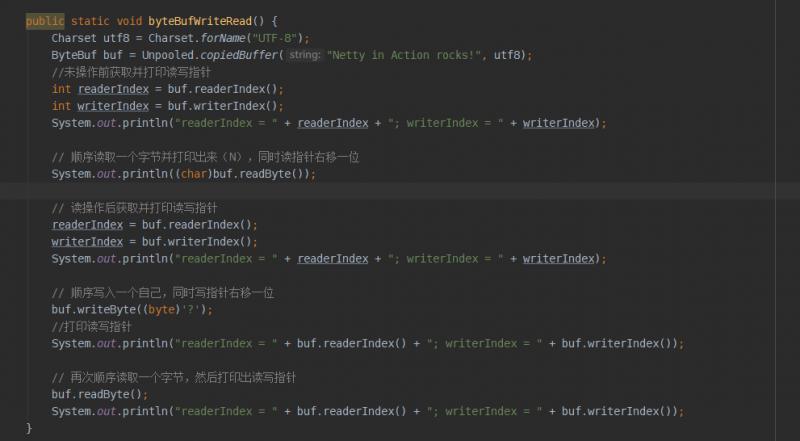
来看打印结果:
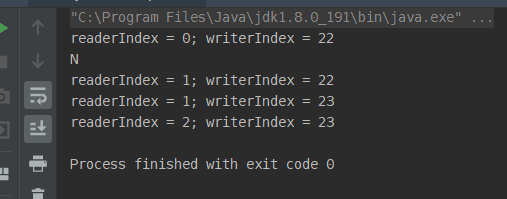
这里除了创建ByteBuf的方式要注意,还要注意顺序读写的方法。
ByteBuf组件顺序读写Int数据的示例程序
来看一个顺序读写int类型数据的示例:
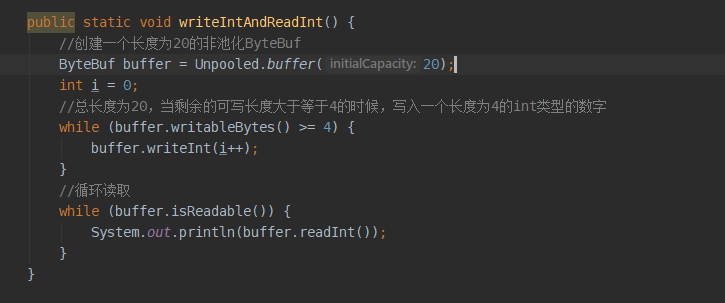
总长度为20写入int数据只能写5个,我们看打印读取的内容:

除了int数据,其它类型大家也可以试试。
ByteBuf组件获取对应字符位置的示例程序
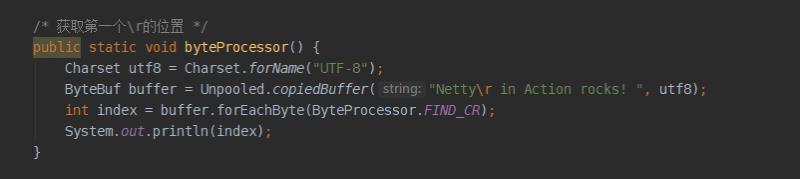
ByteProcessor类中定义了很多特殊字符,有兴趣可以看看。来看一下打印效果:
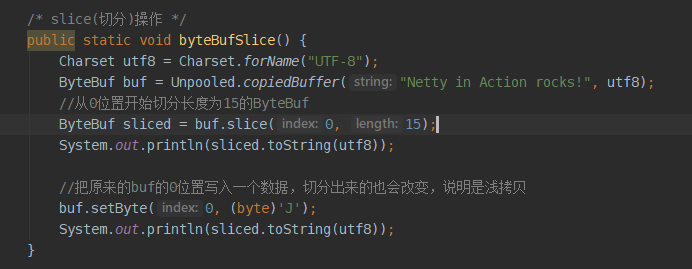
ByteBuf组件slice操作的示例程序
我们看一下打印结果:

注意slice方法两个参数的意义和如何把ByteBuf转换为字符串。
ByteBuf组件copy深拷贝的示例程序
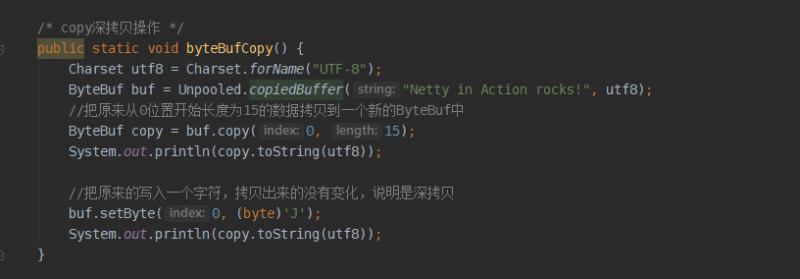
注意copy方法的用法,来看打印结果:
ByteBuf组件复合缓冲区的示例程序
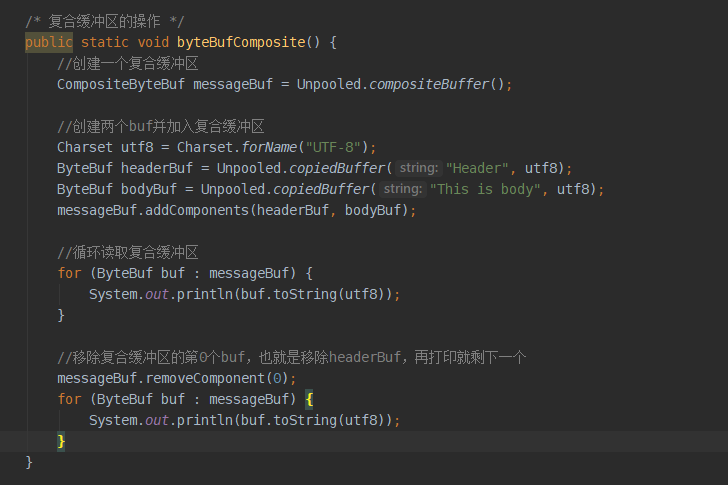
注意复合缓冲区的创建和操作,来看打印结果:
ByteBuf组件堆上创建和操作的示例程序
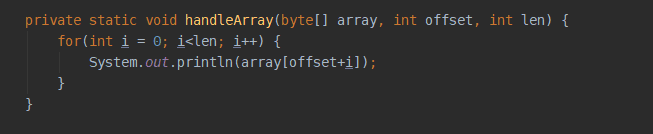
来看一下循环打印的代码:
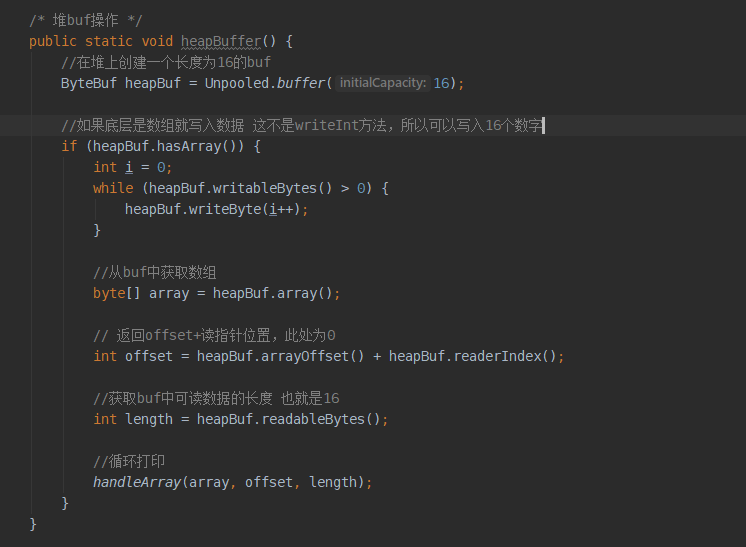
连看一下结果:
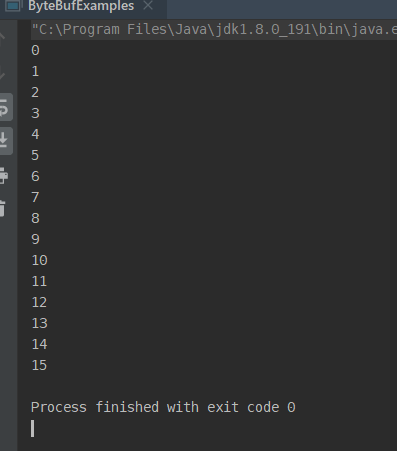
ByteBuf组件堆外创建和操作的示例程序
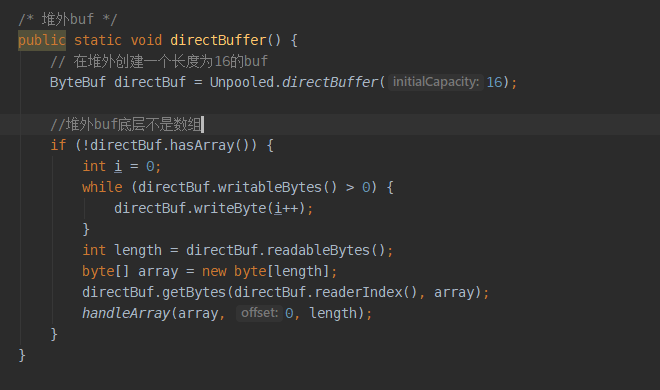
逻辑上和堆上的方法一样,来看一下打印结果:
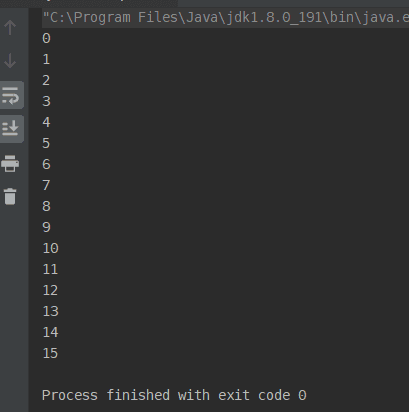
代码地址:https://gitee.com/blueses/netty-demo 06
本文由博客一文多发平台 OpenWrite 发布!