Task04:机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer
学习笔记见:https://www.cnblogs.com/guohaoblog/p/12324983.html
机器翻译及其技术
1、数据预处理中分词(Tokenization)的工作是?
A、把词语、标点用空格分开
B、把字符形式的句子转化为单词组成的列表
C、把句子转化为单词ID组成的列表
D、去除句子中的不间断空白符等特殊字符
解析:选B
# 将text中句子转化为源语言单词列表和目标语言单词列表
num_examples = 50000 source, target = [], [] for i, line in enumerate(text.split(' ')): if i > num_examples: break parts = line.split(' ') if len(parts) >= 2: source.append(parts[0].split(' ')) target.append(parts[1].split(' ')) source[0:3], target[0:3] --------------------------------------- Out: ([['go', '.'], ['hi', '.'], ['hi', '.']], [['va', '!'], ['salut', '!'], ['salut', '.']])
2、不属于数据预处理工作的是?
A、得到数据生成器
B、建立词典
C、分词
D、把单词转化为词向量
答案:D
文本预处理步骤:①读入文本 ②分词 ③建立字典(词典)
单词转化为词向量是模型结构的一部分,词向量层一般作为网络的第一层
3、下列不属于单词表里的特殊符号的是?
A、未知单词
B、空格符
C、句子开始符
D、句子结束符
答:选B
数据预处理时,空格一般会被处理掉。本课时讲的特殊符有:<bos> <eos> <unk>
4、集束搜索(Beam Search)说法错误的是
A、集束搜索结合了greedy search和维特比算法。
B、集束搜索使用beam size参数来限制在每一步保留下来的可能性词的数量。
C、集束搜索是一种贪心算法。
D、集束搜索得到的是全局最优解。
答:选择D
贪心算法(greedy search)

维特比算法:选择整体分数最高的句子(搜索空间太大) 集束搜索:
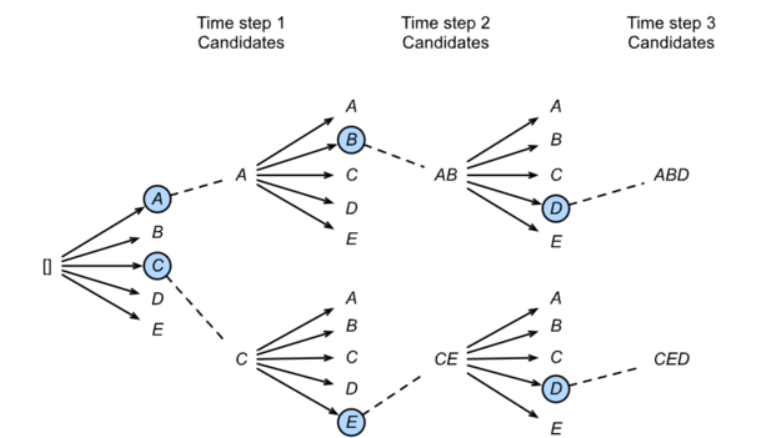
从A~E中选择概率最大的两个,得到A、C,再求与A、C相邻的最大概率两个,以此类推,最后可得到两个序列,找出最大的一个。不是全局搜索,全局搜索相当于把每个节点都检索一遍,并计算,比较耗时。维特比是启发式(或贪心)的算法
5、不属于Encoder-Decoder应用的是
A、机器翻译
B、对话机器人
C、文本分类任务
D、语音识别任务
答:选择C
Encoder-Decoder常应用于输入序列和输出序列的长度是可变的,如选项一二四,而分类问题的输出是固定的类别,不需要使用Encoder-Decoder
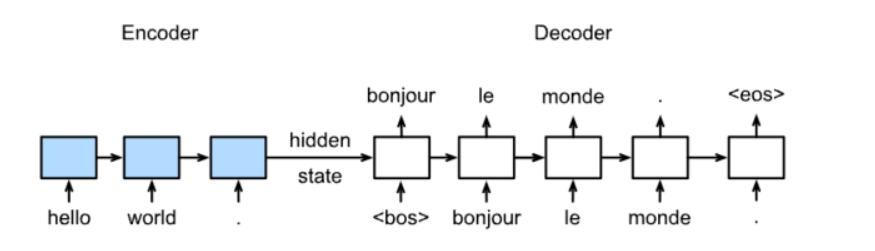
6、关于Sequence to Sequence模型说法错误的是
A、训练时decoder每个单元输出的单词作为下一个单元的输入单词
B、预测时decoder每个单元输出得到的单词作为下一个单元的输入单词
C、预测时decoder单元输出为句子结束时跳出循环
D、每个batch训练时encoder和decoder都有固定长度的输入。
答:选择A
训练
预测
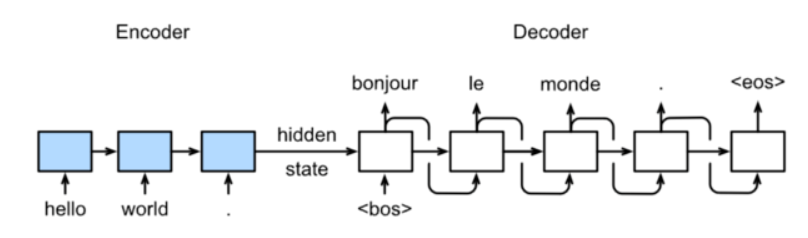
每个batch训练时encoder和decoder都有固定长度的输入,每个batch输入需要形状一致。
注意力机制与Seq2seq模型
1、以下对于注意力机制叙述错误的是:
A、注意力机制借鉴了人类的注意力思维方式,以获得需要重点关注的目标区域。
B、在计算注意力权重时,key 和 query 对应的向量维度需相等。
C、点积注意力层不引入新的模型参数。
D、注意力掩码可以用来解决一组变长序列的编码问题。
答:选择B
在Dot-product Attention中,key与query维度需要一致,在MLP Attention中则不需要。
2、以下对于加入Attention机制的seq2seq模型的陈述正确的是:
A、seq2seq模型不可以生成无穷长的序列。
B、每个时间步,解码器输入的语境向量(context vector)相同
C、解码器RNN仍由编码器最后一个时间步的隐藏状态初始化。
D、引入注意力机制可以加速模型训练。
答:选择C
A项:seq2seq模型的预测需人为设定终止条件,设定最长序列长度或者输出[EOS]结束符号,若不加以限制则可能生成无穷长度序列
B项:不同,每个位置都会计算各自的attention输出
D项:注意力机制本身有高效的并行性,但引入注意力并不能改变seq2seq内部RNN的迭代机制,因此无法加速。
3、关于点积注意力机制描述错误的是:
A、高维张量的矩阵乘法可用于并行计算多个位置的注意力分数。
B、计算点积后除以![]() 以减轻向量维度对注意力权重的影响。
以减轻向量维度对注意力权重的影响。
C、可视化注意力权重的二维矩阵有助于分析序列内部的依赖关系。
D、对于两个有效长度不同的输入序列,若两组键值对完全相同,那么对于同一个query的输出一定相同。
答: 选择D
有效长度不同导致 Attention Mask 不同,屏蔽掉无效位置后进行attention,会导致不同的输出。
现在我们创建了两个批,每个批有一个query和10个key-values对。我们通过valid_length指定,对于第一批,我们只关注前2个键-值对,而对于第二批,我们将检查前6个键-值对。因此,尽管这两个批处理具有相同的查询和键值对,但我们获得的输出是不同的。
atten = DotProductAttention(dropout=0) keys = torch.ones((2,10,2),dtype=torch.float) values = torch.arange((40), dtype=torch.float).view(1,10,4).repeat(2,1,1) atten(torch.ones((2,1,2),dtype=torch.float), keys, values, torch.FloatTensor([2, 6]))
# attention_weight # tensor([[[0.5000, 0.5000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, # 0.0000, 0.0000]], # [[0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.0000, 0.0000, # 0.0000, 0.0000]]])
输出:
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]], [[10.0000, 11.0000, 12.0000, 13.0000]]])
Transformer
1、关于Transformer描述正确的是:
A、在训练和预测过程中,解码器部分均只需进行一次前向传播。
B、Transformer 内部的注意力模块均为自注意力模块。
C、解码器部分在预测过程中需要使用 Attention Mask。
D、自注意力模块理论上可以捕捉任意距离的依赖关系。
答:选择D
A项:训练过程1次,预测过程要进行句子长度次
B项:Decoder 部分的第二个注意力层不是自注意力,key-value来自编码器而query来自解码器
C项:不需要
D项:正确,因为自注意力会计算句子内任意两个位置的注意力权重
2、在Transformer模型中,注意力头数为h,嵌入向量和隐藏状态维度均为d,那么一个多头注意力层所含的参数量是:
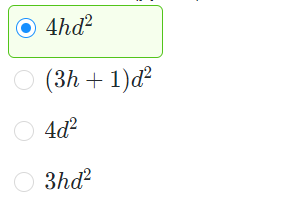
答:参考MultiHeadAttention模块的定义。

h个注意力头中,每个的参数量为3d^2,最后的输出层形状为h×d ×d,所以参数量共为4hd^2。
3、下列对于层归一化叙述错误的是:
A、层归一化有利于加快收敛,减少训练时间成本
B、层归一化对一个中间层的所有神经元进行归一化
C、层归一化对每个神经元的输入数据以mini-batch为单位进行汇总
D、层归一化的效果不会受到batch大小的影响
答: 选择C
批归一化(Batch Normalization)才是对每个神经元的输入数据以mini-batch为单位进行汇总。
补充:Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。这里 Layer Norm 与7.5小节的Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。