此篇为学习过程中遇到的问题及解决方法,将不定期更新~~
[[ ]]模式匹配

如上述要求,可用[[]]所支持的字符串模式匹配来实现,一般格式是[[变量==模式]]意为变量是否匹配到模式,是为真,否为假(切记,在==两边留空格)。
[root@server24 shell]# test=APIabcdef
[root@server24 shell]# [[ "$test" == API* ]] && echo OK! || echo FAILD!
OK!
[root@server24 shell]# test=APBabcdef
[root@server24 shell]# [[ "$test" == API* ]] && echo OK! || echo FAILD!
FAILD!
grep
egrep = grep -E
在文本中多条件匹配一般可以用egrep ‘A|B’ FILE,但是这种方法并不能精确匹配到字符串AB同时出现在某一行,如果需要字符串同时匹配可用通配符:grep -E ‘A.*B|B.*A’ FILE 。 如果次序固定,那么就简单多了,直接用grep‘A.*B’ FILE就可。
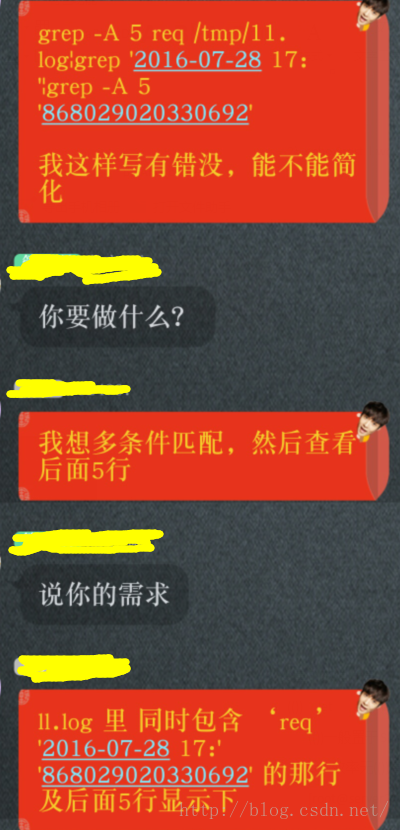
如上图需求,次序是固定的,那么用起来就似乎容易多了
grep -E -A5 'req|2016-07-28 17:|868029020330692' /tmp/11.log
awk
1.现有hosts文件如下:
1.1.1.1 hp-1
1.1.1.2 hp-2
1.1.10.1 hp-003
1.1.10.2 hp-004
1.1.1.10 dell-001
1.1.1.11 dell-002
1.1.1.20 IBM-003
1.1.1.30 IBM-004
2.2.10.1 hp-005
2.2.10.2 hp-006
2.2.10.100 dell-010
3.3.3.200 IBM-005
要求1)实现效果如下:
1.1.1.1 hp-1 hp-000
1.1.1.2 hp-2 hp-001
1.1.10.1 hp-003 hp-002
1.1.10.2 hp-004 hp-003
1.1.1.10 dell-001 dell-004
1.1.1.11 dell-002 dell-005
1.1.1.20 IBM-003 IBM-006
1.1.1.30 IBM-004 IBM-007
2.2.10.1 hp-005 hp-008
2.2.10.2 hp-006 hp-009
2.2.10.100 dell-010 dell-010
3.3.3.200 IBM-005 IBM-011
要求2)实现效果如下:
1.1.1.1 hp-1 hp-129
1.1.1.2 hp-2 hp-130
1.1.10.1 hp-003 hp-131
1.1.10.2 hp-004 hp-132
1.1.1.10 dell-001 dell-129
1.1.1.11 dell-002 dell-130
1.1.1.20 IBM-003 IBM-131
1.1.1.30 IBM-004 IBM-132
2.2.10.1 hp-005 hp-133
2.2.10.2 hp-006 hp-134
2.2.10.100 dell-010 dell-138
3.3.3.200 IBM-005 IBM-133
针对要求1)要求2)的思路是将其分为ip、hostname两块,然后将hostname以'-'为分隔符拆分为两部分,然后重组。可以发现在要求1)里面number是从000开始的,要求2)里number是+128。所以实现如下:
1)awk '{split($2,i,"-");count[i[1]]++}{printf "%s %s%s%03d ",$0,i[1],"-",NR-1}' hosts
2)awk '{split($2,i,"-");count[i[1]]++}{print $0" "i[1]"-"i[2]+128}' hosts
2.将如下字符串
stu494
e222f
stu495
bedf3
stu496
92236
stu497
49b91
转为如下格式
stu494=e222f
stu495=bedf3
stu496=92236
stu497=49b91
实现如下:
[root@server23 ~]# cat 3.log |awk '{if(NR%2!=0){a=$0;next}print a"="$0}'
stu494=e222f
stu495=bedf3
stu496=92236
stu497=49b91
3.将/etc/passwd中每个字符的个数,将字符数量前10按个数排序
[root@server23 ~]# cat /etc/passwd | awk -v FS="" '{for(i=1;i<=NF;i++)a[$i]++}END{for(j in a)print a[j],j}'|sort -nr |head
150 :
98 /
85 n
78 o
60 s
60 i
52 a
41 l
39 e
38 b