原文:左值和右值_linuxheik的专栏-CSDN博客_左值和右值
左值引用,也就是“常规引用”,不能绑定到要转换的表达式,字面常量,或返回右值的表达式。而右值引用恰好相反,可以绑定到这类表达式,但不能绑定到一个左值上。
右值引用就是必须绑定到右值的引用,通过&&获得。右值引用只能绑定到一个将要销毁的对象上,因此可以自由地移动其资源。
返回左值的表达式包括返回左值引用的函数及赋值,下标,解引用和前置递增/递减运算符,返回右值的包括返回非引用类型的函数及算术,关系,位和后置递增/递减运算符。可以看到左值的特点是有持久的状态,而右值则是短暂的。
1. 左值和右值
(1)两者区别:
①左值:能对表达式取地址、或具名对象/变量。一般指表达式结束后依然存在的持久对象。
②右值:不能对表达式取地址,或匿名对象。一般指表达式结束就不再存在的临时对象。
(2)右值的分类
①将亡值(xvalue,eXpiring value):指生命期即将结束的值,一般是跟右值引用相关的表达式,这样表达式通常是将要被移动的对象,如返回类型为T&&的函数返回值(如std::move)、经类型转换为右值引用的对象(如static_cast<T&&>(obj))、xvalue类对象的成员访问表达式也是一个xvalue(如Test().memberdata,注意Test()是个临时对象)
②纯右值(prvalue, PureRvalue):按值返回的临时对象、运算表达式产生的临时变对象、原始字面量和lambda表达式等。
(3)C++11中的表达式
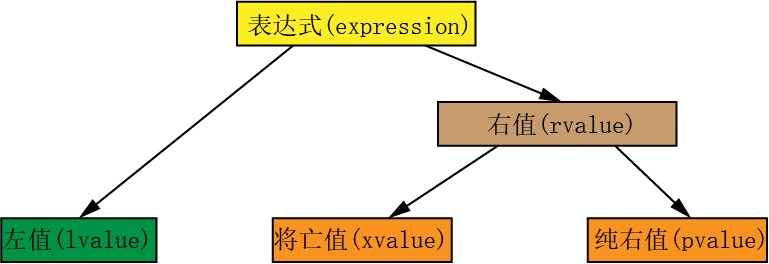
①表达式是由运算符(operator)和运算对象(operand)构成的计算式。字面值和变量是最简单的表达式,函数的返回值也被认为是表达式。
②表达式是可求值的,对表达式求值将得到一个结果,这个结果有两个属性:类型和值类别,而表达式的值类别必属于左值、将亡值或纯右值三者之一。
③“左值”和“右值”是表达式结果的一种属性。通常用“左值”来指代左值表达式,用“右值”指代右值表达式。
2. 右值引用和左值引用
(1)右值引用和左值引用
①右值引用和左值引用都是属于引用类型。无论是声明一个左值引用还是右值引用,都必须立即进行初始化。
②左值引用是具名变量/对象的别名,右值引用是匿名变量/对象的别名。
③左值和右值是独立于它的类型的,即左右值与类型没有直接关系,它们是表达式的属性。具名的右值引用是左值,匿名的右值引用是右值。如Type&& t中t是个具名变量(最简单的表达式),t的类型是右值引用类型,但具有左值属性。而Type&& func()中的返回值(是个表达式)是右值引用类型,但具有右值属性(因为是个匿名对象)。
(2)C++中引用类型及其可以引用的值类别
|
引用类型 |
可以引用的值类别 |
备注 |
|||
|
非常量左值 |
常量左值 |
非常量右值 |
常量右值 |
||
|
Type& |
Y |
N |
N |
N |
只能绑定到非常量左值 |
|
const Type& |
Y |
Y |
Y |
Y |
万能类型、用于拷贝语议 |
|
Type&& |
N |
N |
Y |
N |
只能绑定到右值。用于移动语义和完美转发 |
|
const Type&& |
N |
N |
Y |
Y |
暂无用途 |
①常量左值引用是个“万能”的引用类型。它可以接受非常量左值、常量左值、右值对其进行初始化。
②常量左值引用可以使用右值进行初始化,这时它可以像右值引用一样将右值的生命期延长。不过相比于右值引用所引用的右值,常量左值所引用的右值在它的“余生”中只能是只读的。
【编程实验】左、右值引用

#include <iostream>
#include <type_traits>
//编译选项:g++ -std=c++11 test1.cpp -fno-elide-constructors
using namespace std;
//左/右值以及左/右值引用
struct Test
{
int m;
public:
Test(){cout << "Test()" << endl;}
Test(const Test& t){cout << "Test(const Test&)" << endl;}
Test(Test&& t){cout << "Test(Test&&)" << endl;}
~Test(){cout << "~Test()" << endl;}
};
Test&& func()
{
return Test(); //不安全!返回局部对象的引用(用于演示)!
}
Test ReturnRvalue()
{
return Test();
}
int main()
{
//1. 左、右值判断
int i = 0;
int&& ri = i++; //i++为右值,表达式返回是i的拷贝,是个匿名变量。故为右值。
int& li = ++i; //++i返回的是i本身,是具名变量,故为左值。
int* p = &i;
int& lp = *p; //*p是左值,因为可以取*p的地址,即&(*p);
int* && rp = &i; //取地址表达式结果是个地址值,故&i是纯右值。
int&& xi1 = std::move(i); //std::move(i)是个xvalue
int&& xi2 = static_cast<int&&>(i); // static_cast<int&&>(i)是个xvalue
auto&& fn = [](int x){ return x * x; }; //lambda表达式是右值,可以用来初始化右值引用
cout << std::is_rvalue_reference<decltype(fn)>::value << endl; //1
Test t;
int& rm1 = t.m; //由于t是左值,而m为普通成员变量,所以m也为左值。
int&& rm2 = Test().m; //由于Test()是个右值,所以m也是右值
int Test::*pm = &Test::m; //定义指向成员变量的指针,指向non-static member data;
//int&& rm3 = t.*pm; //error,由于t是左值,*pm也是左值,不能用来初始化右值引用。
int& rm3 = t.*pm; //ok
int&& rm4 = Test().*pm; //ok,Test()是临时变量,为右值。所以*pm也是右值
//2. 左/右值引用的初始化
int a;
int& b = a; //ok
//int&& b = a; //error,右值引用只能绑定到右值上
Test&& t1 = ReturnRvalue(); //返回值是个临时对象(右值) 被绑定到t1上,使其“重获新生”,
//生命期与t1一样。
Test t2 = ReturnRvalue(); //返回值是个临时对象(右值),用于构造t2,之后该临时对象
//就会马上被释放。
//Test& t3 = ReturnRvalue(); //普通左值引用不能绑定到右值
const Test& t4 = ReturnRvalue(); //常左值引用是个“万能引用”,可以绑定到右值
//system("pause");
return 0;
}
3. universal引用(T&&)
(1)T&&的两种含义
①右值引用:当T是确定的类型时,T&&为右值引用。如int&& a;
②当T存在类型推导时,T&&为universal引用,表示一个未定的引用类型。如果被右值初始化,则T&&为右值引用。如果被左值初始化,则T&&为左值引用。
(2)引用折叠
①由于引用本身不是一个对象,C++标准不允许直接定义引用的引用。如“int& & a = b;”(注意两个&中间有空格,不是int&&)这样的语句是编译不过的。
②当类型推导时可能会间接地创建引用的引用,此时必须进行引用折叠。具体折叠规则如下:
A. X& &、X& &&和X&& &都折叠成类型X&。即凡是有左值引用参与的情况下,最终的类型都会变成左值引用。
B. 类型X&& &&折叠成X&&。即只有全部为右值引用的情况才会折叠为右值引用。
③引用折叠规则暗示我们,可以将任意类型的实参传递给T&&类型的函数模板参数。
(4)注意事项
①只有当发生自动类型推导时(如函数模板的类型自动推导或auto关键字),&&才是一个universal引用。当T的类型是确定的类型时,T&&为右值引用。
②当使用左值(类型为A)去初始化T&& t时,类型推导为A& &&,折叠会为A&,即t的类型为左值引用。而如果使用右值初始化T&&时,类型推导为A&&,一步到位无须折叠。
③universal引用仅仅在T&&下发生,任何一点附加条件都会使之失效,而变成一个普通的右值引用(const T&&被const修饰就成了右值引用)
【编程实验】引用折叠
#include <iostream>
#include <vector>
using namespace std;
//编译选项:g++ -std=c++11 test2.cpp
class Widget{};
template<typename T>
class Foo
{
public:
typedef T&& RvalueRefToT; //RvalueRefToT为universal引用
};
//universal引用: T&&存在类型推导
template<typename T>
void func(T&& param) //存在类型推导param为universal引用
{};
//非universal引用:形参必须是严格的T&&格式。
template<typename T>
void func(vector<T>&& param){}; //param是一个右值引用,因为当给func传入实参时,T被推导后vector<T>&&的类型是确定的。
//非universal引用:形参必须是严格的T&&格式。
//哪怕被const修饰也不行
template<typename T>
void func(const T&& param); //param是一个右值引用
//比较universal引用和右值引用
//假设实例化后为:Vector<Widget> v;
template<class T, class Allocator=allocator<T>>
class Vector{
public:
//虽然push_back的形参符合T&&格式,但不是universal引用因为Vector实例化后,push_back的形参类型就确定下来
//所以在调用时push_back函数时并不存在类型推导。
void push_back(T&& x);
//Arg&&存在类型推导,所以args的参数是universal引用。因为参数Args独立于vector的类型参数T,所以每次emplace_back被调用的时候,Args必须被推导。
template<class ...Args>
void emplace_back(Args&&...args);
};
int main()
{
void f(Widget&& param); //没有类型推导,param为右值引用
Widget&& var1 = Widget(); //没有类型推导,var1为右值引用
//1. auto中可能发生引用折叠
auto&& var2 = var1; //存在类型推导,var2为universal引用。var2被左值初始化,auto被推导为Widget& &&,折叠后为Widget&
int w1, w2;
auto&& v1 = w1; //v1是universal引用。被左值初始化,所以其类型为int&
auto&& v2 = std::move(w1);//v2为universal引用,被右值初始化,所以类型为int&&
//2. decltype中可能发生引用折叠:decltype(x)会先取出x的类型,再通过引用折叠规则来定义变量
decltype(v1)&& v3 = w2; //v1的类型为int&,所以v3为int& &&,折叠后为int&
decltype(v2)&& v4 = std::move(w2); //v2的类型为int&&,所以v4为int&& &&,折叠后为int&&
decltype(w1)&& v5 = std::move(w2); //w1的类型为int,所以v5为int&&
//3. typedef时可能发生的引用折叠
Foo<int&> f1; //==>typedef int& && RvalueRefToT; 折叠后:typedef int& RvalueRefToT;
Foo<int&&> f2; //typedef int&& && RvalueRefToT; 折叠后:typedef int&& RvalueRefToT;
int i = 0;
int& r1 = i; //ok
//int& &r2 = r1; //error,不能直接定义引用的引用
typedef int& rint;
rint r2 = i; //ok,r1为int&类型
rint &r3 = i; //间接定义引用的引用时,会发生引用折叠。如int& &r3 ==>int& r3
//4. 函数模板参数中可能发生引用折叠
Widget w;
func(w); //用左值w初始化T&&,存在类型推导T为Widget&,传入func后为Widget& &&,折叠后为Widget&,所以param的类型为Widget&,是个左值引用
func(std::move(w)); //用右值初始化T&&,T被推导为Widget,传入
//func后为Widget&&,所以param为右值引用。
vector<int> v;
func(std::move(v)); //调用右值引用的版本:func(vector<T>&& param)。
return 0;
}
4. &&的总结
(1)左值和右值是表达式的属性,独立于它们的类型。比如,右值引用类型可能是左值也可能是右值。编译器将具名的右值引用视为左值,匿名的右值引用视为右值。
(2)auto&&或函数参数存在类型推导时,T&&是一个未定的引用类型。它可能是左值引用,也可能是右值引用,取决于初始化的值类型。
(3)所有的右值引用叠加到右值引用上仍然是一个右值引用,其它种叠加都是左值引用。
一、多线程调试
多线程调试重要就是下面几个命令:
info thread 查看当前进程的线程。 thread <ID> 切换调试的线程为指定ID的线程。 break file.c:100 thread all 在file.c文件第100行处为所有经过这里的线程设置断点。 set scheduler-locking off|on|step,这个是问得最多的。在使用step或者continue命令调试当前被调试线程的时候,其他线程也是同时执行的,怎么只让被调试程序执行呢?通过这个命令就可以实现这个需求。 off 不锁定任何线程,也就是所有线程都执行,这是默认值。 on 只有当前被调试程序会执行。 step 在单步的时候,除了next过一个函数的情况(熟悉情况的人可能知道,这其实是一个设置断点然后continue的行为)以外,只有当前线程会执行。
二、调试宏
这个问题超多。在GDB下,我们无法print宏定义,因为宏是预编译的。但是我们还是有办法来调试宏,这个需要GCC的配合。
在GCC编译程序的时候,加上-ggdb3参数,这样,你就可以调试宏了。
另外,你可以使用下述的GDB的宏调试命令 来查看相关的宏。
info macro – 你可以查看这个宏在哪些文件里被引用了,以及宏定义是什么样的。 macro – 你可以查看宏展开的样子。
三、源文件
这个问题问的也是很多的,太多的朋友都说找不到源文件。在这里我想提醒大家做下面的检查:
编译程序员是否加上了-g参数以包含debug信息。 路径是否设置正确了。使用GDB的directory命令来设置源文件的目录。
下面给一个调试/bin/ls的示例(ubuntu下)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ apt-get sourcecoreutils $ sudoapt-get installcoreutils-dbgsym $ gdb /bin/ls GNU gdb (GDB) 7.1-ubuntu (gdb) list main 1192 ls.c: No such fileor directory. inls.c (gdb) directory ~/src/coreutils-7.4/src/ Source directories searched: /home/hchen/src/coreutils-7.4:$cdir:$cwd (gdb) list main 1192 } 1193 } 1194 1195 int 1196 main (int argc, char **argv) 1197 { 1198 int i; 1199 struct pending *thispend; 1200 int n_files; 1201 |
四、条件断点
条件断点是语法是:break [where] if [condition],这种断点真是非常管用。尤其是在一个循环或递归中,或是要监视某个变量。注意,这个设置是在GDB中的,只不过每经过那个断点时GDB会帮你检查一下条件是否满足。
五、命令行参数
有时候,我们需要调试的程序需要有命令行参数,很多朋友都不知道怎么设置调试的程序的命令行参数。其实,有两种方法:
gdb命令行的 –args 参数 gdb环境中 set args命令。
六、gdb的变量
有时候,在调试程序时,我们不单单只是查看运行时的变量,我们还可以直接设置程序中的变量,以模拟一些很难在测试中出现的情况,比较一些出错,或是switch的分支语句。使用set命令可以修改程序中的变量。
另外,你知道gdb中也可以有变量吗?就像shell一样,gdb中的变量以$开头,比如你想打印一个数组中的个个元素,你可以这样:
|
1 2 3 4 5 |
(gdb) set$i = 0
(gdb) p a[$i++]
... #然后就一路回车下去了 |
当然,这里只是给一个示例,表示程序的变量和gdb的变量是可以交互的。
七、x命令
也许,你很喜欢用p命令。所以,当你不知道变量名的时候,你可能会手足无措,因为p命令总是需要一个变量名的。x命令是用来查看内存的,在gdb中 “help x” 你可以查看其帮助。
x/x 以十六进制输出 x/d 以十进制输出 x/c 以单字符输出 x/i 反汇编 – 通常,我们会使用 x/10i $ip-20 来查看当前的汇编($ip是指令寄存器)x/s 以字符串输出 八、command命令
有一些朋友问我如何自动化调试。这里向大家介绍command命令,简单的理解一下,其就是把一组gdb的命令打包,有点像字处理软件的“宏”。下面是一个示例:
|
1 2 3 4 5 6 7 8 9 10 |
(gdb) breakfunc Breakpoint 1 at 0x3475678: filetest.c, line 12. (gdb) command1 Type commands forwhen breakpoint 1 is hit, one per line. End with a line saying just "end". >print arg1 >print arg2 >print arg3 >end (gdb) |
当我们的断点到达时,自动执行command中的三个命令,把func的三个参数值打出来。
设置core环境
uname -a 查看机器参数
ulimit -a 查看默认参数
ulimit -c 1024 设置core文件大小为1024
ulimit -c unlimit 设置core文件大小为无限
多线程如果dump,多为段错误,一般都涉及内存非法读写。可以这样处理,使用下面的命令打开系统开关,让其可以在死掉的时候生成
core文件。
ulimit -c unlimited
线程调试命令
(gdb)info threads
显示当前可调试的所有线程,每个线程会有一个GDB为其分配的ID,后面操作线程的时候会用到这个ID。
前面有*的是当前调试的线程。
(gdb)thread ID
切换当前调试的线程为指定ID的线程。
(gdb)thread apply ID1 ID2 command
让一个或者多个线程执行GDB命令command。
(gdb)thread apply all command
让所有被调试线程执行GDB命令command。
(gdb)set scheduler-locking off|on|step
估计是实际使用过多线程调试的人都可以发现,在使用step或者continue命令调试当前被调试线程的时候,其他线程也是同时执行的,怎么只让被调试程序执行呢?通过这个命令就可以实现这个需求。
off 不锁定任何线程,也就是所有线程都执行,这是默认值。
on 只有当前被调试程序会执行。
step 在单步的时候,除了next过一个函数的情况(熟悉情况的人可能知道,这其实是一个设置断点然后continue的行为)以外,只有当前线程会执行。
//显示线程堆栈信息
(gdb) bt
察看所有的调用栈
(gdb) f 3
调用框层次
(gdb) i locals
显示所有当前调用栈的所有变量