1、概述
1.1、是什么
Spring Cloud Ribbon 是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说, Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load BalanCer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法。
1.2、能干什么
LB(负载均衡)
LB,即负载均衡( Load Balance ),在微服务或分布式集群中经常用的一种应用。
负载均衡简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA。
常见的负载均衡有软件nginx , LVS ,硬件 F5 等。
相应的在中间件,例如:dubbo。和 SpringCloud 中均给我们提供了负载均衡,SpringCloud的负载均衡算法可以自定义。
两种LB
1、集中式LB(偏硬件)
集中式 LB
即在服务的消费方和提供方之间使用独立的LB设施(可以是硬件,如F5,也可以是软件,如nginx ) ,由该设施负责把访问请求通过某种策略转发至服务的提供方;
2、进程内LB(偏软件)
进程内 LB
将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务器。
Ribbon就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服各提供方的地址。
1.3、官方资料
https://github.com/Netflix/ribbon/wiki
2、Ribbon配置初步
1、修改microservicecloud-consumer-dept-80工程POM,添加:
<!-- Ribbon相关 --> <!--Ribbon 需要 eureka --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-ribbon</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> </dependency>
2、修改YML,加入Ribbon配置
eureka: client: register-with-eureka: false #自己不能注册 service-url: defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
3、在cn.hfbin.springcloud.cfgbeans.ConfigBean.java中的getRestTemplate()方法上上加入注解@LoadBalanced
@Configuration public class ConfigBean { @Bean @LoadBalanced //Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端 负载均衡的工具。 public RestTemplate getRestTemplate() { return new RestTemplate(); } }
4、主启动类DeptConsumer80_App添加 @EnableEurekaClient
5、修改客户端的程序类DeptController_Consumer.java
//把下面这行 private static final String REST_URL_PREFIX = "http://localhost:8001"; //改成下面这行 private static final String REST_URL_PREFIX = "http://MICROSERVICECLOUD-DEPT";
6、测试
先启动单个eureka三个集群再启动8001,最后启动80

7、总结
Ribbon整合后80可以直接调用微服务而不再关心地址和端口
微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事,从技术角度看就是一种小而独立的处理过程,类似进程概念,能够自行单独启动或销毁,拥有自己独立的数据库。
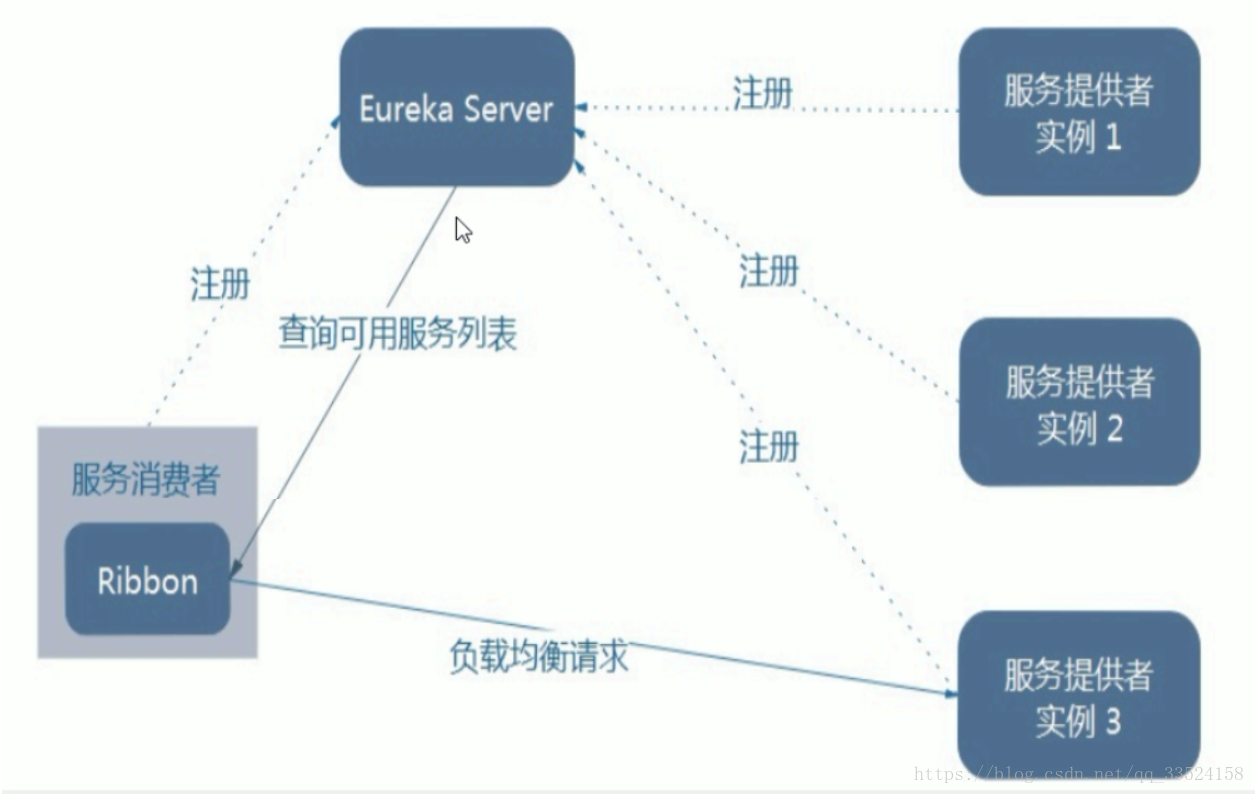
Ribbon 在工作时分成两步第一步先选择 EurekaServer,它优先选择在同一个区域内负载较少的 server。
第二步再根据用户指定的策略,在从server取到的服务注册列表中选择一个地址。
其中Ribbon 提供了多种策略:比如轮询、随机和根据响应时间加权。
2、新建两个工程microservicecloud-provider-dept-8002和microservicecloud-provider-dept-8003,参考8001
2.1、将8001 POM 内容拷贝到8002 、 8003
2.2、将8001下的java代码拷贝到8002 、 8003,并修改主启动类的名称
2.3、将8001 YML复制到8002 、 8003资源文件下、修改部分如图: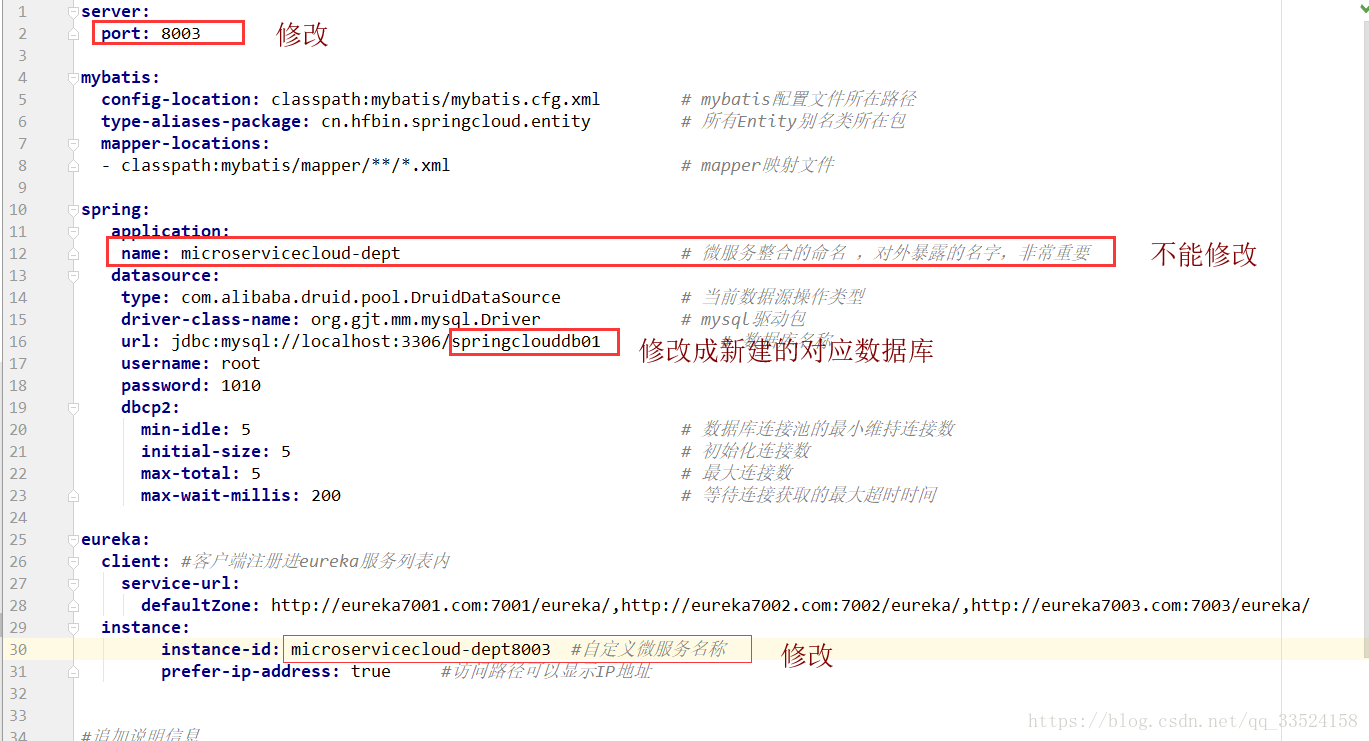
3.3、新建两个数据库springclouddb02 、 springclouddb03
#记得修改数据库名 CREATE SCHEMA `springclouddb01` DEFAULT CHARACTER SET utf8 ; create table springclouddb01.dept ( deptno bigint not null primary key auto_increment, dname varchar(60), db_source varchar(60) ); insert into dept(dname , db_source) values('开发部' , database()); insert into dept(dname , db_source) values('人事部' , database()); insert into dept(dname , db_source) values('财务部' , database()); insert into dept(dname , db_source) values('市场部' , database()); insert into dept(dname , db_source) values('运维部' , database()); select * from springclouddb01.dept;
3.4、测试:
启动7001—> 7002 —> 7003 —> 8001 —> 8002 ----> 8003 —> 80
访问连接:http://localhost/consumer/dept/list 注意看返回的json数据,发现每次刷新得到的数据是不一样的,轮询的返回数据,这时通过Ribbon完成了负载均衡。
3.5、总结:

Ribbon默认自带了七种算法,默认是轮询。
我们也可以自定义自己的算法。
4.1、修改访问服务的算法方式
* 切换 访问的算法 很简单只需要换成我们要返回算法的实例即可
* 默认有七个算法,可以也自定义自己的算法
package cn.hfbin.myrule; /** * 该配置类不可以放在与注解 @ComponentScan 的同包或者子包下,否则不起作用 (自定义算法也是一样) */ @Configuration public class MySelfRule { /* * 切换 访问的算法 很简单只需要换成我们要返回算法的实例即可 * 默认有七个算法,可以自定义自己的算法 * */ @Bean public IRule myRule() { //如果 突然间一个服务挂了 访问带挂的服务器会报错,出现错误页面 //return new RoundRobinRule(); //return new RandomRule(); //达到的目的,用我们重新选择的随机算法替代默认的轮询。 //如果 突然间一个服务挂了 访问带挂的服务器会报错,出现错误页面,但是过一下子他不会再访问挂的机器,不会显示出错误的页面。 return new RetryRule(); } }
4.2、自定义IRule算法
1、在主程序添加@RibbonClient(name=“MICROSERVICECLOUD-DEPT”,configuration=MySelfRule.class)
(注意:自定义算法不可以放在与注解 @ComponentScan 的同包或者子包下,否则不起作用 )
2、MySelfRule.java
@Configuration public class MySelfRule { @Bean public IRule myRule() { //return new RandomRule();// Ribbon默认是轮询,我自定义为随机 //return new RoundRobinRule();// Ribbon默认是轮询,我自定义为随机 //return new RetryRule(); return new RandomRule();// 我自定义为每台机器5次 } }
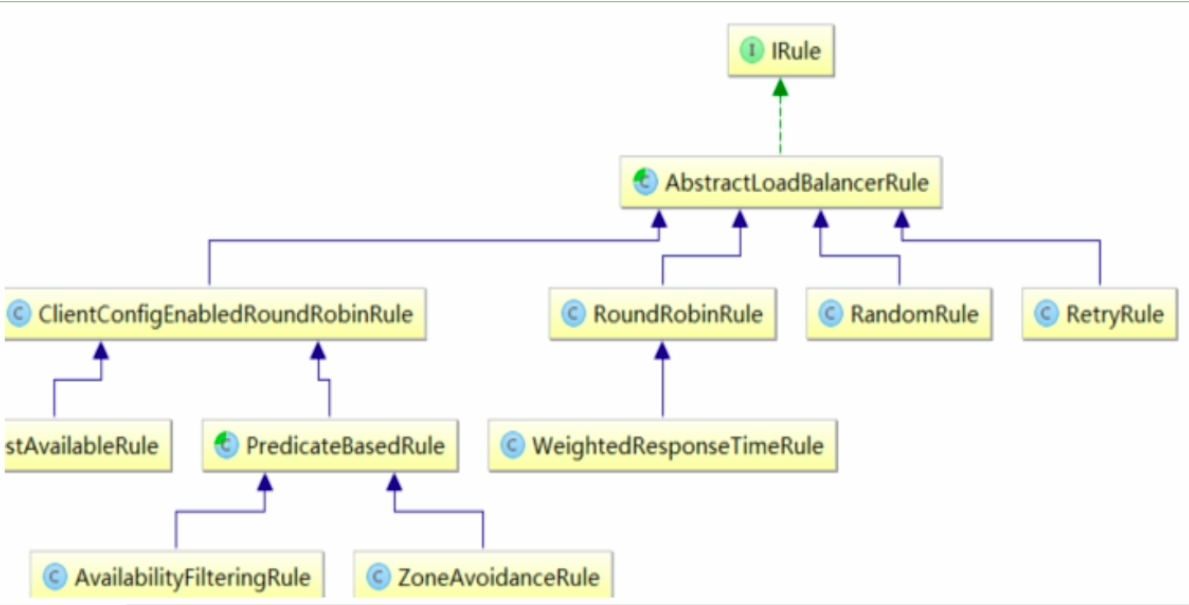
3、自定义算法必须继承抽象类 AbstractLoadBalancerRule
package cn.hfbin.myrule; /* * 参考随机数的源码来修改 * * https://github.com/Netflix/ribbon/blob/master/ribbon-loadbalancer/src/main/java/com/netflix/loadbalancer/RandomRule.java * */ public class RandomRule extends AbstractLoadBalancerRule { // total = 0 // 当total==5以后,我们指针才能往下走, // index = 0 // 当前对外提供服务的服务器地址, // total需要重新置为零,但是已经达到过一个5次,我们的index = 1 // 分析:我们5次,但是微服务只有8001 8002 8003 三台,OK? // private int total = 0; // 总共被调用的次数,目前要求每台被调用5次 private int currentIndex = 0; // 当前提供服务的机器号 public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { return null; } Server server = null; while (server == null) { if (Thread.interrupted()) { return null; } //活着的可以对外提供服务的机器 List<Server> upList = lb.getReachableServers(); //所有的服务 List<Server> allList = lb.getAllServers(); //服务的总数 int serverCount = allList.size(); if (serverCount == 0) { /* * No servers. End regardless of pass, because subsequent passes only get more * restrictive. */ return null; } // int index = rand.nextInt(serverCount);// java.util.Random().nextInt(3); // server = upList.get(index); if (total < 5) { //获取服务的第几个 server = upList.get(currentIndex); total++; } else { total = 0; currentIndex++; if (currentIndex >= upList.size()) { currentIndex = 0; } } if (server == null) { /* * The only time this should happen is if the server list were somehow trimmed. * This is a transient condition. Retry after yielding. */ Thread.yield(); continue; } if (server.isAlive()) { return (server); } // Shouldn't actually happen.. but must be transient or a bug. server = null; Thread.yield(); } return server; } @Override public Server choose(Object key) { return choose(getLoadBalancer(), key); } @Override public void initWithNiwsConfig(IClientConfig clientConfig) { // TODO Auto-generated method stub } }
4、测试
测试与上面启动顺序一样