一个机器学习主要要经过如下几步:
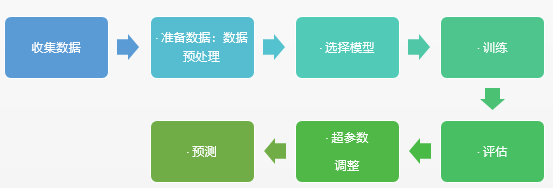
这么一讲比较抽象,我拿Kaggle比赛中的泰坦尼克生存率预测为例子:
收集数据:https://github.com/cystanford/Titanic_Data
该数据集一共有俩个文件: train.csv:训练集,包含特征信息,分类结果(存活与否) test.csv:测试集,只包含特征信息
数据集中的字段内容如下,这个时候就要对数据进行预处理。这一步也叫特征工程,将对预测结果不相关关的特征去除,比如乘客编号,对缺失值,错误值,重复值进行优化或者补全,或者用多个特征构造新的特征。总的来说,有三步:drop不相关或者质量太差的,补全缺失的,构造新特征

在这些字段,号码,编号,名字通常与结果无关,可以drop掉,船舱缺失的值太多,也drop掉。
通过均值补全票价,年纪,把登录最多的港口补全缺失值。
在这里点击查看数据清洗:【ML】数据清洗
由于该样本较为简单,不构造新特征。
#clean_feature.py
import numpy as np import pandas as pd train_data = pd.read_csv('./train.csv') test_data = pd.read_csv('./test.csv') # 使用年龄的均值填充年龄的nan值 train_data['Age'].fillna(train_data['Age'].mean(), inplace=True) test_data['Age'].fillna(test_data['Age'].mean(),inplace=True) # 使用票价的均值填充票价中的nan值 train_data['Fare'].fillna(train_data['Fare'].mean(), inplace=True) test_data['Fare'].fillna(test_data['Fare'].mean(),inplace=True) print(train_data['Embarked'].value_counts()) # 使用登录最多的港口来填充登录港口的nan值 train_data['Embarked'].fillna('S', inplace=True) test_data['Embarked'].fillna('S',inplace=True) train_data.to_csv('./train_sample.csv') test_data.to_csv('./test_sample.csv')
接下来选择模型,我们这个问题是一个二分类问题,而且特征之间没有明显关系,我又想快速得到结果,所以在这里使用LR进行分类。
在这里我将特征值做了特征向量话,因为这里面的连续值比较多,如果用labelencoder则要分桶,如果用onehotencoder那矩阵只会更稀疏。
在这里面,将训练集进行了split,分别进行训练和验证。通过验证集,我的模型评估到该模型的准确率在0.78-0.81之间,还不错。
import pandas as pd from sklearn.feature_extraction import DictVectorizer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #读取文件 train_data = pd.read_csv('./train_sample.csv') test_data = pd.read_csv('./test_sample.csv') #在这里我只保留了以下几个特征,然后将Survived特征作为结果label features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'] train_features = train_data[features] train_labels = train_data['Survived'] test_features = test_data[features] #特征值是不能直接用的,所以要进行编码,在这里我使用特征向量化 #对训练集fit_transform,对测试集因为之前fit过了,所以这一次我只要transform dvec=DictVectorizer(sparse=False) train_features=dvec.fit_transform(train_features.to_dict(orient='record')) test_features=dvec.transform(test_features.to_dict(orient='record')) #这一步就是把训练集划分成训练集和验证集,注意后者y是结果label X_train, X_test, y_train, y_test = train_test_split(train_features, train_labels, train_size=0.75, test_size=0.25) #选用模型 from sklearn.linear_model.logistic import LogisticRegression model = LogisticRegression(max_iter=100, verbose=True, random_state=33, solver='liblinear' ) model.fit(X_train,y_train) predict_y = model.predict(X_test) print('LR准确率: %0.4lf' % accuracy_score(predict_y, y_test)) #[LibLinear]LR准确率: 0.8117
接下来就是超参数调整了,LogisticRegression的参数我会在以后单独开一篇进行讲解,同时也会讲一下原理。
这一步通常是根据自己对模型和业务的经验进行调优,然后把结果最好的模型保存起来(我这里没有保存)。
调整完以后,就可以对测试集进行预测了,如果是kaggle比赛的话,还要保存为一个文件用于提交。至此,一个简单的机器学习就做完了。
predict_test = model.predict(test_features) pd.DataFrame(predict_test).to_csv("submit.csv",index=False,header=False)