2020/5/26
最近开始学习推荐系统开发实战这本书,这是学习的第一个python程序,里面有很多地方需要做笔记。
1、python 中os模块 os.path.exists() 含义
os.path模块主要用于文件的属性获取,exists是“存在”的意思,所以顾名思义,os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径。如果不存在,返回的则是FALSE。
![]()
2、Python os.listdir() 方法
os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
![]()

3、Python format 格式化函数

4、Python中 with open ( file_abs, 'r' ) as f : 的用法以及意义
要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标示符:
![]()
标示符 'r' 表示读,这样我们就成功地打开了一个文件。
如果文件不存在,open() 函数就会抛出一个 IOError 的错误,并且给出错误码和详细的信息告诉你文件不存在:

如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示:
![]()
最后一步是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
![]()
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
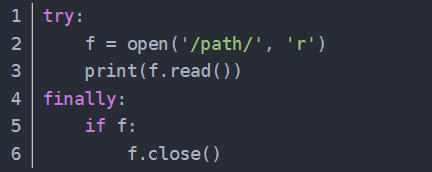
每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:

这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
调用read()会一次性读取文件的全部内容,如果文件有20G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。
另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便:
![]()
写文件:
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:

可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:

要写入特定编码的文本文件,请给open()函数传入encoding参数,将字符串自动转换成指定编码。要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:

遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
![]()
5、Python strip()方法
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。

6、Python3 endswith()方法
endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。
Python startswith()方法
Python startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。
7、Python split()方法
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串

8、Python的random.sample
![]()
用于从 list(users)中随机抽取1000个数据,生成新的列表 users_1000
9、python中的随机数种子seed()
- 给随机数对象一个种子值,用于产生随机序列。
- 对于同一个种子值的输入,之后产生的随机数序列也一样。
- 通常是把时间秒数等变化值作为种子值,达到每次运行产生的随机系列都不一样
- seed() 省略参数,意味着使用当前系统时间生成随机数。
10、json 中的 load、loads、dump、dumps分别是什么?
dump 和 dumps 都实现了序列化
load 和 loads 都实现反序列化
变量从内存中变成可存储或传输的过程称之为序列化 ,序列化是将对象状态转化为可保存或可传输格式的过程。
变量内容从序列化的对象重新读到内存里称之为反序列化 ,反序列化是流转换为对象。
load 和 loads (反序列化)
load:针对文件句柄,将json格式的字符转换为dict,从文件中读取 (将string转换为dict)
loads:针对内存对象,将string转换为dict (将string转换为dict)

dump 和 dumps(序列化)
dump:将dict类型转换为json字符串格式,写入到文件 (易存储)
dumps:将dict转换为string (易传输)

11、Python 字典(Dictionary)
(1)setdefault() 方法
如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。

(2)dict.keys() 方法:获取所有的 key 值
(3)dict.items() 方法:以列表返回可遍历的(键, 值) 元组数组。
