Linq中Union与Contact方法用法对比
文章一开始,我们来看看下面这个简单的实例。
代码片段1:
int[] ints1 = { 2, 4, 9, 3, 0, 5, 1, 7 };
int[] ints2 = { 1, 3, 6, 4, 4, 9, 5, 0 };
IEnumerable<int> intsUnion = ints1.Union(ints2);
IEnumerable<int> intsContact = ints1.Concat(ints2);
Console.WriteLine("数组ints1:");
foreach (int num in ints1){
Console.Write("{0} ", num);
}
Console.WriteLine();
Console.WriteLine("数组ints2:");
foreach (int num in ints2){
Console.Write("{0} ", num);
}
Console.WriteLine();
Console.WriteLine("Union后的结果:");
foreach (int num in intsUnion){
Console.Write("{0} ", num);
}
Console.WriteLine();
Console.WriteLine("Concat后的结果:");
foreach (int num in intsContact){
Console.Write("{0} ", num);
}运行结果:
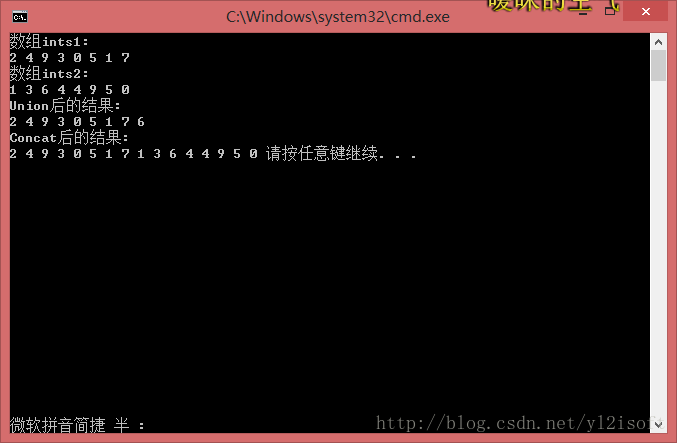
从结果可以看出,Union与Contact方法都是计算两个集合的并集,只是,Union方法的返回结果中,重复元素仅保留一个(与数学中的集合并集操作一致)。
接着看下面这个例子。
代码片段2:
class Student{
public int Id { get; set; }
public string Name { get; set; }
public string Class { get; set; }
public int Score { get; set; }
}
List<Student> stuList1 = new List<Student>(){
new Student(){Id=1,Name="tiana0",Class="04机制春",Score=100},
new Student(){Id=2,Name="xiaobo",Class="09计研",Score=80},
new Student(){Id=3,Name="八戒",Class="09计研",Score=30}
};
List<Student> stuList2 = new List<Student>(){
new Student(){Id=1,Name="tiana0",Class="04机制春",Score=100},
new Student(){Id=2,Name="张三",Class="09计研",Score=100},
new Student(){Id=1,Name="八戒",Class="09计研",Score=30}
};
IEnumerable<Student> unionList = stuList1.Union(stuList2);
IEnumerable<Student> concatList = stuList1.Concat(stuList2);
Console.WriteLine("stuList1:Id,Name,Class,Score");
foreach (var s1 in stuList1){
Console.WriteLine("{0},{1},{2},{3}", s1.Id, s1.Name, s1.Class, s1.Score);
}
Console.WriteLine("stuList2:Id,Name,Class,Score");
foreach (var s2 in stuList2){
Console.WriteLine("{0},{1},{2},{3}", s2.Id, s2.Name, s2.Class, s2.Score);
}
Console.WriteLine("unionList:Id,Name,Class,Score");
foreach (var s3 in unionList){
Console.WriteLine("{0},{1},{2},{3}", s3.Id, s3.Name, s3.Class, s3.Score);
}
Console.WriteLine("concatList:Id,Name,Class,Score");
foreach (var s4 in concatList){
Console.WriteLine("{0},{1},{2},{3}", s4.Id, s4.Name, s4.Class, s4.Score);
}运行结果:
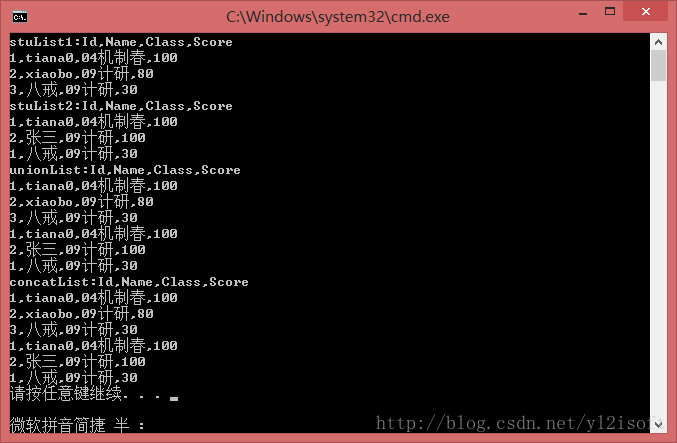
查看结果,发现,Union与Contact方法返回结果完全相同,也就是说,Union方法并没有对重复元素进行“去重”(去掉多余的,保留一个)处理。
那到底是哪里出了问题呢?
翻阅msdn了解到,Union方法之所以能进行“去重”操作,是因为Union方法通过使用默认的相等比较器生成两个序列的并集。 也就是说Union方法中会使用默认的相等比较器对元素进行判断,若相等,则进行“去重”操作。
另外,还了解到,如果希望比较自定义数据类型的对象的序列,则必须在类中实现 IEqualityComparer<T>泛型接口。
到这里,再次改造自己的代码。
代码片段3:
class Student : IEquatable<Student>{
public int Id { get; set; }
public string Name { get; set; }
public string Class { get; set; }
public int Score { get; set; }
public bool Equals(Student other) {
//Check whether the compared object is null.
if (Object.ReferenceEquals(other, null)) return false;
//Check whether the compared object references the same data.
if (Object.ReferenceEquals(this, other)) return true;
//Check whether the Students' properties are equal.
return Id.Equals(other.Id) && Name.Equals(other.Name) && Class.Equals(other.Class) && Score.Equals(other.Score);
}
// If Equals() returns true for a pair of objects
// then GetHashCode() must return the same value for these objects.
public override int GetHashCode(){
//Get hash code for the Id field.
int hashStudentId = Id.GetHashCode();
//Get hash code for the Name field if it is not null.
int hashStudentName = Name == null ? 0 : Name.GetHashCode();
//Get hash code for the Class field if it is not null.
int hashStudentClass = Class == null ? 0 : Class.GetHashCode();
//Get hash code for the Score field.
int hashStudentScore = Score.GetHashCode();
//Calculate the hash code for the Student.
return hashStudentId ^ hashStudentName ^ hashStudentClass ^ hashStudentScore;
}
}代码片段3仅修改了Student代码,使其 实现 IEqualityComparer<T>泛型接口。
这里有个小疑问,明明说的是实现IEqualityComparer<T>泛型接口,为什么Student必须实现IEquatable<Student>接口,大家知道吗?望指教。由于时间关系,这里就不再研究了,下次等我研究清楚后再专门叙述。
再次运行程序,得到以下结果:
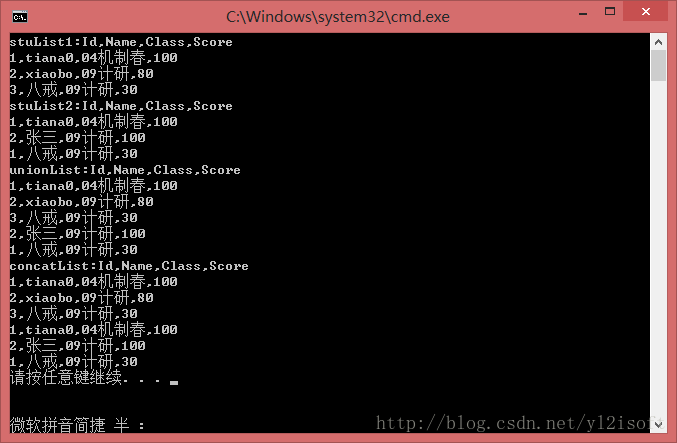
Union方法又能正常“去重”了。