Convert a BST to a sorted circular doubly-linked list in-place. Think of the left and right pointers as synonymous to the previous and next pointers in a doubly-linked list.
Let's take the following BST as an example, it may help you understand the problem better:
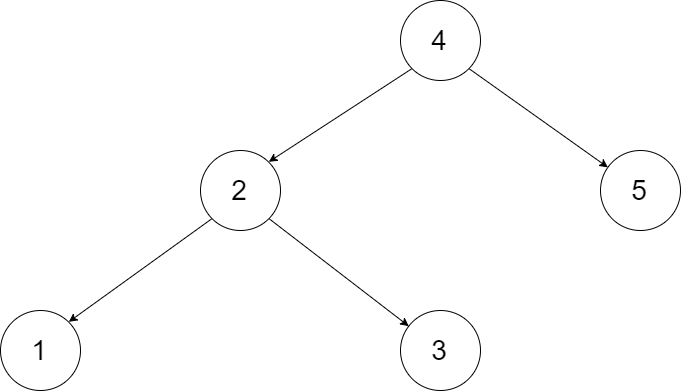
We want to transform this BST into a circular doubly linked list. Each node in a doubly linked list has a predecessor and successor. For a circular doubly linked list, the predecessor of the first element is the last element, and the successor of the last element is the first element.
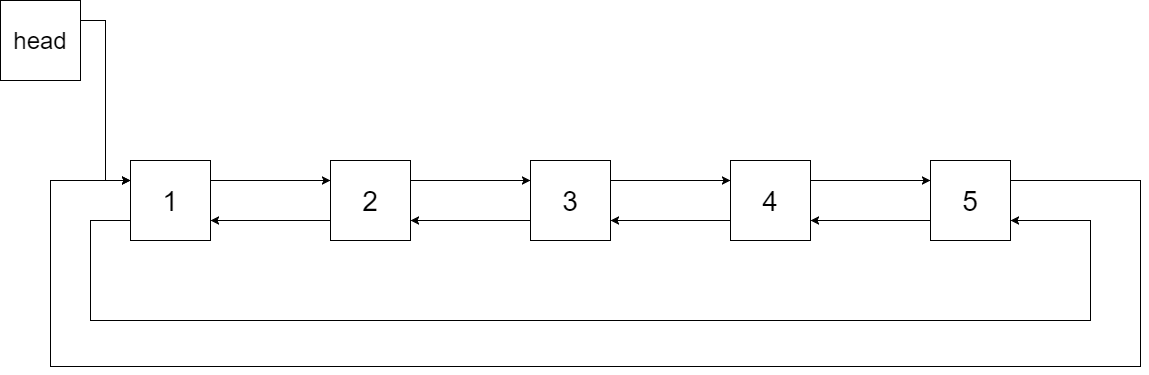
The figure below shows the circular doubly linked list for the BST above. The "head" symbol means the node it points to is the smallest element of the linked list.
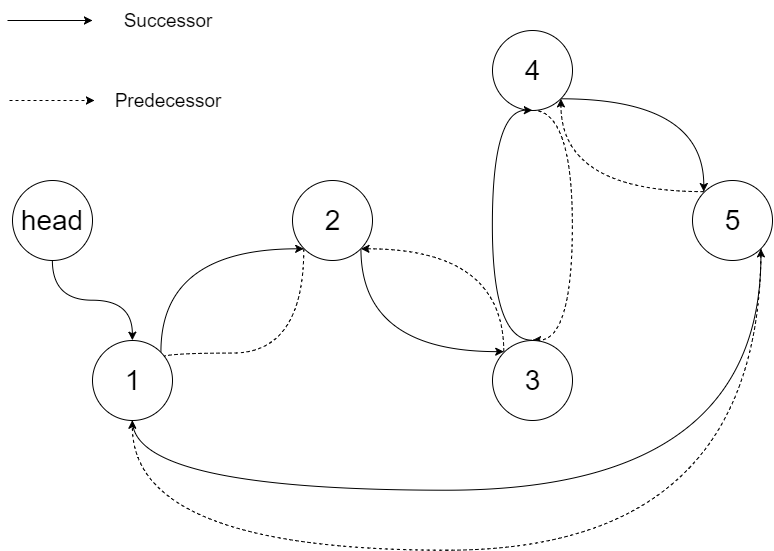
Specifically, we want to do the transformation in place. After the transformation, the left pointer of the tree node should point to its predecessor, and the right pointer should point to its successor. We should return the pointer to the first element of the linked list.
The figure below shows the transformed BST. The solid line indicates the successor relationship, while the dashed line means the predecessor relationship.
这道题给了一个二叉搜索树,让我们将其转化为双向链表。并且题目中给了一个带图的例子,帮助理解。题目本身并不难理解,仔细观察下给的示例图。首先,转化成双向链表的每个结点都有 left 和 right 指针指向左右两个结点,不管其原来是否是叶结点还是根结点,转换后统统没有区别。其次,这是个循环双向链表,即首尾结点是相连的,原先的二叉搜索树中的最左结点和最右结点,现在也互相连接起来了。最后,返回的结点不再是原二叉搜索树的根结点 root 了,而是最左结点,即最小值结点。
好,发现了上述规律后,来考虑如何破题。根据博主多年经验,跟二叉搜索树有关的题,肯定要利用其性质,即左<根<右,即左子结点值小于根结点值小于右子结点值。而且十有八九都得用中序遍历来解,因为中序遍历的顺序就是左根右啊,跟性质吻合。观察到原二叉搜索树中结点4连接着结点2和结点5,而在双向链表中,连接的是结点3和结点5,这就是为啥要用中序遍历了,因为只有中序遍历,结点3之后才会遍历到结点4,这时候可以将结点3和结点4串起来。决定了用中序遍历之后,就要考虑是迭代还是递归的写法,博主建议写递归的,一般写起来都比较简洁,而且递归是解树类问题的神器啊,十有八九都是用递归,一定要熟练掌握。再写中序遍历之前,其实还有难点,因为需要把相邻的结点连接起来,所以需要知道上一个遍历到的结点是什么,所以用一个变量 pre,来记录上一个遍历到的结点。还需要一个变量 head,来记录最左结点,这样的话,在递归函数中,先判空,之后对左子结点调用递归,这样会先一直递归到最左结点,此时如果 head 为空的话,说明当前就是最左结点,赋值给 head 和 pre,对于之后的遍历到的结点,那么可以和 pre 相互连接上,然后 pre 赋值为当前结点 node,再对右子结点调用递归即可,参见代码如下:
解法一:
class Solution { public: Node* treeToDoublyList(Node* root) { if (!root) return NULL; Node *head = NULL, *pre = NULL; inorder(root, pre, head); pre->right = head; head->left = pre; return head; } void inorder(Node* node, Node*& pre, Node*& head) { if (!node) return; inorder(node->left, pre, head); if (!head) { head = node; pre = node; } else { pre->right = node; node->left = pre; pre = node; } inorder(node->right, pre, head); } };
虽然说树类问题首推递归解法,但是中序遍历是可以用迭代来写的,可以参见博主之前的博客 Binary Tree Inorder Traversal。迭代写法借用了栈,其实整体思路和递归解法没有太大的区别,递归的本质也是将断点存入栈中,以便之后可以返回,这里就不多讲解了,可以参见上面的讲解,参见代码如下:
解法二:
class Solution { public: Node* treeToDoublyList(Node* root) { if (!root) return NULL; Node *head = NULL, *pre = NULL; stack<Node*> st; while (root || !st.empty()) { while (root) { st.push(root); root = root->left; } root = st.top(); st.pop(); if (!head) head = root; if (pre) { pre->right = root; root->left = pre; } pre = root; root = root->right; } head->left = pre; pre->right = head; return head; } };
这道题还有一种使用分治法 Divide and Conquer 来做的方法。分治法,顾名思义,就是把一项任务分成两半,用相同的逻辑去分别处理,之后再粘合起来。混合排序 Merge Sort 用的也是这种思路。这里可以对左右子结点调用递归函数,suppose 我们得到了两个各自循环的有序双向链表,然后把根结点跟左右子结点断开,将其左右指针均指向自己,这样就形成了一个单个结点的有序双向链表,虽然只是个光杆司令,但人家仍然是有序双向链表,不是沙雕,就问你叼不叼。那么此时只要再写一个连接两个有序双向链表的子函数,就可以将这三个有序双向链表按顺序链接起来了。
而链接两个有序双向链表的子函数也简单,首先判空,若一个为空,则返回另一个。如果两个都不为空,则把第一个链表的尾结点的右指针链上第二个链表的首结点,同时第二个链表的首结点的左指针链上第一个链表的尾结点。同理,把第二个链表的尾结点的右指针链上第一个链表的首结点,同时第一个链表的首结点的左指针链上第二个链表的尾结点。有木有读晕,可以自己画图,其实很好理解的诶,参见代码如下:
解法三:
class Solution { public: Node* treeToDoublyList(Node* root) { if (!root) return NULL; Node *leftHead = treeToDoublyList(root->left); Node *rightHead = treeToDoublyList(root->right); root->left = root; root->right = root; return connect(connect(leftHead, root), rightHead); } Node* connect(Node* node1, Node* node2) { if (!node1) return node2; if (!node2) return node1; Node *tail1 = node1->left, *tail2 = node2->left; tail1->right = node2; node2->left = tail1; tail2->right = node1; node1->left = tail2; return node1; } };
Github 同步地址:
https://github.com/grandyang/leetcode/issues/426
类似题目:
参考资料:
https://leetcode.com/problems/convert-binary-search-tree-to-sorted-doubly-linked-list/