selenium 提供的xpath定位方法名为:find_element_by_xpath(xpath表达式)
Xpath基本定位语法:
/ 绝对定位,从根节点选取
// 相对定位,从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性,@class = "XXX" @id = "XXX" ; 属性放在中括号[]中
* 通配符 匹配所有. //*
@* 通配符 匹配所有属性.//*[@*="hello"]
1. 绝对定位
1)以 / 开头
2)从页面根元素(<html>)开始,严格按照元素在html页面中的位置和顺序向下寻找
3) / 左边的元素为父元素,右边的元素为直系子元素
2. 相对路径
1)以 // 开头
2)不考虑元素在页面中的绝对路径和位置
3)考虑页面是否存在复合表达式的元素即可
3. 使用标签名+节点属性定位
//标签名[@属性名=值]
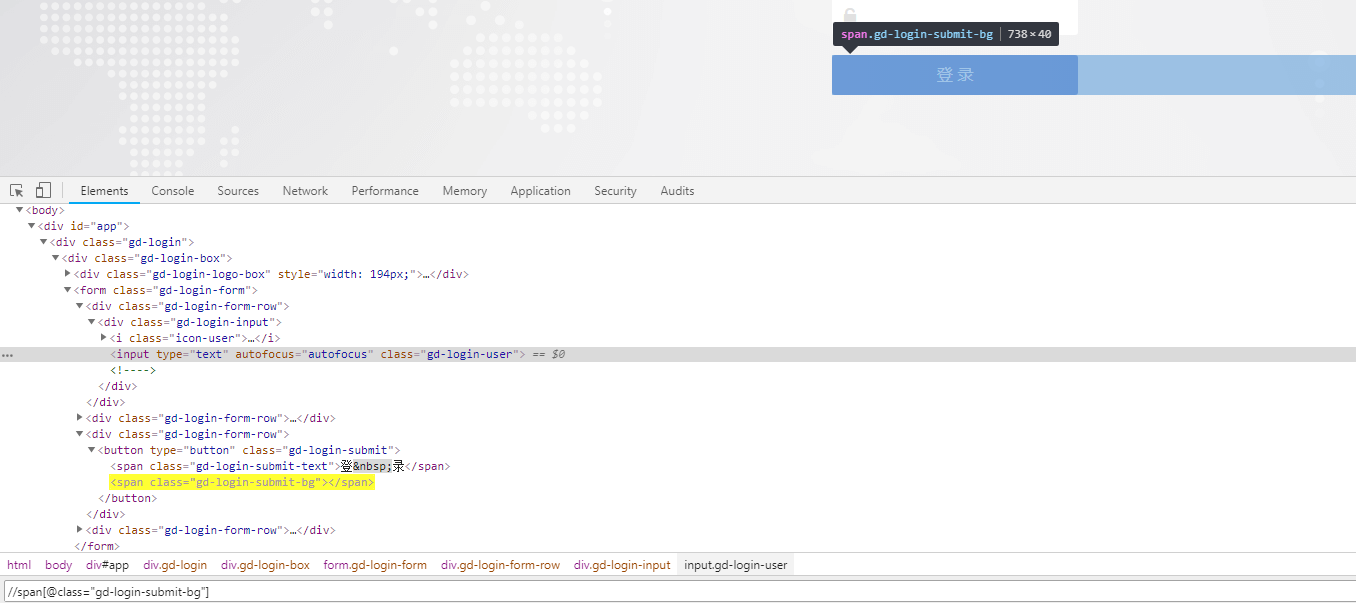
4. 组合元素索引(下标)定位

5. 通过部分属性值匹配
//标签名[contains(@属性名,部分属性值)]

6. 使用文本内容匹配
函数:text()
文本全部匹配:text()=文本内容
文本部分匹配:contains(text(),部分文本内容)

# -*- coding:utf-8 -*- ''' @project: web学习 @author: Jimmy @file: find_ele.py @ide: PyCharm Community Edition @time: 2019-01-18 10:56 @blog: https://www.cnblogs.com/gotesting/ ''' from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('http://www.baidu.com') ''' id 绝对唯一,其次name ''' # id driver.find_element_by_id('kw').send_keys('德玛西亚') driver.find_element(By.ID,'kw').send_keys('诺克萨斯') # classname # 返回符合条件的第一个元素 driver.find_element_by_class_name('s_ipt') # 返回符合条件的所有元素,返回值是list,每一个值都是一个Webelement对象 driver.find_elements_by_class_name('s_ipt') # tag_name driver.find_element_by_tag_name('span') driver.find_elements_by_tag_name('span') # name driver.find_element_by_name('wd') driver.find_elements_by_name('wd') # 链接的文本内容 driver.find_element_by_link_text('贴吧') # 完全匹配文本,要一模一样 driver.find_element_by_partial_link_text('贴吧') # 模糊匹配,包含即可 driver.find_elements_by_link_text('贴吧') driver.find_elements_by_partial_link_text('贴吧') # css driver.find_element_by_css_selector('') # xpath driver.find_element_by_xpath('') # 1. 绝对定位 : 以/开头,父/子关系 # 2. 相对定位 : 以//开头,在这个html页面中,有木有符合表达式的元素 # //标签名[@属性名称=属性值] # //标签名[@属性名称=属性值 and @属性名称=属性值] # 3. 层级定位 # 4. 文本内容定位: //标签名[text()='文本值'] # 5. 包含定位 : contains # contains(@属性名,属性值) # contains(text(),属性值) # 6. 轴定位 # ancestor : 祖先节点,包括父 # parent : 父节点 # preceding: 当前元素节点标签之前的所有节点(html页面先后顺序) # preceding-slibling:当前元素节点标签之前的所有兄弟结点 # following: 当前元素节点标签之后的所有节点(html页面先后顺序) # following-slibling:当前元素节点标签之后的所有兄弟结点 # /轴名称::节点名称[@属性名=属性值] #