除了懒加载,还有什么方法能提高查询效率呢?那就是缓存。
mybatis 为我们提供了一级缓存和二级缓存,可以通过下图来理解
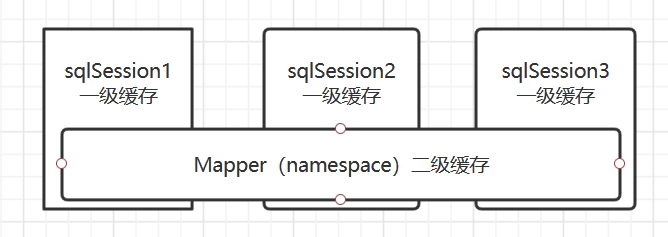
1、一级缓存是SqlSession级别的缓存 —— 它是各自独立的
在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。
不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
2、二级缓存是mapper级别的缓存 —— 它是多个 SqlSession 共享的
多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
一、一级缓存业务流程
1、一级缓存介绍
在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。具体执行过程如下图所示。
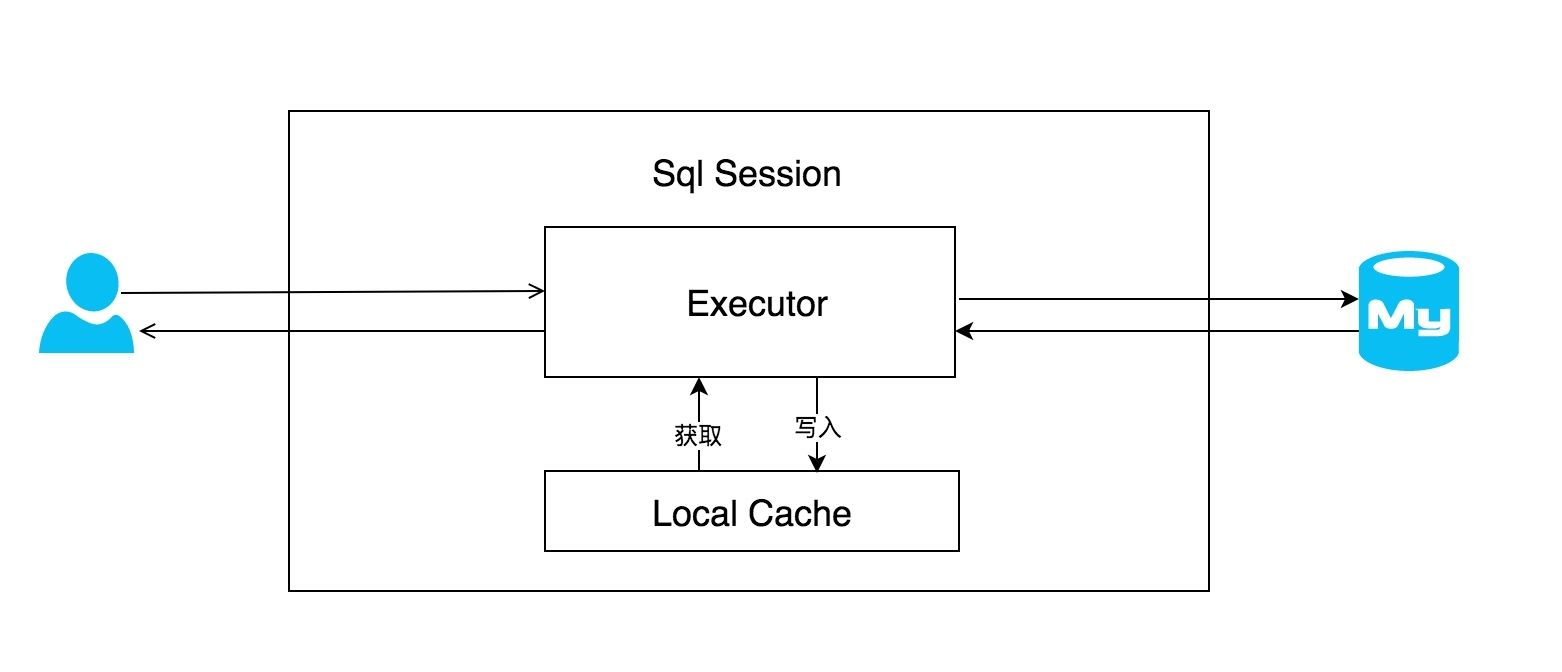
每个SqlSession中持有了Executor,每个Executor中有一个LocalCache。当用户发起查询时,MyBatis根据当前执行的语句生成MappedStatement,在Local Cache进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入Local Cache,最后返回结果给用户。
2、一级缓存配置
我们来看看如何使用MyBatis一级缓存。开发者只需在MyBatis的配置文件中,添加如下语句,就可以使用一级缓存。共有两个选项,SESSION或者STATEMENT,默认是SESSION级别,即在一个MyBatis会话中执行的所有语句,都会共享这一个缓存。一种是STATEMENT级别,可以理解为缓存只对当前执行的这一个Statement有效。
<setting name="localCacheScope" value="SESSION"/>
3、一级缓存实验流程
(1)我们在一个 sqlSession 中,对 User 表根据id进行两次查询,查看他们发出sql语句的情况。
执行结果:第一次查询时,会打印执行 sql 语句;第二次查询时,没有执行 sql 语句,直接打印出结果。
(2)同样是对user表进行两次查询,只不过两次查询之间进行了一次update操作。
执行结果:第一次查询,执行 sql 语句;更新之后,再次查询,也会执行 sql 语句。因为进行了更新操作,所以缓存清除了,第二次查询就还是会执行 sql 语句。
(3)开启两个SqlSession,在sqlSession1中查询数据,使一级缓存生效,在sqlSession2中更新数据库,验证一级缓存只在数据库会话内部共享。
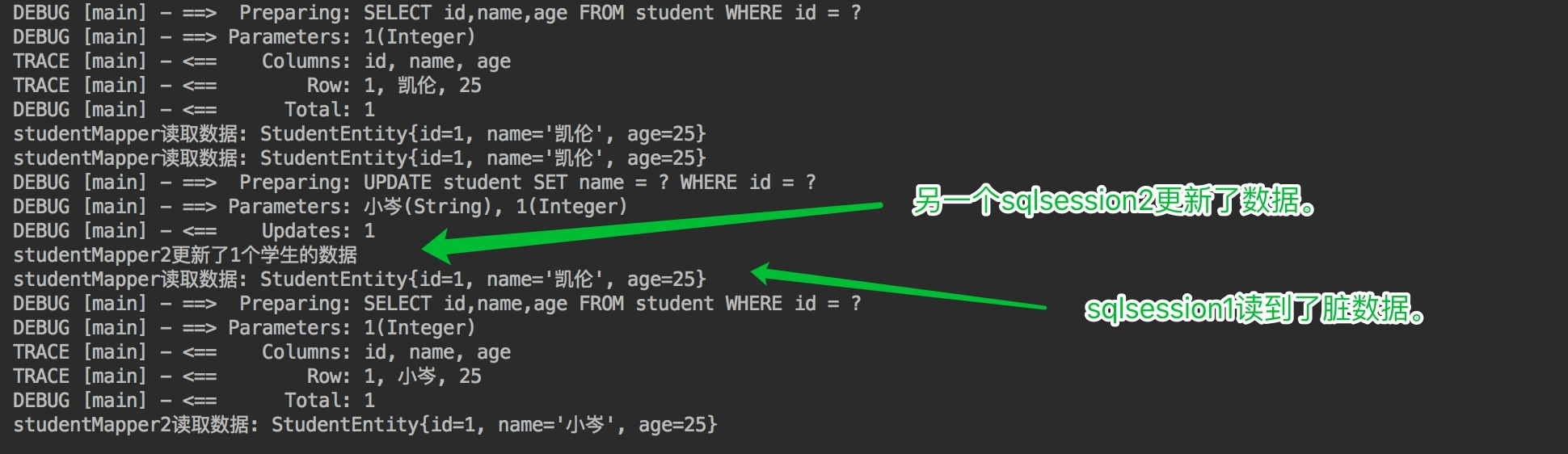
sqlSession2更新了id为1的学生的姓名,从凯伦改为了小岑,但session1之后的查询中,id为1的学生的名字还是凯伦,出现了脏数据,也证明了之前的设想,一级缓存只在数据库会话内部共享。
(3)流程总结:
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
如此往复。
二、一级缓存工作流程&源码分析
那么,一级缓存的工作流程是怎样的呢?我们从源码层面来学习一下。
1、工作流程
一级缓存执行的时序图,如下图所示。
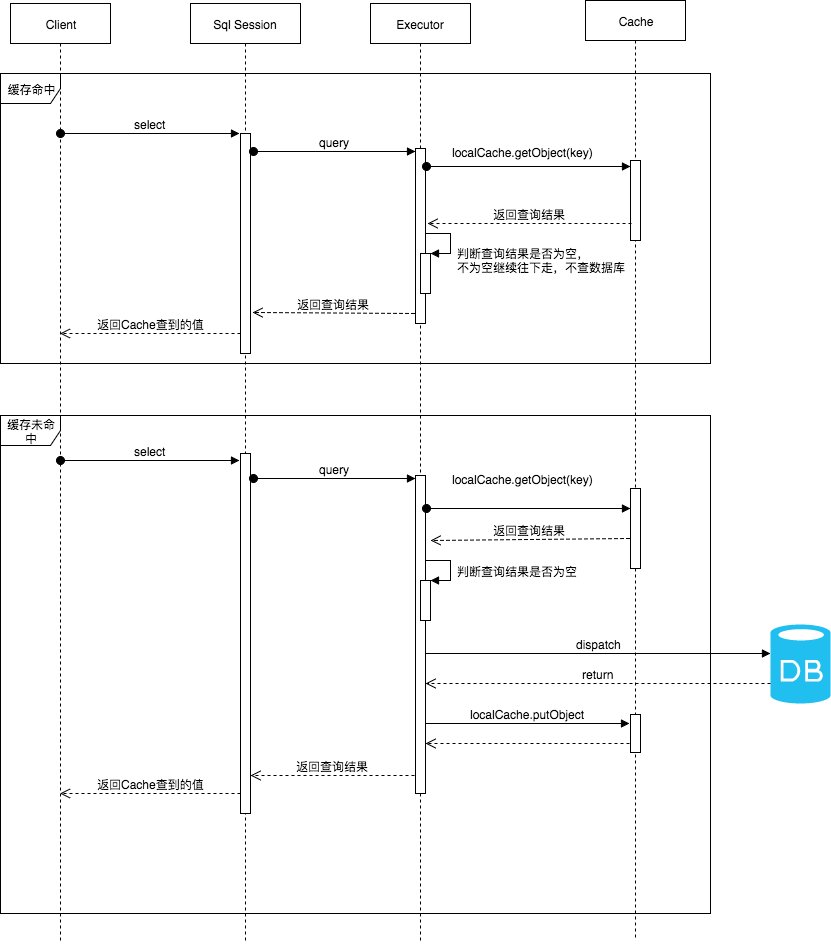
2、源码分析
源码分析看这篇文章:聊聊MyBatis缓存机制
3、总结
MyBatis一级缓存的生命周期和SqlSession一致。
MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
三、二级缓存业务流程
1、二级缓存介绍
在上文中提到的一级缓存中,其最大的共享范围就是一个SqlSession内部,如果多个SqlSession之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询,具体的工作流程如下所示。
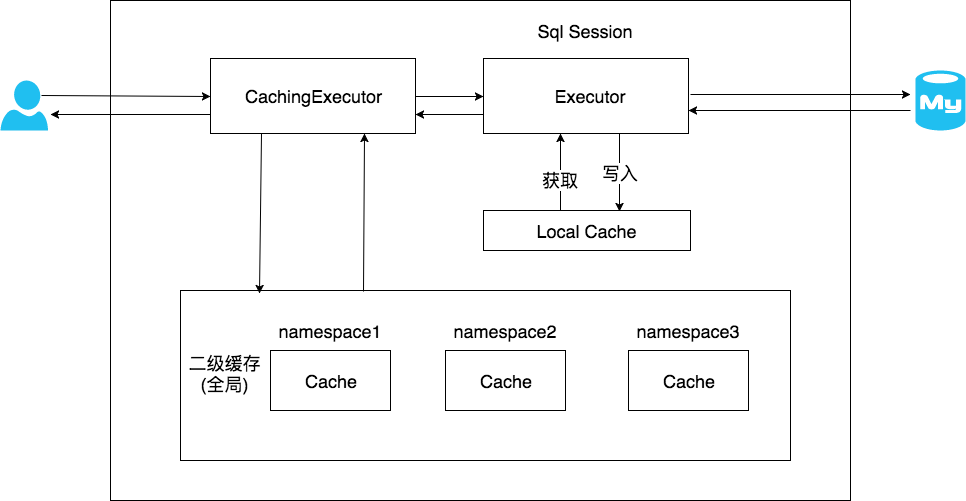
二级缓存开启后,同一个namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。
当开启二级缓存后,数据的查询执行的流程就是:二级缓存 -> 一级缓存 -> 数据库。
二级缓存的原理和一级缓存原理一样。
第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。
但是一级缓存是基于 sqlSession 的,而 二级缓存是基于 mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中
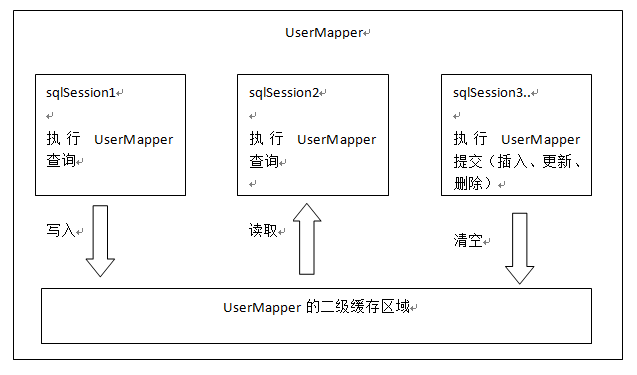
2、二级缓存是如何使用。
(1)开启二级缓存配置
和一级缓存默认开启不一样,二级缓存需要我们手动开启
首先,在全局配置文件 mybatis-configuration.xml 文件中加入如下代码:
<!--开启二级缓存 -->
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
其次,在MyBatis的映射XML中配置cache或者 cache-ref 。
cache标签用于声明这个namespace使用二级缓存,并且可以自定义配置。
<!-- 开启二级缓存 -->
<cache></cache>
type:cache使用的类型,默认是PerpetualCache,这在一级缓存中提到过。eviction: 定义回收的策略,常见的有FIFO,LRU。flushInterval: 配置一定时间自动刷新缓存,单位是毫秒。size: 最多缓存对象的个数。readOnly: 是否只读,若配置可读写,则需要对应的实体类能够序列化。blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
cache-ref代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache。
<cache-ref namespace="mapper.StudentMapper"/>
我们可以看到 mapper.xml 文件中就这么一个空标签<cache/>,其实这里可以配置<cache type="org.apache.ibatis.cache.impl.PerpetualCache"/>,PerpetualCache这个类是mybatis默认实现缓存功能的类。我们不写type就使用mybatis默认的缓存,也可以去实现 Cache 接口来自定义缓存。
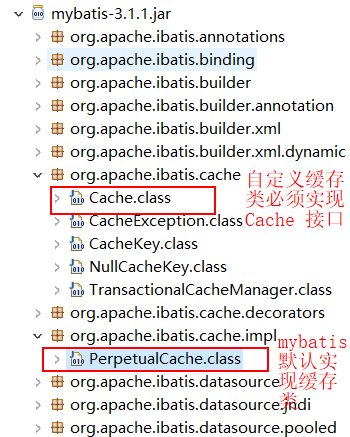
二级缓存底层还是 HashMap 架构。
(2)po 类实现 Serializable 序列化接口

开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以mybatis中的pojo都去实现Serializable接口。
(3)useCache和flushCache
mybatis中还可以配置userCache和flushCache等配置项,userCache是用来设置是否禁用二级缓存的,在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<select id="selectUserByUserId" useCache="false" resultType="com.ys.twocache.User" parameterType="int">
select * from user where id=#{id}
</select>
这种情况是针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存,直接从数据库中获取。
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache=”true” 属性,默认情况下为true,即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
<select id="selectUserByUserId" flushCache="true" useCache="false" resultType="com.ys.twocache.User" parameterType="int">
select * from user where id=#{id}
</select>
一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以我们不用设置,默认即可。
3、二级缓存实验
(1)实验1:测试二级缓存效果,不提交事务,sqlSession1查询完数据后,sqlSession2相同的查询是否会从缓存中获取数据。
执行结果:我们可以看到,当sqlsession没有调用commit()方法时,二级缓存并没有起到作用。
(2)实验2:测试二级缓存效果,当提交事务时,sqlSession1查询完数据后,sqlSession2相同的查询是否会从缓存中获取数据。
执行结果:sqlsession2的查询,使用了缓存,缓存的命中率是0.5。
(3)实验3:测试update操作是否会刷新该namespace下的二级缓存。
执行结果:我们可以看到,在sqlSession3更新数据库,并提交事务后,sqlsession2的StudentMapper namespace下的查询走了数据库,没有走Cache。
(4)实验4:验证MyBatis的二级缓存不适应用于映射文件中存在多表查询的情况。
通常我们会为每个单表创建单独的映射文件,由于MyBatis的二级缓存是基于namespace的,多表查询语句所在的namspace无法感应到其他namespace中的语句对多表查询中涉及的表进行的修改,引发脏数据问题。
在这个实验中,我们引入了两张新的表,一张class,一张classroom。class中保存了班级的id和班级名,classroom中保存了班级id和学生id。我们在StudentMapper中增加了一个查询方法getStudentByIdWithClassInfo,用于查询学生所在的班级,涉及到多表查询。在ClassMapper中添加了updateClassName,根据班级id更新班级名的操作。
当sqlsession1的studentmapper查询数据后,二级缓存生效。保存在StudentMapper的namespace下的cache中。当sqlSession3的classMapper的updateClassName方法对class表进行更新时,updateClassName不属于StudentMapper的namespace,所以StudentMapper下的cache没有感应到变化,没有刷新缓存。当StudentMapper中同样的查询再次发起时,从缓存中读取了脏数据。
(5)实验5:为了解决实验4的问题呢,可以使用Cache ref,让ClassMapper引用StudenMapper命名空间,这样两个映射文件对应的SQL操作都使用的是同一块缓存了。
执行结果:
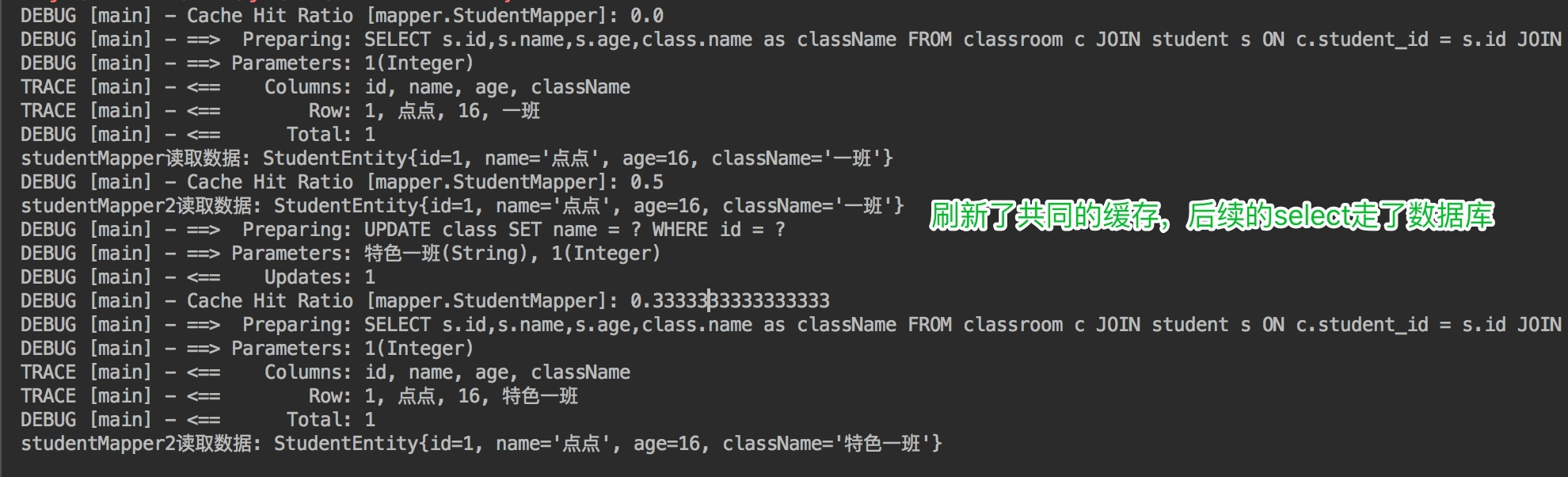
不过这样做的后果是,缓存的粒度变粗了,多个Mapper namespace下的所有操作都会对缓存使用造成影响。
4、源码分析
源码分析看这篇文章:聊聊MyBatis缓存机制
四、二级缓存分布式问题
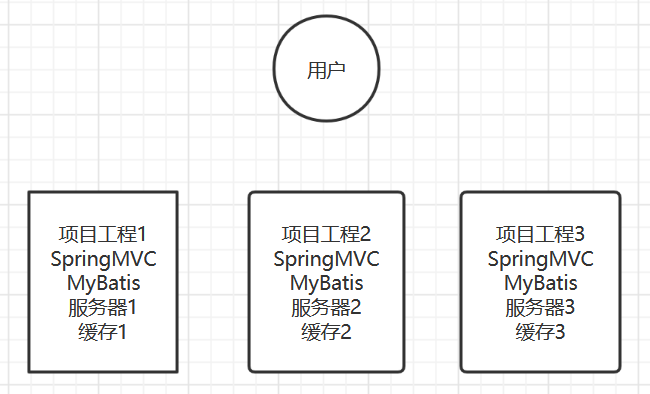
上面我们介绍了mybatis自带的二级缓存,但是这个缓存是单服务器工作,无法实现分布式缓存。
那么什么是分布式缓存呢?假设现在有两个服务器1和2,用户访问的时候访问了1服务器,查询后的缓存就会放在1服务器上,假设现在有个用户访问的是2服务器,那么他在2服务器上就无法获取刚刚那个缓存。如下图:缓存1、2、3均是独立的。
为了解决这个问题,就得找一个分布式的缓存,专门用来存储缓存数据的,这样不同的服务器要缓存数据都往它那里存,取缓存数据也从它那里取,如下图所示:
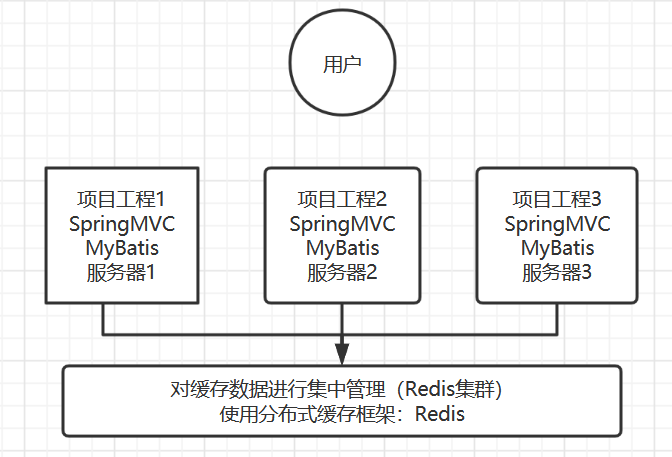
如上图所示,在几个不同的服务器之间,我们使用第三方缓存框架,将缓存都放在这个第三方框架中,然后无论有多少台服务器,我们都能从缓存中获取数据。
五、二级缓存的应用场景
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度。
业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分的,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题可能需要在业务层根据需求对数据有针对性缓存。