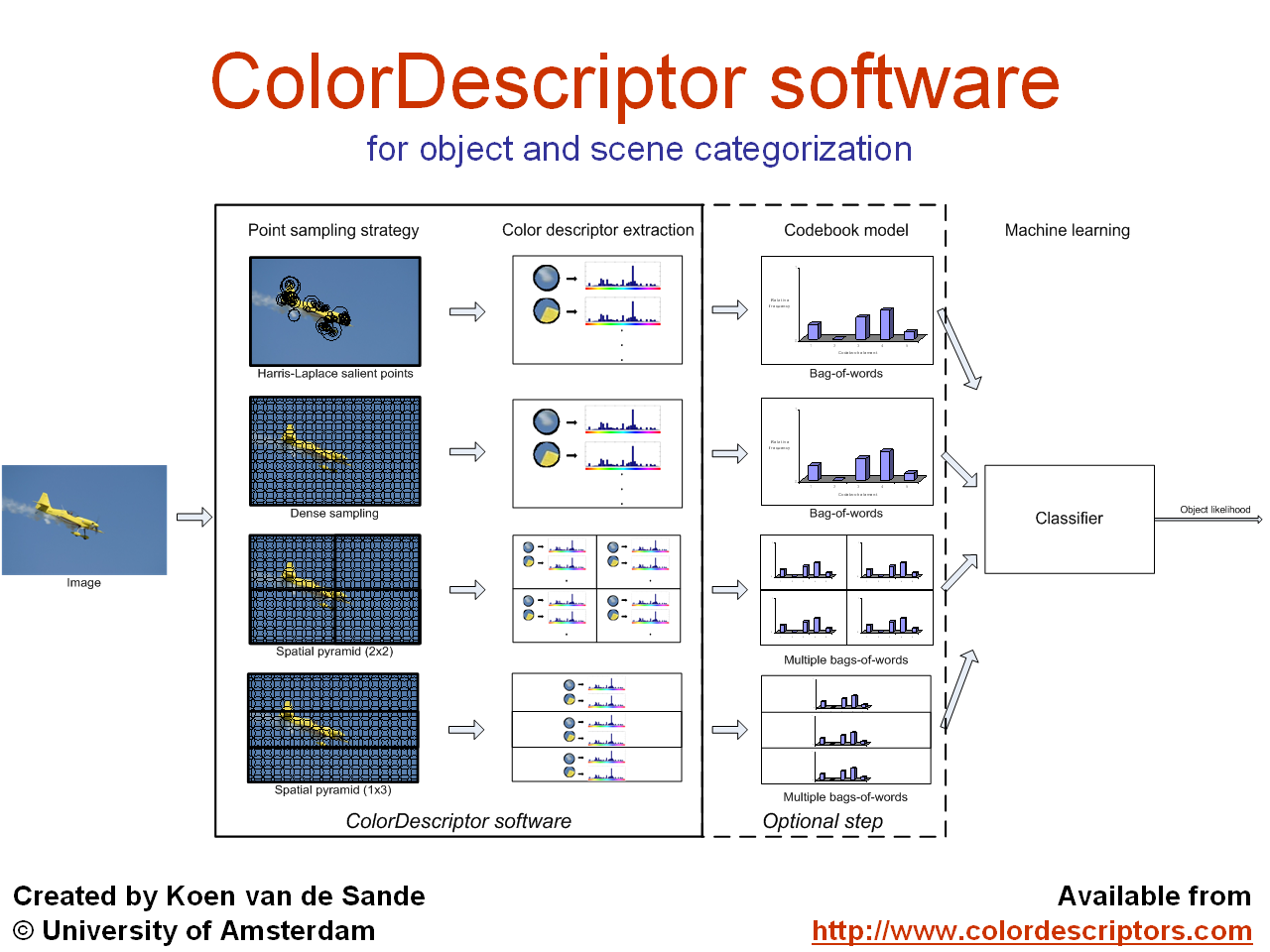
ColorDescriptor software v4.0
Created by Koen van de Sande, (c) University of Amsterdam
Note: Any commercial use of this software requires a license.
For additional information, contact Koen van de Sande)
Introduction
This document contains the usage information of the color descriptor binary software. For a more high-level overview, you should start reading on the main color descriptor website.
Usage
Use the binary to compute color descriptors within an image, such as color histograms and color SIFT. The input image can be in PNG or JPG formats. The detector and descriptor options are documented below:
colorDescriptor <image> --detector <detector> --descriptor <descriptor> --output <descriptorfile.txt>
Note: the new --batchmode interprets arguments differently; see the documentation below.
License
Copyright (c) Koen van de Sande / University of Amsterdam This software is provided 'as-is', without any express or implied warranty. In no event will the authors be held liable for any direct, indirect, consequential, special, incidental, or other damages, including but not limited to damages for lost profits, interruption of business, lost or corrupted data or programs, system crashes, or diversion of system or other resources, arising out of or relating to this license or the performance, quality, results, use of, or inability to use this software. The authors shall not be liable for any claim asserted against you by any other party, including but not limited to claims for infringement of copyright or other intellectual property rights. Any commercial use of this software requires a license from Euvision Technologies. This license must be retained with all copies of the software.
Citation
If you use this software, then please cite one the following two papers. The first is recommended for most users:
- Koen E. A. van de Sande, Theo Gevers and Cees G. M. Snoek, Empowering Visual Categorization with the GPU. IEEE Transactions on Multimedia volume 13 (1), pages 60-70, 2011. PDF version
- Koen E. A. van de Sande, Theo Gevers and Cees G. M. Snoek, Evaluating Color Descriptors for Object and Scene Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence volume 32 (9), pages 1582-1596, 2010. PDF version
BibTeX:
@Article{vandeSandeITM2011,
author = "van de Sande, K. E. A. and Gevers, T. and Snoek, C. G. M.",
title = "Empowering Visual Categorization with the GPU",
journal = "IEEE Transactions on Multimedia",
number = "1",
volume = "13",
pages = "60--70",
year = "2011",
url = "[url]http://www.science.uva.nl/research/publications/2011/vandeSandeITM2011[/url]"
}
@Article{vandeSandeTPAMI2010,
author = "van de Sande, K. E. A. and Gevers, T. and Snoek, C. G. M.",
title = "Evaluating Color Descriptors for Object and Scene Recognition",
journal = "IEEE Transactions on Pattern Analysis and Machine Intelligence",
volume = "32",
number = "9",
pages = "1582--1596",
year = "2010",
url = "[url]http://www.science.uva.nl/research/publications/2010/vandeSandeTPAMI2010[/url]"
}
Detectors
The detector option can be one of the following:
- --detector harrislaplace
- --detector densesampling
Harris-Laplace salient point detector
The Harris-Laplace salient point detector uses a Harris corner detector and subsequently the Laplacian for scale selection. See the paper corresponding to this software for references.
Additional options for the Harris-Laplace salient point detector:
--harrisThreshold threshold [default: 1e-9]
--harrisK k [default: 0.06]
--laplaceThreshold threshold [default: 0.03]
Dense sampling detector
The dense sampling samples at every 6th pixel in the image. For better coverage, a honeyrate structure is used: every odd row is offset by half of the sampling spacing (e.g. by 3 pixels by default). This reduces the overlap between points. By default, the dense sampling will automatically infer a single scale from the spacing parameter. However, you can also specify multiple scales to sample at, for example:
--detector densesampling --ds_spacing 10 --ds_scales 1.6+3.2
Additional options for the dense sampling detector:
--ds_spacing pixels [default: 6]
--ds_scales scale1+scale2+...
The default sampling scale for a spacing of 6 pixels is 1.2.
Descriptors
The following descriptors are available (the name to pass to --descriptoris shown in parentheses):
- RGB histogram (rgbhistogram)
- Opponent histogram (opponenthistogram)
- Hue histogram (huehistogram)
- rg histogram (nrghistogram)
- Transformed Color histogram (transformedcolorhistogram)
- Color moments (colormoments)
- Color moment invariants (colormomentinvariants)
- SIFT (sift)
- HueSIFT (huesift)
- HSV-SIFT (hsvsift)
- OpponentSIFT (opponentsift)
- rgSIFT (rgsift)
- C-SIFT (csift)
- RGB-SIFT(rgbsift), equal to transformed color SIFT (transformedcolorsift). See the journal paper for equivalence.
File format (text)
Files written using --output <filename>look as follows:
KOEN1 10 4 <CIRCLE 91 186 16.9706 0 0>; 28 45 4 0 0 0 9 14 10 119; <CIRCLE 156 179 16.9706 0 0>; 7 82 80 62 23 2 15 6 21 23; <CIRCLE 242 108 12 0 0>; 50 67 10 0 0 0 69 44 31 23 0 1; <CIRCLE 277 105 14.2705 0 0>; 21 12 0 0 7 18 127 50 2 0 0;
The first line is used as a marker for the file format. The second line specifies the dimensionality of the point descriptor. The third line describes the number of points present in the file. Following this header, there is one line per point.
The per-point lines all consist of two parts: a description of the point (<CIRCLE x y scale orientation cornerness>) and a list of numbers, the descriptor vector. These two parts can be seperated through the semicolon ;. The xand ycoordinates start counting at 1, like Matlab.
By default, the program uses a Harris-Laplace scale-invariant point detector to obtain the scale-invariant points in an image (these are refered to as CIRCLE in the file format of the descriptors).
File format (binary)
Files written using --outputFormat binary --output <filename>are written to disk as a binary file in the "BINDESC1" format. The main advantage of using binary files is that they are much more efficient to parse in other software. The DescriptorIO.py file included in the distribution contains functions to parse the different file formats in Python. Besides Python, the script also depends on NumPy. For Matlab, the readBinaryDescriptors.m file can be used to read the files.
Visual Codebooks
The visual codebook model is widely used for object and scene categorization. In terms of processing speed, it is often faster to immediately construct a histogram of the descriptor occurence frequencies, instead of storing all descriptors to disk first and then performing this step separately. As of version 2.1, there are three fileformats for a codebook: the first one is the text-format documented above, where every line is a codebook vector. The <CIRCLE> part of the descriptor will not be used for the codebook, but it needs to be present for the file to be valid. The second format is the binary format discussed above, which allows for fast loading of the codebook (as text file formats are rather slow). The third option are old "binary" codebooks created with older versions of the software (this custom file format is no longer needed).
- Through the --codebook filenameoption, a file with the codebook vectors can be specified. All file formats are supported by this option
- For efficiency, it is recommended to use the --codebookoption with the binary file format, as it loads much faster (about 0.5s for the text version, versus <0.05s for the binary version).
When using the codebook mode of the software, a single output vector will be written to the output file. This vector has length equal to the codebook size. If the spatial pyramid (see below) is used as well, then one vector per pyramid element will be written.
Note: The Linux version of colorDescriptorhas been compiled with ATLAS, which allows for efficient codebook usage. The Windows/Mac versions have not been compiled with these faster routines, and is therefore significantly slower.
Soft Assignment
One inherent component of the codebook model is the assignment of discrete visual words to continuous image features. There is a clear mismatch of this hard assignment with the nature of continuous features. In the Visual Word Ambiguity paper by Van Gemert soft-assignment of visual words to image features is investigated. The Codeword Uncertainty (UNC) is included in the software and can be used by specifying --codebookMode unc. The sigma parameter for uncertainty can be specified using --codebookSigma 90.
Alternate codebook output mode
The default codebook mode (--codebookMode hard) writes a single output vector to the output file. However, sometimes it is useful to know which point goes where in the feature vector. The alternative codebook mode --codebookMode hardindexoutputs all the points and the index of the codebook element to which it would have been assigned.
Spatial Pyramids
Using the --pointSelectoroption, you can use a spatial pyramid like Lazebnik. Possible calls include:
- --pointSelector pyramid-1x1-2x2
- --pointSelector pyramid-1x1-2x2-1x3
These are shorthands for the real specification language for pyramids: they would look like P1x1#0+P2x2#0+P2x2#1+P2x2#2+P2x2#3and
P1x1#0+P2x2#0+P2x2#1+P2x2#2+P2x2#3+P1x3#0+P1x3#1+P1x3#2when written out in full. Using this specification language, you can define your own custom pyramids.
Batch mode
If you specify the option --batch, then the image filename argument will be interpreted as the name of a textfile. This textfile should contain a list of images. The --outputoption is now interpreted to be an output folder. In batch mode, you can efficiently process many images in a single run of the software. Especially for the GPU (CUDA) version, where the initialization cost of the GPU is high (about 1 second) this is important to obtain a speedup.
Additional options
The following options are also available:
- --loadRegions filenameAllows loading of custom regions (e.g. your own detector) instead of using a built-in detector. The file should be in BINDESC1 or KOEN1-format, and the descriptors can be left out (making a typical line look like this: <CIRCLE 91 186 16.9706 0 0>;;).
- --saveRegions filenameAllows saving of just the regions, without any descriptors.
- --keepLimited nWrite a random subset of at most ndescriptors to disk, instead of all descriptors for an image.
Frequently Asked Questions
Error: Cannot find file
When the software complains that it cannot find a file, try using a relative path (i.e. a path that does not start with /) instead of an absolute path. Another solution is to only use files which are in the current folder.
What is the interpretation of scale?
The scale parameter was implemented to correspond with the Gaussian filter sigma at which points were detected. Therefore, the scale is not directly interpretable as the size of the region described in terms of number of pixels. However, it is linearly related the radius of the circular area described. To capture the area of the Gaussian originally used, we have a 3x magnification factor. But, remember that SIFT has 4x4 cells, and this is a measure for a single cell. So, because we are working with a radius, multiply by 2. Due to the square shape of the region, we need to extend the outer radius even further by sqrt(2), otherwise the corners of the outer cells are cut off by our circle. So, the largest outer radius is Round(scale * 3 * 2 * sqrt(2)). The area from which the SIFT descriptor is computed is a square which fits within a circle of this radius. Also, due to the Gaussian weighting applied within SIFT, the area that really matters is much, much smaller: the outer parts get a low weight.
For the default scale of 1.2, we get a outer circle radius of 10. The potential sampling area then becomes -10..10, e.g. a 21x21patch. However, the square area which fits inside this circle is smaller: about 15x15. The corners of this 15x15square touch the outer circle.
Are the descriptors normalized?
The SIFT-based descriptors are L2-normalized, and subsequently multiplied by 512 and rounded to an integer. To verify this, divide all elements of the descriptor by 512, and compute the L2 norm, which will be approximately 1. For color extensions of SIFT, each channel is normalized independently, hence the L2 norm of the whole descriptor will be 3. The histogram-based descriptors are L1-normalized.
Floating Point Exception
When launching the executable, it immediately exits with a floating point exception. One possible cause is a lack of certain SSE instructions in your CPU. However, that should only happen on some CPUs from 2005 or earlier. Also, this depends on how the executable is compiled. Currently (v2.1), the Linux 64-bit executable is provided in two versions: one that only requires SSE and SSE2, the other version also uses more recent SSE versions.
Error: version GLIBCXX_3.4.9 not found
The 32-bit Linux version is compiled on Debian 5. Your Linux distribution is too ancient for the binaries to work (the C++ runtimes are too old). The 64-bit Linux SSE2 version is much more forgiving.
Problems with high-resolution images
When you feed high-resolution images (e.g. photos directly from a digital camera with 3000x2000 pixels or similar) into the software, it can be very slow and/or run out of memory if you sample very dense. We resize our images to a resolution of at most (500,x) or (x,500) with x < 500 before processing them.
Why are the Windows/Mac versions so slow?
Applying the codebook uses the optimized ATLAS linear algebra routines on Linux. However, on Windows, we are unable to compile ATLAS using the Microsoft Visual C++ compiler. An alternative would be to use the Intel Math Kernel Library, and we would be happy to accept donations for its license cost.
Why is the direction (angle) field always 0?
Estimating the dominant orientation of a descriptor is useful in matching scenarios. However, in an object/scene categorization setting, the additional invariance reduces accuracy. Being able to discriminate between dominant directions of up and right is very useful here, and rotated down images are quite rare in an object categorization setting. Therefore, orientation estimation is disabled in the color descriptor software. The subsequent rotation of the descriptor to achieve rotation-invariance is still possible by supplying your own regions and angles for an image (through --loadRegions). However, by default, no such rotation is performed, since the default angle is 0.
Why do I get Not-a-Number in combination with soft codebook assignment
Be sure to specify the --codebookSigmaoption (e.g. set to 90), because the default value is 0 (which leads to a division by 0 and therefore to NaN).
Changelog
4.0 (2012-08-31)
- Improved speed in all versions. Therefore, the citation for the software has changed to the GPU journal paper.
- New: GPU-accelerated version (CUDA 4.2) for 64-bit Windows
- New: 64-bit Windows version, now with optimized Intel MKL, sponsored by Euvision technologies
- Mac version available again, sponsored by Euvision technologies
- Improved numerical stability for image areas with little texture
- Note: Any commercial use of this software requires a license
3.0 (2011-02-18)
- Added batch mode to process multiple images in a row
- Experimental GPU version (separate download, based on our GPU paper)
- Windows version now uses multiple threads
- Fixed example script for codebook construction when there are images with 0 descriptors
2.1 (2010-06-10)
- Greatly improved efficiency of I/O operations (reading/writing files)
- Improved efficiency of internal datastructures, reducing overhead on many operations (10-20%), improved speed of vector quantization (10-20%). Example time reduction: from 3.52s to 2.33s.
- The --codebookoption now reads files in any format, making the --codebookConvertoption redundant. It is recommended to use the BINDESC1 file format to store codebooks (e.g. the same format which you get from the --outputFormat binary)
- Fixed minor bug in the Harris-Laplace detector for the two smallest scales
- Provide an example script on how to build a codebook from a set of images
- For 64-bit Linux version: Provide additional executable with SSE/SSE2 support only, so they also work on older CPUs (v2.0 required SSE3/4 for certain platforms)
- BUGFIX: included readBinaryDescriptors.m example script no longer handles rows and columns incorrectly (e.g. it works now)
2.0 (2009-09-24)
- The citation for the software has changed to the journal version.
- Added RGB-SIFT descriptor.
- Added new binary file output mode --outputFormat binary. The binary file format is very efficient to write, and also very efficient to parse in other software.
- Added soft codebook assignment --codebookMode unc(UNC from the paper by Van Gemert et al). --codebookSigma 90controls the smoothing performed within the codebook.
- Changed the default scale for dense sampling to a better choice.
- Scale estimation in Harris-Laplace works better for small scales.
- Note: Storage format of binary codebooks (created using --codebookConvert) has changed; old files can still be read.
1.3 (2009-02-12)
- New codebook mode --codebookMode hardindexwhich outputs all the points and the index of the codebook element to which it would have been assigned. The normal --codebookMode hardwould only output the final feature vector, the new mode allows you to see which point goes where in the feature vector.
- Linux versions now use ATLAS for codebook projection, which is up to 5x faster.
1.2 (2008-12-15)
- Added transformedcolorhistogramto documentation (was already in the executable)
- Made huesiftautomatically use the parameters from the paper (instead of requiring additional command-line options)
1.1 (2008-11-20)
- Using the csiftdescriptor no longer crashes (memory was still used after it had been released, which gives a segmentation fault)
1.0 (2008-11-07)
- Initial release
The site and its contents are © 2008-2016 Koen van de Sande, except for the files (and other contents) that are © of the respective owners. This site is not affiliated with or endorsed by my employer. Any trademarks used on this site are hereby acknowledged. Should there be any problems with the site, please contact the webmaster.
ColorDescriptor software
See:
Koen E. A. van de Sande, Theo Gevers and Cees G. M. Snoek, Evaluating Color Descriptors for Object and Scene Recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence, volume 32 (9), pages 1582-1596, 2010. [PDF] [BibTeX]
for an evaluation of color descriptors carried out using this software. The paper provides a structured overview of color invariant descriptors in the context of image category recognition. The distinctiveness of color descriptors is assessed experimentally using two benchmarks from the image domain (PASCAL VOC 2007) and the video domain (Mediamill Challenge).
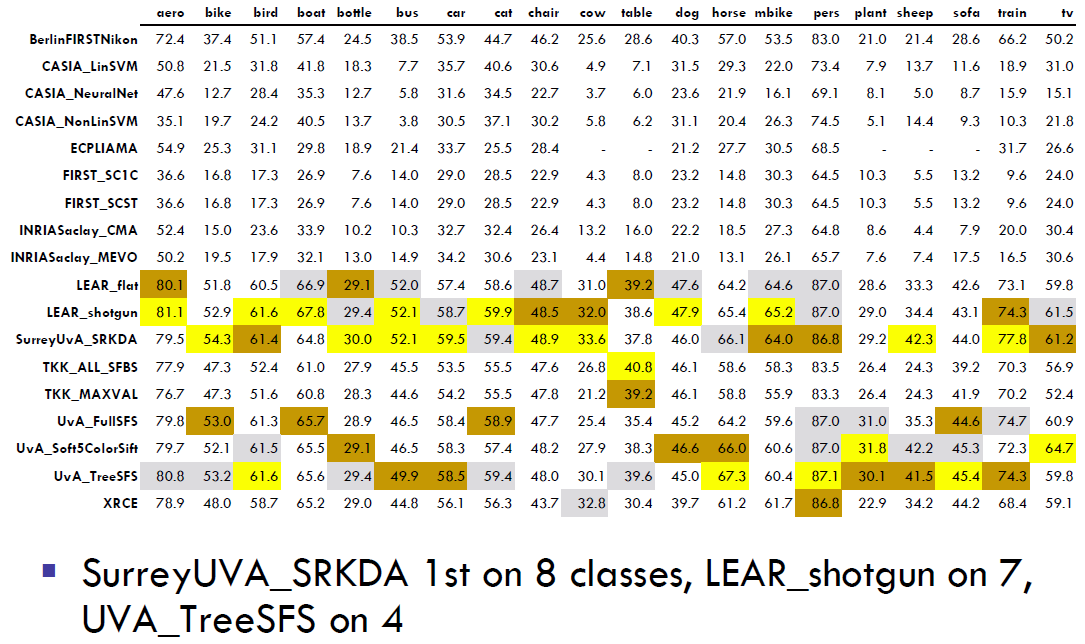
Besides our evaluation, these color descriptor have proven to be highly effective under many circumstances. See also our performance in the TRECVID 2008/2009 video retrieval benchmark, the ImageCLEF 2009 photo annotation task and our winning position (UvA submission = color descriptors + machine learning techniques) in the PASCAL VOC 2008 object classification competition. View our presentation at the PASCAL VOC 2008 workshop for additional information.
{kind=link}
Download
Koen E. A. van de Sande, Theo Gevers and Cees G. M. Snoek, Evaluating Color Descriptors for Object and Scene Recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence, volume 32 (9), pages 1582-1596, 2010. [PDF] [BibTeX]
Koen E. A. van de Sande, Theo Gevers and Cees G. M. Snoek, Empowering Visual Categorization with the GPU, IEEE Transactions on Multimedia volume 13 (1), pages 60-70, 2011. [PDF] [BibTeX]
- Download the ColorDescriptor software
- Documentation
- License
- For additional information, contact Koen van de Sande (
 )
)
The download includes binaries for the following platforms:
- GPU-acclerated Windows (64-bit), with Nvidia CUDA acceleration
- Windows (32-bit)
- Windows (64-bit), with Intel MKL acceleration
- Linux (32-bit)
- Linux (64-bit)
- Mac OS X (10.7 Lion 64-bit)
Related work
- David G. Lowe, Distinctive Image Features from Scale-Invariant Keypoints, IJCV 2004.
- Krystian Mikolajczyk and Cordelia Schmid, A Performance Evaluation of Local Descriptors, TPAMI 2005.
- Joost van de Weijer, Theo Gevers and Andrew Bagdanov, Boosting color saliency in image feature detection, TPAMI 2006.
- S. Lazebnik, C. Schmid and J. Ponce, Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories, CVPR 2006.
- J. Zhang, M. Marszalek, S. Lazebnik, and C. Schmid, Local features and kernels for classification of texture and object categories: A comprehensive study, IJCV 2007.
- G. J. Burghouts and J.-M. Geusebroek. Performance evaluation of local colour invariants, CVIU 2008.
- J. C. van Gemert, C. J. Veenman, A. W. M. Smeulders, J.-M. Geusebroek. Visual Word Ambiguity, TPAMI 2010.
from: http://koen.me/research/colordescriptors/readme
http://koen.me/research/colordescriptors/