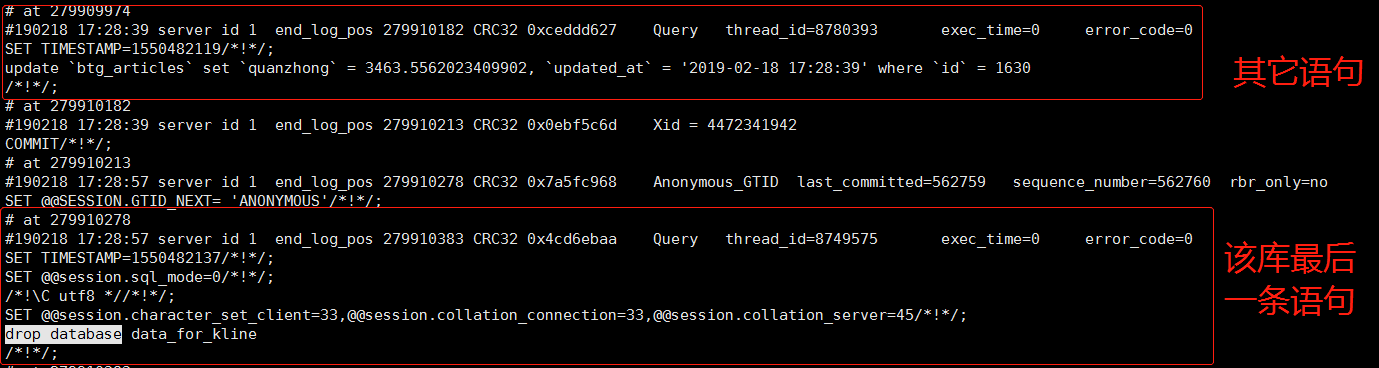
前提:由于slave磁盘未及时扩容原因导致磁盘即将写满,为了不影响业务将slave实例里一个10G的库drop了(项目前期建的库,数据现在已不使用了),然后又drop了master上的该库(对于大库建议先drop或truncate表再drop库,否则可能导致磁盘空间不能正常释放)。这时查看slave的主从状态,发现sql线程有异常,如下图:

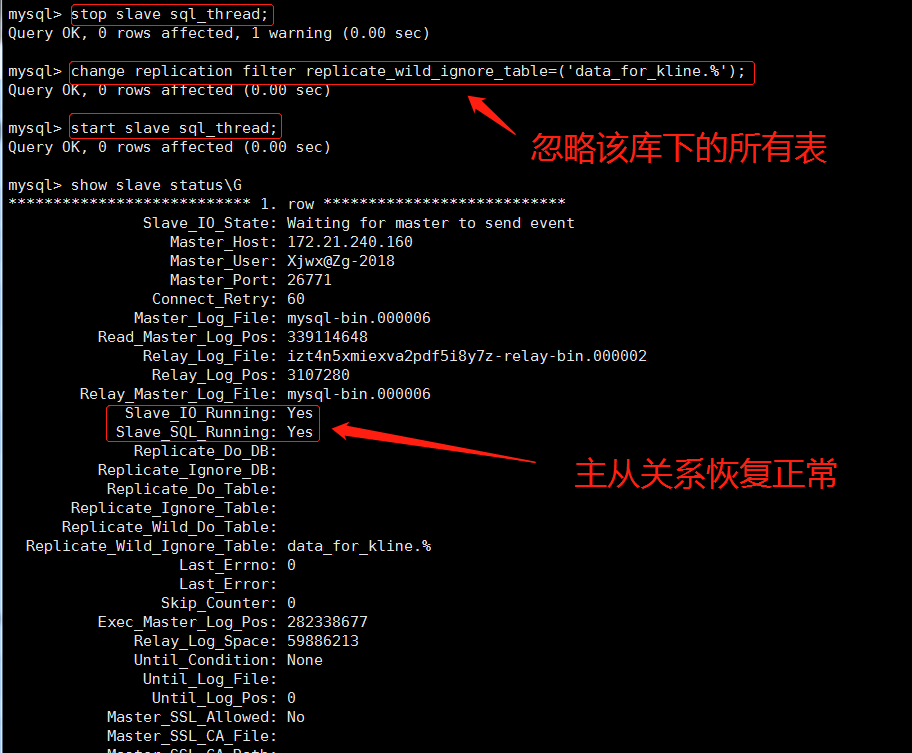
解决:记得该库下有200多张表,由于库已删,当时查询表数量的sql结果也不在了,所以具体有多少张表已无法核实,如果用STOP SLAVE;>SET GLOBAL SQL_SLAVE_SKIP_COUNTER=N;>START SLAVE;的方法跳过该错误肯定不合适,一个一个的跳过太慢了;批量跳过又有导致主从数据不一致的风险,假如有280张表,而你不知道具体表数量,如果跳过了281个,那恰巧第281个是一个严重需要解决的sql错误,那这时被跳过了就会导致主从数据不一致,为业务埋下隐患。所以在别人的提示下用如下方法解决,参考链接https://www.cnblogs.com/gomysql/p/4991197.html:
知识点扩展:
处理该错误的方法还有如下面一种方法,但我在这里未实际验证,所以只说方法。
1.方法:查看上面的第一张图,可以看到错误提示码为1146,在slave的my.cnf的[mysqld]段添加slave_skip_errors=1146,然后重启slave数据库,主从关系即可恢复正常。
2.还有人提出使用该方法处理的,但我认为该方法不可取,稍后说原因。方法:在master上用mysqlbinlog命令查看相关的binlog日志,然后用相关的pos点在slave上通过STOP SLAVE;>CHANGE MASTER TO MASTER_USER='XXX' ,MASTER_PASSWORD='XXX',MASTER_HOST='XXX',MASTER_PORT='XXX',MASTER_LOG_FILE='XXX',MASTER_LOG_POS='XXX';>START SLAVE;语句进行恢复。该方法不可取的原因是因为该实例下还有别的库,其他库在你删除200多张表的时间内也是在进行sql操作的,这样移动pos点就将这中间其他库穿插操作的sql也忽略了,这样就造成了主从不一致。从上图可以看出该库该类型错误的开始POS点是279231717,而该库该类型的最后一条执行语句的结束POS点是279910383,中间穿插其他库语句的POS点是279910182,综上所述该方法不可取。POS点见下图: