1.选一个自己感兴趣的主题或网站。(所有同学不能雷同)
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas # 将文章的正文内容保存到文本文件。 def writeNewsDetail(content): f = open('books.txt', 'a',encoding='utf-8') f.write(content) f.close() #一篇文章的全部信息 def getBooksDetail(pageurl): resd = requests.get(pageurl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') books={} books['title'] = soupd.select('.entry-header')[0].text info = soupd.select('.entry-meta-hide-on-mobile')[0].text books['dt'] = datetime.strptime(info[0:11], '%Y/%m/%d ') if(info.find('分类:')): books['classify']=soupd.select('.entry-meta-hide-on-mobile a')[0].text else: books['classify']='none' if (info.find('标签:')): books['label'] = soupd.select('.entry-meta-hide-on-mobile a')[2].text else: books['label'] = 'none' books['comment']= soupd.select('.entry-meta-hide-on-mobile a')[1].text books['html']=soupd.select('.copyright-area')[0].text books['content'] = soupd.select('.entry p')[0].text books['url'] = pageurl writeNewsDetail(books['content']) return (books) # 文章列表页的总页数 def getPageN(): res = requests.get('http://www.importnew.com/all-posts') res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') page = soup.select(".navigation a")[-2].text print(page) #一个列表页全部内容 def getListPage(pageurl): res = requests.get(pageurl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') newsList = [] pageurls = soup.select(".read-more a") for i in range(int(len(pageurls))): pageurl = soup.select(".read-more a")[i].attrs['href'] newsList.append(getBooksDetail(pageurl)) return (newsList) newsTotal = [] firstPageUrl = 'http://www.importnew.com/all-posts' newsTotal.extend(getListPage(firstPageUrl)) n = getPageN() dt =pandas.DataFrame(newsTotal) dt.to_excel("books.xlsx") print(dt)
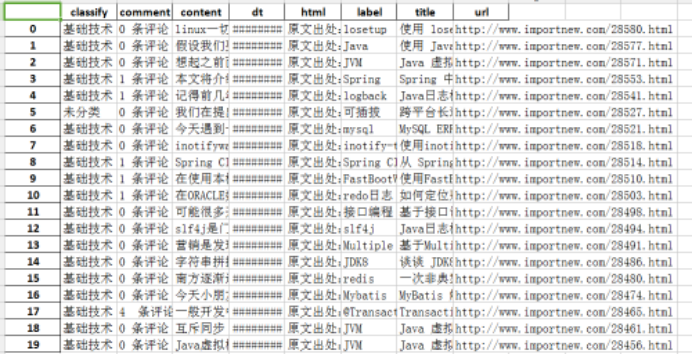


3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
import jieba.analyse from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator lyric= '' f=open('books.txt','r',encoding='utf-8') for i in f: lyric+=f.read() result=jieba.analyse.textrank(lyric,topK=50,withWeight=True) keywords = dict() for i in result: keywords[i[0]]=i[1] print(keywords) image= Image.open('tim.png') graph = np.array(image) wc = WordCloud(font_path='./fonts/simhei.ttf',background_color='White',max_words=50,mask=graph) wc.generate_from_frequencies(keywords) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.imshow(wc.recolor(color_func=image_color)) plt.axis("off") plt.show() wc.to_file('dream.png')
运行结果:

总结:在写大作业时候,我首先是获取总的页面个数、获取首页页码链接和页面信息展示,在编写获得单个页面所有链接出了点问题,一直找不到准确的标签,所有爬取数据有偏差。
然后就是进行词云生成,我参照了网上的案例,然后对自己爬取的数据进行词云分析、生成。这次爬取的是一个计算机文章方面的网站,将网站里面的标题、时间、发布者、内容等标签全部爬取,从而生成的词云。
可以说这次作业遇到的问题很多,同时也学到了很多。