kafka的定义:
- kafka是一款基于发布与订阅的消息系统。它一般被称为“分布式提交日志”或者“分布式流平台”。
- 文件系统或者数据库提交日志用来提供所有事物的持久化记录,通过重建这些日志可以重建系统的状态。
- 同样地,kafka的数据是按照一定顺序持久化保存的,可以按需读取。
kafka的特点:
- 同时为分布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万条消息(50MB),每秒处理55万条消息(110MB)这里说条数,可能不上特别准确,因为消息的大小可能不一致;
- 可进行持久化操作,将消息持久化到到磁盘,以日志的形式存储,因此可用于批量消费,例如ETL,以及实时应用程序。 通过将数据持久化到硬盘以及replication防止数据丢失。
- 分布式系统,易于向外拓展。所有的Producer、broker和consumer都会有多个,均为分布式。无需停机即可拓展机器。
- 消息被处理的状态是在consumer端维护,而不是由server端维护,当失败时能自动平衡。
- 支持Online和offline的场景。
Kafka的核心概念

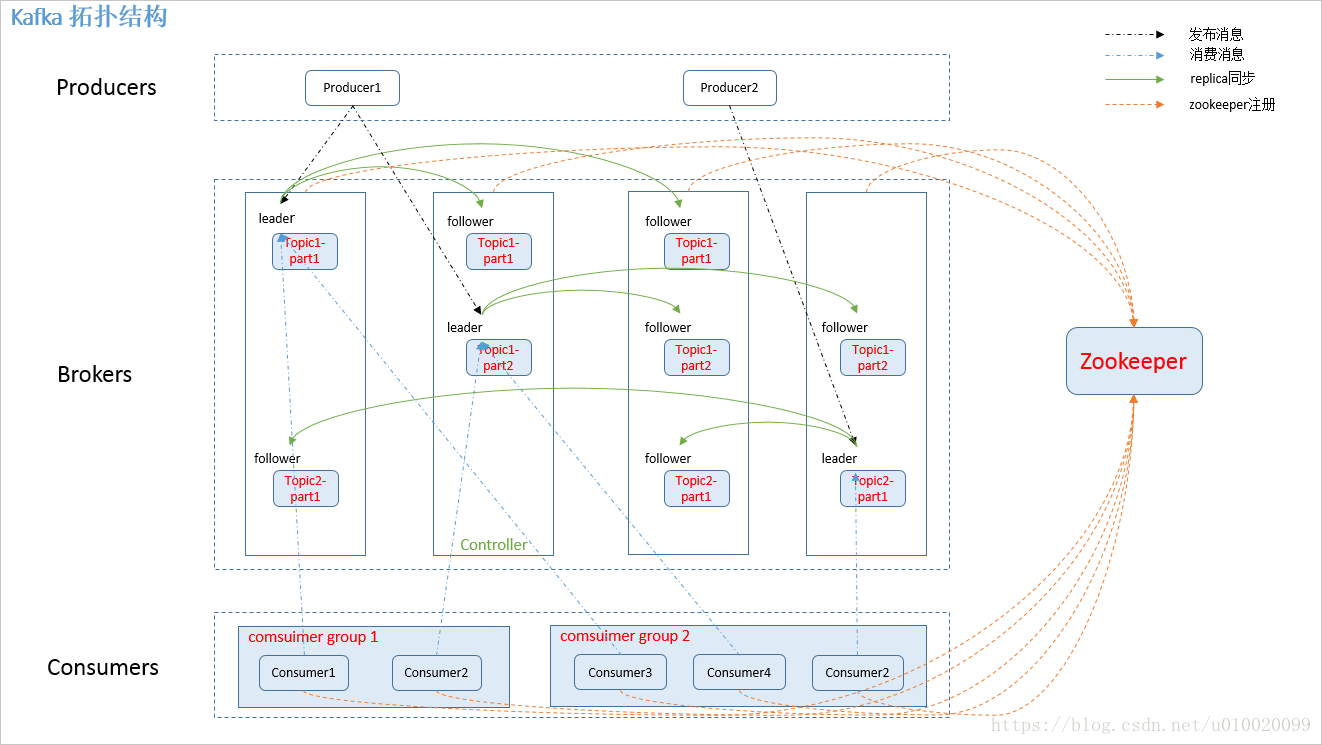
kafka的拓扑结构:
————————————————
版权声明:本文为CSDN博主「u010020099」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010020099/article/details/82290403
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
kafka应用场景:
- 消息投递:能够很好的代替传统的message broker。它提供了 更强大的吞吐量,内建分区,复本,容错等机制来解决大规模 消息处理型应用程序。
- 用户活动追踪:通过按类型将每个web动作发送到指定topic,然 后由消费者去订阅各种topic,处理器包括实时处理,实时监控, 加载到hadoop或其他离线存储系统用于离线处理等。
- 日志聚合:把物理上分布在各个机器上的离散日志数据聚集到 指定区域(如HDFS或文件服务器等)用来处理。
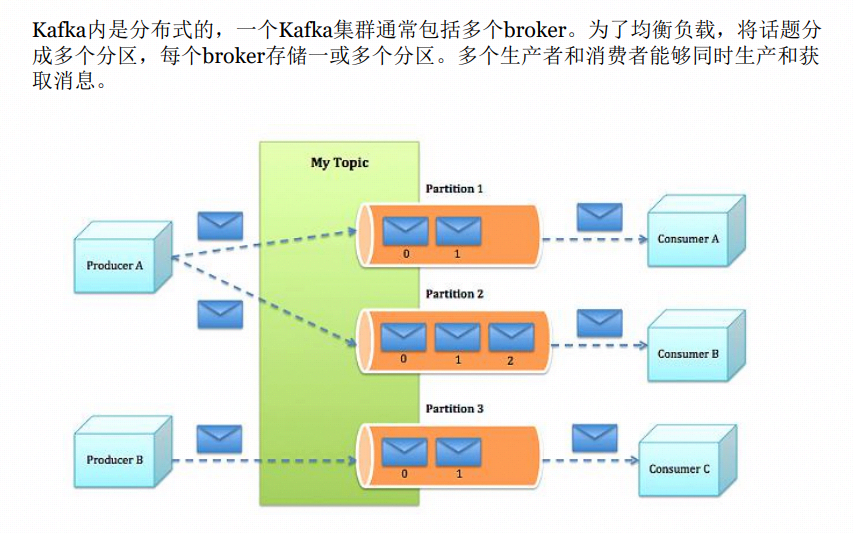
kafka组件:
-----------------------------------------------------------------------------------Kafka构造及原理-----------------------------------------------------------------------
- Kafka的存储布局非常简单。话题的每个分区对应一个逻辑日志。物理上,一 个日志为相同大小的一组分段文件。每次生产者发布消息到一个分区,代理 就将消息追加到最后一个段文件中。当发布的消息数量达到设定值或者经过 一定的时间后,段文件真正flush磁盘中。写入完成后,消息公开给消费者。
- 与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息Id。
- 消息通过日志中的逻辑偏移量来公开。这样就避免了维护配套的密集寻址, 用于映射消息ID到实际消息地址的随机存取索引结构的开销。消息ID是增量 的,但不连续。要计算下一消息的ID,可以在其逻辑偏移的基础上加上当前 消息的长度。
- 消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量, 也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步拉请求, 准备字节缓冲区用于消费。每个异步拉请求都包含要消费的消息偏移量
队列结构:
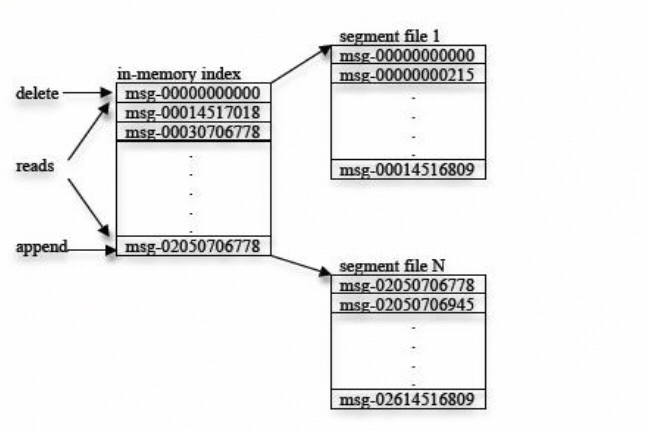
传输效率
- 生产者提交一批消息作为一个请求。消费者虽然利用api遍历消 息是一个一个的,但背后也是一次请求获取一批数据,从而减 少网络请求数量。
- Kafka层采用无缓存设计,而是依赖于底层的文件系统页缓存。 这有助于避免双重缓存,及即消息只缓存了一份在页缓存中。 同时这在kafka重启后保持缓存warm也有额外的优势。
- 因kafka 根本不缓存消息在进程中,故gc开销也就很小。
- zero-copy:kafka为了减少字节拷贝,采用了大多数系统都会 提供的sendfile系统调用。
- 如下图:
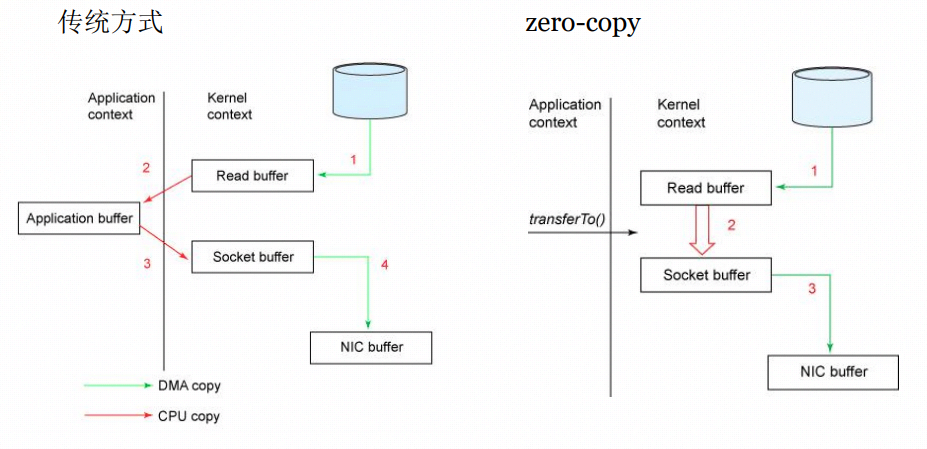
传统方式: 当需要对一个文件进行传输的时候,其具体流程细节如下: 1、调用read函数,文件数据被copy到内核缓冲区 2、read函数返回,文件数据从内核缓冲区copy到用户缓冲区 3、write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。 4、数据从socket缓冲区copy到相关协议引擎。
zero-copy:运行流程如下: 1、sendfile系统调用,文件数据被copy至内核缓冲区 2、再从内核缓冲区copy至内核中socket相关的缓冲区 3、最后再socket相关的缓冲区copy到协议引擎
原文链接:https://www.cnblogs.com/fengyv/p/3775953.html