一、项目目标
爬取豆瓣TOP250电影的评分、评价人数、短评等信息,并在其保存在txt文件中,html解析方式基于正则表达式
二、确定页面内容
爬虫地址:https://movie.douban.com/top250
确定爬取内容:视频链接,视频名称,导演/主演名称,视频评分,视频简介,评价人数等信息
打开网页,按F12键,可获取以下界面信息
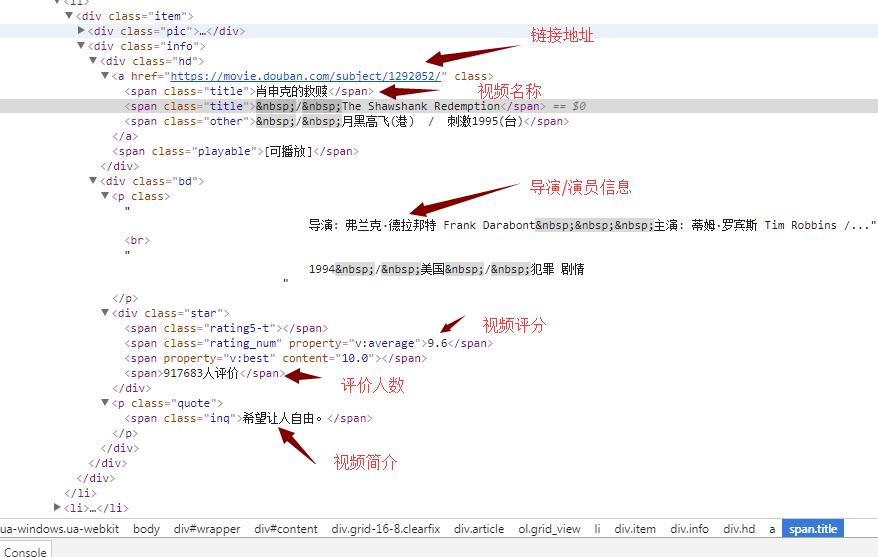
观察可知,每一部视频的详细信息都存放在li标签中
每部视频的视频名称在 class属性值为title 的span标签里,视频名称有可能有多个(中英文);
每部视频的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
每部视频的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
每部视频的链接在对应li标签里的一个a标签里
每部视频的简介在对应li标签里的一个class属性值为ing的标签里
python 代码如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017/12/1 15:55 # @Author : gj # @Site : # @File : test_class.py # @Software: PyCharm import urllib2,re,threading ''' 伪造头信息 ''' def Get_header(): headers = { 'USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5' } return headers ''' 获取页面内容 ''' def Spider(url,header): req = urllib2.Request(url=url,headers=header) html = urllib2.urlopen(req) info = html.read() return info def Analyse(infos): pattern = re.compile('<ol class="grid_view">(.*?)</ol>',re.S) info = pattern.findall(infos) pattern = re.compile("<li>(.*?)</li>",re.S) movie_infos = pattern.findall(info[0]) movie=[] for movie_info in movie_infos: movie_temp=[] url = "" title="" director="" score="" peoples="" inq="" #获取链接地址 pattern_url = re.compile('<a href="(.*?)" class="">') movie_urls = pattern.findall(movie_info) for movie_url in movie_urls: url = url+movie_url movie_temp.append(url) # 获取视频名称 pattern_title = re.compile('<span class="title">(.*?)</span>') movie_titles = pattern_title.findall(movie_info) for movie_title in movie_titles: title = title+movie_title movie_temp.append(title) # 获取视频演员表 pattern_director = re.compile('<p class="">(.*?)<br>',re.S) movie_directors = pattern_director.findall(movie_info) for movie_director in movie_directors: director = director+movie_director movie_temp.append(director) #获取视频评分 pattern_score = re.compile('<div class="star">.*?<span class="rating_num" property="v:average">(.*?)</span>.*?<span>(.*?)</span>.*?</div>',re.S) movie_scores = pattern_score.findall(movie_info) for movie_score in movie_scores: score = movie_score[0] peoples = movie_score[1] break movie_temp.append(score) movie_temp.append(peoples) # 获取视频简介 pattern_inq = re.compile('<p class="quote">.*?<span class="inq">(.*?)</span>.*?</p>',re.S) movie_inqs = pattern_inq.findall(movie_info) if len(movie_inqs)>0: inq = movie_inqs[0] else: inq ='该视频无简介' movie_temp.append(inq) movie.append(movie_temp) return movie ''' 将返回内容写入文件 ''' def write_file(infos): #防止多个线程写文件造成数据错乱 mutex.acquire() with open("./movie.txt","ab") as f: for info in infos: write_info = "" for i in range(0,len(info)): info[i] = info[i].replace(" ","") write_info = write_info+info[i]+" " write_info= write_info+" " f.write(write_info) mutex.release() def start(i): url = "https://movie.douban.com/top250?start=%d&filter="%(i*25) headers = Get_header() infos= Spider(url,headers) movie_infos = Analyse(infos) write_file(movie_infos) def main(): #创建多线程 Thread = [] for i in range(0,10): t=threading.Thread(target=start,args=(i,)) Thread.append(t) for i in range(0,10): Thread[i].start() for i in range(0,10): Thread[i].join() if __name__ == "__main__": #加锁 mutex = threading.Lock() main()
最终结果会在当前目录下生成一个movie.txt txt中记录了每部视频的相关信息,大概格式如下(没有过多的调整文件格式,这里面可以写入mysql,或者写入execl中,更加方便查看)

以上就是基于正则表达式来获取豆瓣排名钱250的电影信息的爬虫原理及简单脚本。