一、问题发现
近期我在做代理池的时候,发现了一种以前没有见过的反爬虫机制。当我用常规的requests.get(url)方法对目标网页进行爬取时,其返回的状态码(status_code)为521,这是一种以前没有见过的状态码。再输出它的爬取内容(text),发现是一些js代码。看来是新问题,我们来探索一下。
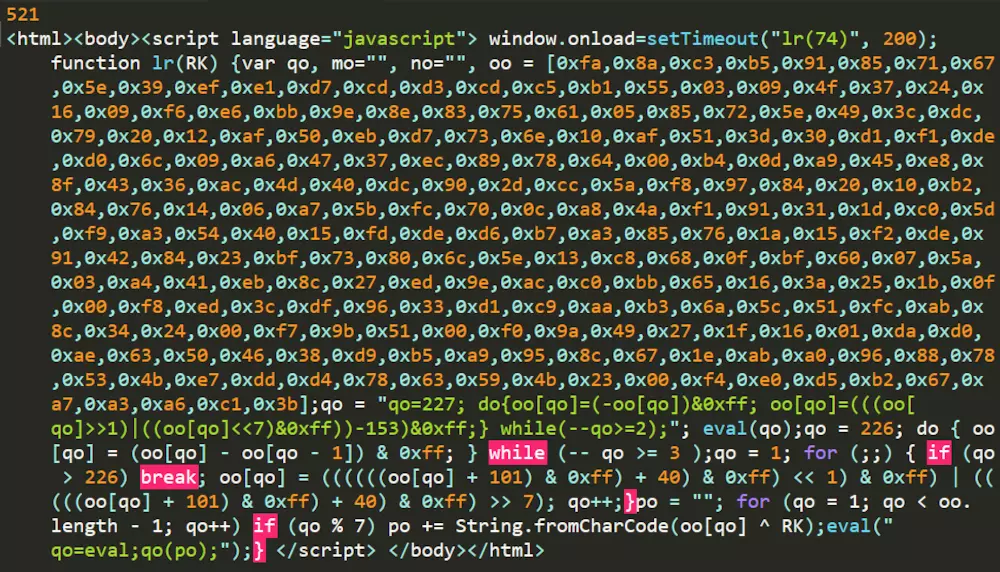
二、原理分析
打开Fiddler,抓取访问网站的包,我们发现浏览器对于同一网页连续访问了两次,第一次的访问状态码为521,第二次为200(正常访问)。看来网页加了反爬虫机制,需要两次访问才可返回正常网页。

下面我们来对比两次请求的区别:
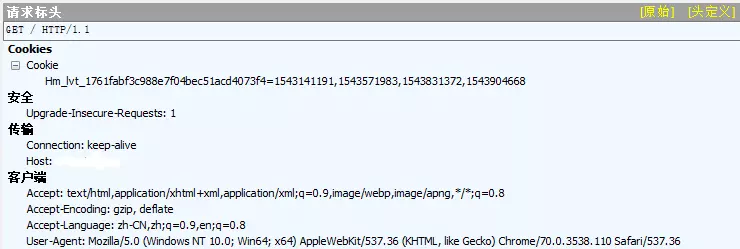
521请求:
200请求:
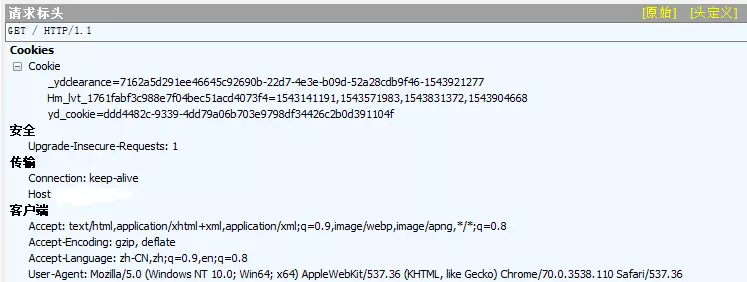
通过对比两次请求头,我们发现第二次访问带了新的cookie值。再考虑上面程序对爬取结果的输出为js代码,可以考虑其操作过程为:第一次访问时服务器返回一段可动态生成cookie值的js代码;浏览器运行js代码生成cookie值,并带cookie重新进行访问;服务器被正常访问,返回页面信息,浏览器渲染加载。
三、解决流程
弄清楚浏览器的执行过程后,我们就可以模拟其行为通过python作网页爬取。操作步骤如下:
-
用request.get(url)获取js代码
-
通过正则表达式对代码进行解析,获得JS函数名,JS函数参数和JS函数主体,并将执行函数eval()语句修改为return语句返回cookie值
-
调用execjs库的executeJS()功能执行js代码获得cookie值
-
将cookie值转化为字典格式,用request.get(url, cookies = cookie)方法获取得到正确的网页信息
四、代码实现
实现程序所需要用到的库:
import re #实现正则表达式
import execjs #执行js代码
import requests #爬取网页
第一次爬取获得包含js函数的页面信息后,通过正则表达式对代码进行解析,获得JS函数名,JS函数参数和JS函数主体,并将执行函数eval()语句修改为return语句返回cookie值。
# js_html为获得的包含js函数的页面信息
# 提取js函数名
js_func_name = ''.join(re.findall(r'setTimeout("(D+)(d+)"', js_html))
# 提取js函数参数
js_func_param = ''.join(re.findall(r'setTimeout("D+((d+))"', js_html))
# 提取js函数主体
js_func = ''.join(re.findall(r'(function .*?)</script>', js_html))
将执行函数eval()语句修改为return语句返回cookie值
# 修改js函数,返回cookie值
js_func = js_func.replace('eval("qo=eval;qo(po);")', 'return po')
调用execjs库的executeJS()功能执行js代码获得cookie值
# 执行js代码的函数,参数为js函数主体,js函数名和js函数参数
def executeJS(js_func, js_func_name, js_func_param):
jscontext = execjs.compile(js_func) # 调用execjs.compile()加载js函数主体内容
func = jscontext.call(js_func_name,js_func_param) # 使用call()通过函数名和参数执行该函数
return func
cookie_str = executeJS(js_func, js_func_name, js_func_param)
将cookie值转化为字典格式
# 将cookie值解析为字典格式,方便后面调用
def parseCookie(string):
string = string.replace("document.cookie='", "")
clearance = string.split(';')[0]
return {clearance.split('=')[0]: clearance.split('=')[1]}
cookie = parseCookie(cookie_str)
获得cookie后,采用带cookie的方式重新进行爬取,即可获得我们需要的网页信息了。
作者:欲摘桃花换酒钱
链接:https://www.jianshu.com/p/37d549a4bf44
来源:简书