已经准备的面试题
12月5日 刷完Java基础和MysqlRedis
剩余Spring Mybatis Netty RabbitMQ Storm面试题
智力题
资料
1000瓶酒找毒酒问题
- 题目:其中一瓶有毒,一旦吃了,都会在一周后发作,现在我们用小老鼠做实验,要在1周后找出那桶毒酒,问最少需要多少只老鼠?
- 题解:用10只老鼠即可。把这个问题转换成二进制数就好理解了,第一桶到第1000桶都对应着一个二进制的数字,每个老鼠对应二进制的一位。对每一桶酒来说,把二进制位上为1的给对应位置的老鼠喝。等到毒发时,统计哪几位上的老鼠死了,然后转换成十进制就可以了。
- 资料:资料
等概率选择商店问题
- 题目:有3家商店,手上有一个硬币,怎么等概率地选择一家商店;注意:正反出现的概率相同,都为0.5
- 题解:用二进制来理解三家商店,01 10 11,分别代表三家商店,抛两次硬币就可以了
量水问题
- 题目: 用3升,5升杯子怎么量出4升水?
- 题解:
- 用5升杯子装满水,倒入3升杯子,还剩2升
- 把2升倒入3升杯子,然后把5升装满
- 倒入3升杯子,5升杯子就剩了4升
找出较重的球
- 题目:假设你有8个球,其中一个略微重一些,但是找出这个球的惟一方法是将两个球放在天平上对比。最少要称多少次才能找出这个较重的球?
- 题解:分成3+3+2
- 第一次称3和3
- 如果相等,证明重的球在2个球的堆里,再称一次就能得出结果
- 如果不相等,从较重的那堆3个中,随机那两个称重就能得到最重的球
- 第一次称3和3
赛马问题(参考资料:Google-25匹马的角逐)
-
题目:一共有25匹马,有一个赛场,赛场有5个赛道,就是说最多同时可以有5匹马一起比赛。假设每匹马都跑的很稳定,不用任何其他工具,只通过马与马之间的比赛,试问最少 得比多少场才能知道跑得最快的5匹马。
-
第一种解法
- 将25匹马分成5个组进行比赛,A组到E组,得到每组的第一名A1~E1
- A1~E1进行比赛,得到第一名,假设是A1
- A2,B1,C1,D1和E1进行比赛,可以得到第二名
- 依次类推,一共需要比赛10场就能得到前五名的马
-
第二种优化解法
优化方式:
- 让一些马提前淘汰
- 能够通过一场比赛决定出更多的名次
第一步和第二步必不可少,前6场比赛后,B组的最后一名,C组的最后两名,D组的最后三名,E组的最后四名这些马已经提前淘汰了。
第七场比赛,通过A2和B1就可以决出第二名,剩下三个名额是否可以同时决出第二名和第三名?
- 如果A2>B1,那么第三名一定在A3和B1中产生
- 如果B1>A2,那么第三名在A2,B2,C1中产生
所以第七场比赛,让A2,B1,B2,C1,A3比赛即可决定第二名和第三名
根据第七场比赛的所有可能结果,可以继续按照这个方法推测每场比赛需要的比赛马
称盐问题
- 题目:140g盐,只有一个2g砝码和7g砝码,还有一个天平,称三次,分成50g和90g两堆。
- 题解
- 先用天平分成70g的两堆
- 用2+7g的砝码称出9g的盐
- 2g的砝码和9g的盐称出50g的盐
烧香问题-确定15分钟
- 题目:两个棍子,长度不一,粗细不一,质量密度都不一。但一小时能燃烧完。我如何确定15分钟。
- 题解:A棍子点两头,B棍子点一头,等到A棍子烧完之后,再点B棍子的另一头,从开始点到烧完既是15分钟。
烧香问题-确定45分钟
- 题目:两个棍子,长度不一,粗细不一,质量密度都不一。但一小时能燃烧完。我如何确定45分钟。
- 题解:A棍子点两头,B棍子点一头,开始计时,等到A棍子烧完之后,再点B棍子的另一头,烧完整个时间是45分钟。
N个人找明星问题
- 题目:有N个人,其中一个明星和n-1个群众,群众都认识明星,明星不认识任何群众,群众和群众之间的认
识关系不知道,现在如果你是机器人R2T2,你每次问一个人是否认识另外一个人的代价为O(1),试设计
一种算法找出明星,并给出时间复杂度(没有复杂度不得分)。 - 题解:从头开始遍历,1号如果不认识2号,那么2号不是明星;1号如果认识2号,那么1号不是明星。从头遍历到尾,剩下的那个人就是明星,时间复杂度O(N)。
判断一个点在三角形中问题
- 题目:如何判断一个点在三角形中
- 题解:
- 第一种:角度和,把p连接三角形的顶点,分别求角度和,如果为180°,则P点在三角形内
- 第二种:向量的叉乘。
- P和C在AB的同侧
- P和B在AC的同侧
- P和A在BC的同侧。
放棋子必胜问题
-
题目:一个圆,有黑白两种棋子,两个人放棋,一个一次只能方一枚棋子,最后放不了那个人算输,请给出一个必胜的方案
-
题解:我方先放,放在圆心即可。
因为其他棋子都围绕圆心中心对称,所以我方会多一个棋子。
沙漠加油问题
- 题目:你一次只能最多带走60km的油,只能在起点加油,如何穿越80km的沙漠?
- 题解:
- 第一次装满60km的油,然后走到20km处,卸下20km的油,再返回起点
- 在起点再加油60km,到达刚才的20km处时,你还剩40km的油,加上刚才放的20km的油,即可走完全程。
算法题
两个单链表相交,怎么求交点。所谓相交,就是两个节点的next指针相同
简单解法:分别遍历两个单链表,把元素分别存储到一个List中。然后倒叙遍历List,得到第一个不同的节点的下一个节点就是交点。时间复杂度O(N),空间复杂度O(N)
优雅解法:分别遍历两个链表获取长度,让长度长的那个链表,先走长度差步,然后一起走,两个指针相遇的节点就是交点。时间复杂度O(N),空间复杂度O(1)
如何判断两个单链表是否相交?
从头遍历到尾,然后判断最后一个节点是否相同,如果相同则相交。
给你一个数组,代表每天股票的价格,比如【3,5,4,6,2,5】表示6天的价格,问如果只能买一次,并且提前知道每天的价格,最大收益是多少
O(N)的时间复杂度就可以算出来。
双指针,一个head,一个tail,tail从头开始遍历,如果tail的值大于等于head,计算一次max;如果tail<=head,不计算,让head=tail,然后继续往后遍历。遍历结束就可以得到最大的收益。
给n个有序数组,求一个区间[a, b],确保每一个数组至少有一个值在区间内,并使区间最小。
还是用最小堆来解决问题。
先把每个数组的第一个值拿出来生成第一个最小堆。
然后把堆顶元素剔除,从被剔除的堆顶元素数组中拿下一个元素放入堆中,重新生成最小堆。
直到某一个数组元素遍历到末尾。
设计一个循环队列,区别于arraylist的扩容机制,空间可重用。
队列满的条件:(write + 1) % arr.length == tail
队列空的条件:tail == write
找一个无序数组的中位数
解法一
利用排序,写完排序后,根据数组的容量是奇数还是偶数,直接取中位数即可。
解法二
可以利用小顶堆实现。
- 取数组的前半数据建立小顶堆
- 数组的后半部分每个数据与小顶堆的顶比较
- 如果小于等于抛弃
- 如果大于等于,入堆,最后得到的堆顶就是中位数
堆的介绍
堆是完全二叉树。(满二叉树,除了最后一层,每一层都有两个孩子节点;完全二叉树不要求满,但要求节点从左到右,不能有空袭位置没有子节点)
完全二叉树,可以给每一个节点编号,从上到下,从左到右,对任意一个节点i,它的父节点的编号都为i/2,它的左孩子节点都为2*i,右孩子节点2 * i +1
所以我们可以使用数组来存储,编号对应的就是数组的位置。
|a-b|+|b-c|+|c-a|的最大值或者最小值
题目
给三个数组,从三个数组中选择三个数,求|a-b|+|b-c|+|c-a|的最大值或者最小值
题解
假设a>=b>=c,那么化简之后的结果为
(a-b) + (b-c) + (a-c) = 2(a-c) 也就是说,结果只与这三个数的最大值和最小值相关。
数据流中如何取前十个小的数
用大顶堆来解就可以了。
先用数据流构建一个10长度的大顶堆,然后数据流后面的数据每一个和大顶堆的堆顶对比,如果比堆顶大,抛弃,如果比堆顶小,替换堆头,然后重新排序保证堆为最大堆。
MySQL的排序如果有limit N,内部会使用这种算法来进行排序。
如何判断单链表里有无环 并且找到环的头节点
判断有无环的方法:
用快慢指针,快指针一次走两步,慢指针一次走一步,如果两个指针最终相遇,说明有环。
证明:用归纳法证明。假设慢指针刚进入环时
- 快指针在慢指针后面的一个节点,那么再走一步,二者相遇
- 快指针在慢指针后面的两个节点,那么再走两步,二者相遇
找到环的头节点方法:
算法:相遇后,在head中再加入一个指针,从头开始走,慢指针也继续往前走,速度一样,相遇点即为环的头节点
证明:
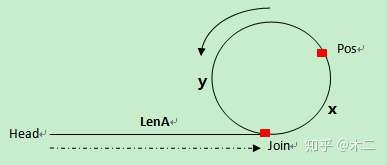
先证明,快慢指针相遇时,慢指针还没有走完一圈。
假设慢指针入环时,快指针距离慢指针还有M步,由上面证明可知再走M步快慢指针必相遇,因为M小于环的周长R(因为如果等于的话,就直接相遇了,不需要追击,慢指针进入环时,快指针一定在环的某个位置),所以慢指针还没有绕环一圈。
慢指针走过路程:S = lenA+x;
快指针走过路程:2S = lenA + x + n*R(可能已经走过N圈了)
化简得到 lenA = n*R-x
我们想要证明 慢指针在相遇后走了S+ 然后再走lenA就能到达join点,所以把上述式子左右两边+S
S+lenA = S + nR - x = S+ (n-1) * R + R-x = S+(n-1)R + y
这里的 S + (n-1)*R 就是相遇点,所以y = lenA
两线程交替打印数字
核心设计:
-
两个线程争抢一个锁
-
拿到锁后打印数字
-
加数字
-
notifyAll
-
wait
while (i <= 100) {
System.out.println(Thread.currentThread().getName() + ":" + (i++));
notifyAll();
wait();
}
notifyAll();//这行需要加,否则永远不会停止
数据结构题
树相关
二叉树镜像:前序遍历,如果存在左右节点,就交换,然后递归左节点,最后递归遍历右节点。
前序遍历:停止条件是,当前节点为null,直接返回;先print,然后递归遍历左子树,最后递归遍历右子树
中序遍历:停止条件是,当前节点为null,直接返回;先递归遍历左子树,然后print,最后递归遍历右子树
后序遍历:停止条件是,当前节点为null,直接返回;先递归遍历左子树,然后递归遍历右子树,最后print
二叉排序树(因为有序:查找效率不错;因为非线性结构:插入和删除效率也不错)
要么是一棵空树,要么是 一棵符合下面性质的树
- 若左子树不为空,左子树所有节点值都小于根节点的值
- 若右子树不为空,右子树所有节点值都大于根节点的值
- 左子树和右子树也分别是一棵二叉排序树
查找:停止条件,一是当前节点为null,返回false;一是当前节点等于待查数据,返回true;其他情况需要进行递归左子节点或者递归右子节点来实现。
插入:先查找,如果失败,和当前节点比较,如果节点为null,待插入节点为根节点;如果小于节点值或者大于节点值,设置为节点的左孩子或者右孩子。
删除:
- 删除节点是叶子节点,直接删除即可
- 删除节点只有左子树或者右子树,直接用子树子承父业即可
- 删除节点既有左子树又有右子树,找到待删除节点的前驱节点,交换,然后删除前驱节点即可
B树
为什么需要多路查找树?
当引入硬盘的概念时,我们就更需要考虑IO操作的次数,因为IO操作是整个流程的短板操作。之前学习过的树,每个节点只能存储一个数据,在元素非常多的时候,要么度很大(子节点很多),要么高度很大,这两种方式都会导致更多的IO操作次数。
多路查找树:每个节点可以存储多个数据并且节点的孩子数可以多于两个。
B树是一种平衡的多路查找树,非叶节点至少有两个孩子,每个节点可以包括k-1个元素和k个孩子,所有叶子节点都在同一层。在具体设计的时候,可以把b树的节点大小和硬盘的页大小匹配,让一次IO操作尽可能读取更多的有序元素进行比较。
B+树
B+树的出现是为了优化B树的遍历需求(范围查找),和B树不同,
- B+树的每个叶子节点中还保存了父节点中的索引值
- B+树的每个叶子节点还有下一个叶子节点的索引
这让范围查询和遍历都变得更加方便。
排序相关
冒泡排序
原理:从后面往前,两两比较,如果较小就往上冒。
代码简述:两个循环,第一层是i=0到最后一个值,第二层是j=最后一个值,j--,直到j<i
简单选择排序
原理:每一趟在 n-i+1(i=1到n-1)个记录中,找到最小的记录,作为有序序列的第i个记录。
代码简述:两层循环,第一层i=0到最后一个值,第二层j=i+1到最后一个值,找到最小值,如果需要交换就交换
直接插入排序
原理:将一个记录插入到已经排好序的列表中
代码简述:两层循环,第一层是i=1到最后一个,第二层循环是往前找待插入位置
系统设计题
海量用户积分排名算法探讨
某海量用户网站,用户拥有积分,积分可能会在使用过程中随时更新。现在要为该网站设计一种算法,在每次用户登录时显示其当前积分排名。用户最大规模为2亿;积分为非负整数,且小于100万。
第一种方式:用一条简单的SQL语句查询出积分大于该用户积分的用户数量
优点:实现简单
缺点:全表查询,性能差
其他方式需要再研究
简单描述一下怎么实现一个rpc框架
RPC框架:客户端调用服务端方法,就像调用本地方法一样。
对客户端来说,使用某种方式获取依赖的服务接口的一个对象,然后调用需要的方法。
对服务端来说,使用某种方式,把实现了接口的对象注册到RPC框架中。
整个调用流程:
客户端获取的是服务端真实类的一个桩,这个桩是一个代理类。
桩内部的代码就是把请求的服务名和参数发送到服务端,服务端解析对应的服务名,传入参数来调用真正的方法,把方法返回值返回给桩,桩再把返回值返回给客户端。
关键设计:
- 注册中心(服务端需要把服务名和自己的地址注册到注册中心;客户端需要根据服务名从注册中心获取服务端的地址)
- 客户端需要的接口-获取一个远程服务实例
- 服务端需要的接口-注册自己的服务到框架中
**图书管理系统,每人一张卡,最多能借十本书,一本书最多能借30天,系统包括借书和还书,借书超过30天会计算罚金,罚金没还完无法继续借书。此外后面还加了一个预约功能。(基本就是从数据库表设计去回答了) **
火车票购票,分别有购票、退票、检票三个功能,一共五十张票,有文件A和文件B,文件A记录买票人信息,文件B记录检票人信息,模拟真实场景进行设计,需要考虑各种异常情况。(面试官最后说这个题有一个比较重要的考察点就是缓存和文件的读写顺序)
需求分析
功能性需求
需要讨论的点?
有文件A和文件B,文件A记录买票人信息,文件B记录检票人信息,这个是什么意思?是需要把相关信息存储到文件中?假设是确定用文件系统来保存数据,并且确定了表存储的内容,并非固定的结构
是否已经默认登陆了系统?假设为是;
是否需要做支付?假设不需要,默认用户已经支付,我们只考虑如何保存相关业务信息即可;
退票业务是否支持发车后退票?是否支持发车前N分钟内无法退票的情况?假设不支持发车后退票,并且发车前15分钟内不支持退票
- 购票业务:用户点击购票按钮,生成订单,订单中包含始发站,终到站,发车时间,车次信息
- 退票业务:用户点击退票按钮,检验是否可以正常退票,如果正常,提示用户退票成功,否则提示用户退票失败
- 检票业务:用户到检票地点进行检票,系统内部需要检查该票的状态是否可以检票,如果状态正常,更新相应信息,返回检票成功或者失败
非功能性需求
- 系统需要保证支持高并发(使用我们系统的人数可能较高)
- 系统要保持高可用(如果系统挂了,那么用户就无法购票乘车;或者人工窗口会产生大量业务)
- 尽量保证低延迟的处理每个用户的请求
相关预估
流量预估
需要询问面试官,系统的购票流量大约有多少?
分析可得知,系统的购票流量一定远大于退票流量,几乎等于检票流量
假设系统的购票流量为100张/s,退票流量按照5%的退票率,一共有50张票,那么每秒退票流量2张/s,检票流量为50张/s
带宽预估
因为流量较低,所以带宽几乎不需要进行预估
存储预估
系统中设定需要使用文件保存相关信息,因为票量较少,所以这里也不进行预估
SystemAPI设计
- orderId buyTicket(userId,TicketInfo)
- refundTicket(orderId)
- checkTicket(orderId)
数据库表设计
车站表:车站id,车站名
车辆表:车辆id,总座位数
车次表:存储车辆id,始发站车站id,发车时间
车次详情表:车次id,途径站车站id,是否为本次车次的终点站,到站时间,发车时间(如果为终点站,发车时间为null)
购票表:购票表id,用户id,车次表id,上车站id,终到站id,票数,订单状态(所有票都是 已检票 或者 退票 才为已结束,其他状态进行中)
购票详情表:购票id,座位号,状态(未检票,已检票,退票)
注意:任意分段余票的算法,可以通过
T(i,j) = 车辆总座位数 - (Si ∪ S(i+1) ∪ … ∪ S(j -1)) (Si为i站到i+1站的占用座位数)
详细资料:火车票余票问题的算法解析
关键业务流程设计
购票是所有业务的起点业务,购票时最核心的操作是要校验所选分段是否有余票,如果有,创建座位占用表相关数据,余票算法可以通过上面的算法公式计算得到,最后创建购票表
校验是否有余票的业务需要加同步锁,具体设计可以参考这里:浅谈库存扣减和锁
退票业务
待完成