本期将介绍并演示PaddleOCR+Python+OpenCV实现车牌识别、身份证信息识别和车票信息识别的步骤与效果。
介绍
百度深度学习框架PaddlePaddle开源的OCR项目PaddleOCR近期霸榜github。使用测试后发现识别效果很好,对于简单的应用(车票车牌身份证等),直接用项目提供的模型即可使用。特殊应用,可自己训练后使用。
gituhub地址:https://github.com/PaddlePaddle/PaddleOCR
效果展示
分别以车牌识别、身份证信息识别和车票信息识别为例,测试效果如下视频:

实现步骤
PaddleOCR是基于百度的深度学习框架PaddlePaddle实现的,所以第一步我们需要先安装PaddlePaddle模块。直接使用pip安装即可:
——指令:pip install paddlepaddle
第二步:安装PaddleOCR。同样是pip安装:
——GPU版安装:
python -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple——CPU版安装:
python -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple如果要在GPU模式下使用除了有GPU外还需要安装CUDA 10.1和CUDNN对应文件,另外遇到的安装问题网上也可以找到答案,我的安装步骤到此结束。
代码演示
代码演示前需要先下载PaddleOCR提供的训练好的模型共3个,我是Win10 PC端使用下载下面三个,如果是移动端下载上面三个。

github提供的Demo如下将会保存一张识别结果图:
from paddleocr import PaddleOCR
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from paddleocr import PaddleOCR, draw_ocr
font=cv2.FONT_HERSHEY_SIMPLEX
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch",use_gpu=False,
rec_model_dir='./models/ch_ppocr_server_v2.0_rec_infer/',
cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer/',
det_model_dir='./models/ch_ppocr_server_v2.0_det_infer/') # need to run only once to download and load model into memory
img_path = './imgs/B.jpg'
result = ocr.ocr(img_path, cls=True)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.png')
识别输出信息:

输出结果图:

我们把输出结果部分改成OpenCV实现:
from paddleocr import PaddleOCR
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
font=cv2.FONT_HERSHEY_SIMPLEX
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch",use_gpu=False,
rec_model_dir='./models/ch_ppocr_server_v2.0_rec_infer/',
cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer/',
det_model_dir='./models/ch_ppocr_server_v2.0_det_infer/') # need to run only once to download and load model into memory
def putText_Chinese(img,strText,pos,color,fontSize):
fontpath = "./simsun.ttc" # <== 这里是宋体路径
font = ImageFont.truetype(fontpath, fontSize)
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
draw.text(pos,strText, font=font, fill=color)
img = np.array(img_pil)
return img
print('---------------PaddleOCR Start---------------------')
img_path = './pics/18.jpg'
img = cv2.imread(img_path)
cv2.imshow("src", img)
result = ocr.ocr(img_path, cls=True)
#print(result)
for line in result:
print('----------------------------')
print(line)
pt1 = ((int)(line[0][0][0]),(int)(line[0][0][1]))
pt2 = ((int)(line[0][1][0]),(int)(line[0][1][1]))
pt3 = ((int)(line[0][2][0]),(int)(line[0][2][1]))
pt4 = ((int)(line[0][3][0]),(int)(line[0][3][1]))
cv2.line(img,pt1,pt2,(0,0,255),1,cv2.LINE_AA)
cv2.line(img,pt2,pt3,(0,0,255),1,cv2.LINE_AA)
cv2.line(img,pt3,pt4,(0,0,255),1,cv2.LINE_AA)
cv2.line(img,pt1,pt4,(0,0,255),1,cv2.LINE_AA)
img = putText_Chinese(img,line[1][0],(pt1[0],pt1[1]-35),(255,0,255),50)
cv2.imshow("OCR-Result", img)
cv2.imwrite("result.png", img)
cv2.waitKey()
cv2.destroyAllWindows()
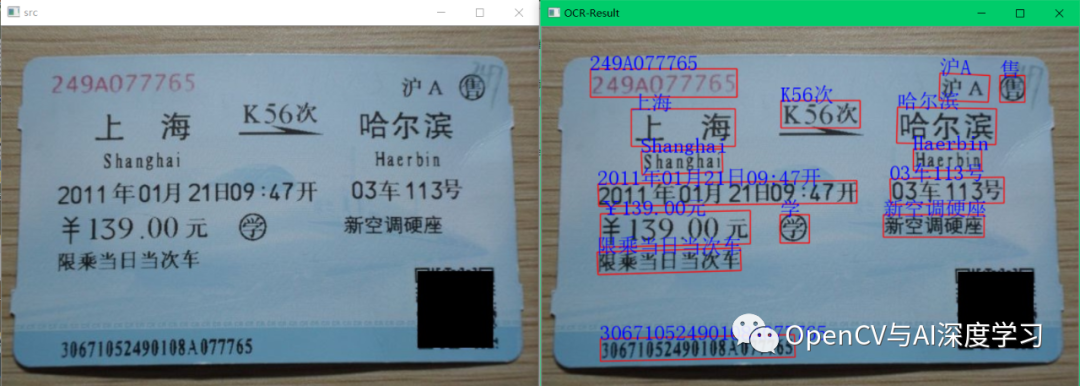
输出结果图:

倾斜也可以自动识别:

车票识别: