集合(Collection)
Collection和Collections有什么区别
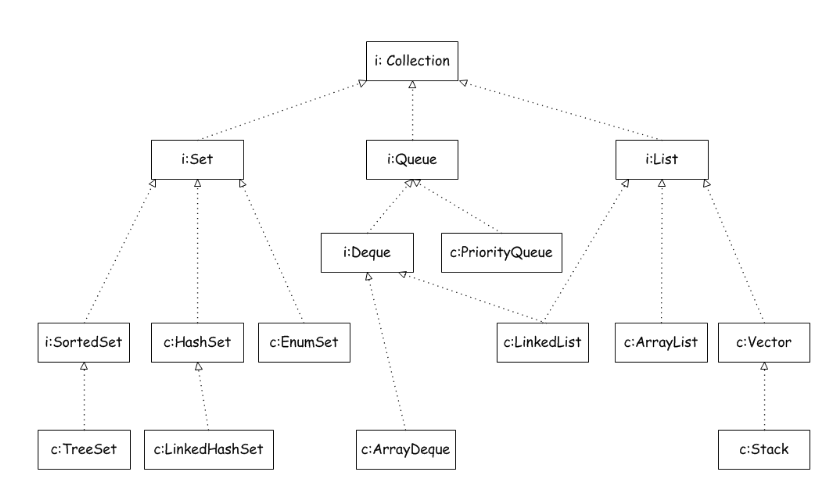
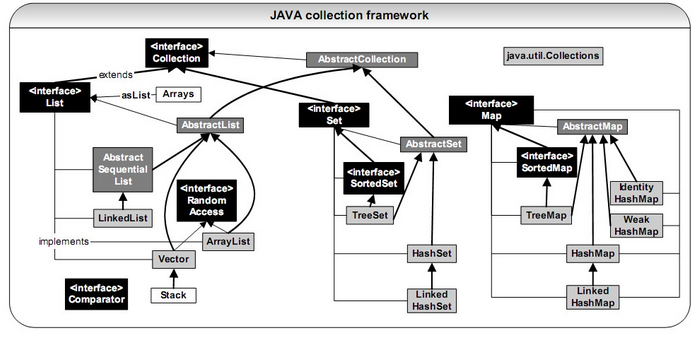
Collection是一个集合接口。提供了对集合对象进行基本操作的通用接口方法,实现接口的类主要是List和Set。
Collections是针对集合类的一个包装类,提供一系列静态方法以实现对各种集合的搜索、排序、线程安全化等操作,大多用来处理线性表。
集合中线程安全的类有:vector、stack、hashtable、enumeration。除此之外,均是非线程安全的类和接口。
collection、set、List都是接口,HashSet继承AbstractSet,实现了Set接口。
ArrayList、LinkedList和Vector
List接口有三个实现类,分别是ArrayList、LinkedList和Vector
|
|
ArrayList |
Vector |
LinkedList |
|
内存结构 |
数组 |
数组 |
双向链表 |
|
数组内存扩展 |
原数组*1.5+1 有利于节约内存空间 |
原数组*2 |
|
|
插入删除 |
效率低 |
效率低 |
效率高 |
|
随机访问 |
效率高 |
效率高 |
效率低 |
|
线程安全? |
不安全,不同步 |
安全,同步 |
不安全,不同步 |
|
空间浪费 |
List列表的结尾预留一定的空间 |
|
每一个元素都需要消耗相当的空间 |
|
备注 |
|
提供indexOf(obj, start)接口 |
提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。 |
ArrayList本质是顺序存储的线性表,插入和删除操作会引发后续元素移动,效率低,随机访问效率高。ArrayList删除元素后,剩余元素会依次向前移动,因此下标一直在变,size()也会减小。remove(int index)删除索引处元素,remove(Object o)删除元素。
Vector和ArrayList一样,也是通过数组实现,不同的是它支持线程的同步,但实现同步需要很高的花费,因此访问它比访问ArrayList慢。
LinkedList的内存是双向链表储存,链式存储结构插入和删除效率高,不需要移动。但是随机访问的效率低,需要从头开始向后依次访问。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
手动实现ArrayList
public class MyArrayList {
//定义存放数据的数组
private Object[] elementData;
private int size;
//获得集合长度的方法
public int size(){
return elementData.length;
}
//默认初始数组长度为10
public MyArrayList() {
this(10);
}
public MyArrayList(int initialCapacity) {
if (initialCapacity < 0) {
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
elementData = new Object[initialCapacity];
}
//add方法
public void add (Object o){
//数组扩容和数据拷贝
if (size == elementData.length ) {
Object[] newArray = new Object[size*2+1];
System.arraycopy(elementData, 0, newArray, 0, elementData.length);
elementData = newArray;
}
elementData[size++] = o;
}
//是否为空
public boolean isEmpty(){
return size == 0;
}
//get方法
public Object get(int index){
if (index < 0 || index >=size) {
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
return elementData[index];
}
public static void main(String[] args) {
MyArrayList m2 = new MyArrayList(3);
m2.add("111");
m2.add("222");
m2.add("333");
m2.add("444");
m2.add("555");
System.out.println(m2.get(2));
}
}
HashMap和Hashtable的区别
(1)Hashtable的方法是线程同步的,HashMap未经同步
(2)Hashtable不允许null值(key和value都不可以),HashMap允许null值(key和value都可以)。HashMap插入的时候,检查是否已经存在相同的key,如果不存在,则直接插入,如果存在,则用新的value替换旧的value。
(3)Hashtable使用Enumeration,HashMap使用Iterator
(4)Hashtable有一个contains(Object value),功能和containsValue(Objectvalue)功能一样;
(5)哈希值的使用不同,Hashtable直接使用对象的hashCode,而HashMap重新计算hash值。
(6)Hashtable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
(7)HashMap底层是由数组加链表实现的,对于每一个key值,都需要计算哈希值,然后通过哈希值来确定顺序,并不是按照加入顺序来存储,是无序的。
Set中存放元素根据什么来判断相同
HashSet中的add()方法,底层是靠HashMap来实现。HashMap中存入元素的时候,首先比较hashCode值,若不相等,则存入,若相同再比用equals()比较。所以HashSet是避免重复是根据hashCode和equals保证的。
Set不能有重复元素,且是无序的,要有空值也只能有一个。
List可以有重复元素,是有序的,空值也可以是多个。
遍历集合(Iterator)
通用遍历方式
所有集合都实现Iterator接口,用来遍历集合中的元素。
接口中的方法如下:
boolean hasNext() 如果仍有元素可以迭代,则返回 true。
Object next() 返回迭代的下一个元素。
void remove() 从迭代器指向的 collection 中移除迭代器返回的最后一个元素。
用法
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
Iterator<Object> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
另一种写法
for (Iterator it = list.iterator(); it.hasNext();) {
System.out.println(it.next());
}
Map遍历方式
1、通过获取所有的key,按照来遍历
Set<String> set = map.keySet(); //得到所有key的集合
for (String str : map.keySet()) {
Object obj = map.get(str);//得到每个key多对用value的值
}
2、通过Map.entrySet使用iterator遍历key和value
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
3、通过Map.entrySet遍历key和value,推荐,尤其是容量大时
//Map.entry<Integer,String> 映射项(键-值对) 有几个方法:用上面的名字entry
//entry.getKey() ;entry.getValue(); entry.setValue();
//map.entrySet() 返回此映射中包含的映射关系的 Set视图。
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
List遍历方式
1、使用Iterator
2、foreach循环
for (Object object : list) {
System.out.println(object);
}
3、for循环
for(int i = 0 ;i<list.size();i++) {
int j= (Integer) list.get(i);
System.out.println(j);
}
每个遍历方法的实现原理是什么?
各遍历方式对于不同的存储方式,性能如何?
各遍历方式的适用于什么场合?
Java的最佳实践是什么?
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
LinkList部分源码
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
if (list instanceof RandomAccess) {
//使用传统的for循环遍历。
} else {
//使用Iterator或者foreach。
}
参考博客
[1]java集合遍历的几种方式总结及比较
http://www.cnblogs.com/leskang/p/6031282.html