0 引言
cuda线程模型涉及grid的块划分和线程配置,直接影响到全局运算速度。根据文档《CUDA_C_Programming_Guide》,性能优化有三个方面的基本策略。
(1)最大化并行执行以实现最大的利用率.
(2)优化内存使用,以实现最大的内存吞吐量.
(3)优化指令使用,以实现最大的指令吞吐量.
对于应用程序的特定部分,哪些策略将产生最佳性能收益取决于该部分的性能受哪方面的限制;例如,优化主要受内存访问限制的内核的指令使用不会产生任何显著的性能提升。因此,应该不断地通过测量和监视性能限制器(例如使用CUDA profiler)来指导优化工作。此外,将特定内核的浮点操作吞吐量或内存吞吐量(无论哪个更有意义)与设备的相应峰值理论吞吐量进行比较,可以看出内核有多大的改进空间。
1 定位问题
(1)发现采用两组数据进行训练时,速度存在比较大的差异。其中,数据1耗时 time1 = 68163 ms, 数据2耗时 time2 = 42930 ms. time1 = 1.59 * time2
通过cuda函数 gettimeofday 发现数据2关键函数的时间分布如下。
time of pre-ComputeTDF is 106063 mms
time of ComputeTDF is 96 mms
time of post-ComputeTDF is 157454 mms
time of pre-ComputeTDF is 11495 mms
time of ComputeTDF is 108 mms
time of post-ComputeTDF is 149239 mms
time of pre-ComputeTDF is 8958 mms
time of ComputeTDF is 95 mms
time of post-ComputeTDF is 133390 mms
其中, pre-ComputeTDF包含数据的预处理和内存分配与拷贝操作,ComputeTDF调用核函数计算TDF值,post-ComputeTDF计算local-TDF以及将gpu中的数据拷贝回cpu. 从时间上来看,CUDA部分的操作并非计算性能不佳的瓶颈,其瓶颈集中在pre-post-ComputeTDF上。
(2)分别考察pre-post-ComputeTDF中进行数据预处理和内存分配与拷贝的时间,结果如下。
数据2数据处理部分的耗时记录:
time of pre-ComputeTDF without memory copy is 1542 mms
time of post-ComputeTDF without memory copy is 1003 mms
time of pre-ComputeTDF without memory copy is 2182 mms
time of post-ComputeTDF without memory copy is 924 mms
time of pre-ComputeTDF without memory copy is 2066 mms
time of post-ComputeTDF without memory copy is 928 mms
sum_time_of_data_dealing = 8645mms
数据2内存分配与拷贝部分的耗时记录(例二):
time of memory copy of pre-ComputeTDF is 93738 mms
time of memory copy of post-ComputeTDF is 155900 mms
time of memory copy of pre-ComputeTDF is 6428 mms
time of memory copy of post-ComputeTDF is 140536 mms
time of memory copy of pre-ComputeTDF is 7184 mms
time of memory copy of post-ComputeTDF is 135659 mms
sum_time_of_memory_copy_2 = 539445mms = 62.4 * sum_time_of_data_dealing
可以确定时间主要消耗在了内存分配与拷贝部分上!时间差距应当出现在这一部分,计算数据1进行验证
time of memory copy of pre-ComputeTDF is 100188 mms
time of memory copy of post-ComputeTDF is 244773 mms
time of memory copy of pre-ComputeTDF is 6431 mms
time of memory copy of post-ComputeTDF is 205273 mms
time of memory copy of pre-ComputeTDF is 6668 mms
time of memory copy of post-ComputeTDF is 203422 mms
sum_time_of_memory_copy_1 = 766755mms = 1.42 * sum_time_of_memory_copy_2,与1.59的差距大致相当。
(3)更进一步,分析time of memory copy of pre-ComputeTDF 与 time of memory copy of post-ComputeTDF的区别
sum_data1_pre = 1813.6950 ms
sum_data2_pre = 1863.4580 ms
sum_data1_post = 38564.5090 ms
sum_data2_post = 49542.4860 ms
difference_sum_data_post = 10978 ms
(4)寻找其他方面的差距
统计了 time_use_without_computing_tdf1 = 11245.0 ms, time_use_without_computing_tdf2 = 1727.0 ms
difference_time_use_without_computing_tdf = 9518 ms
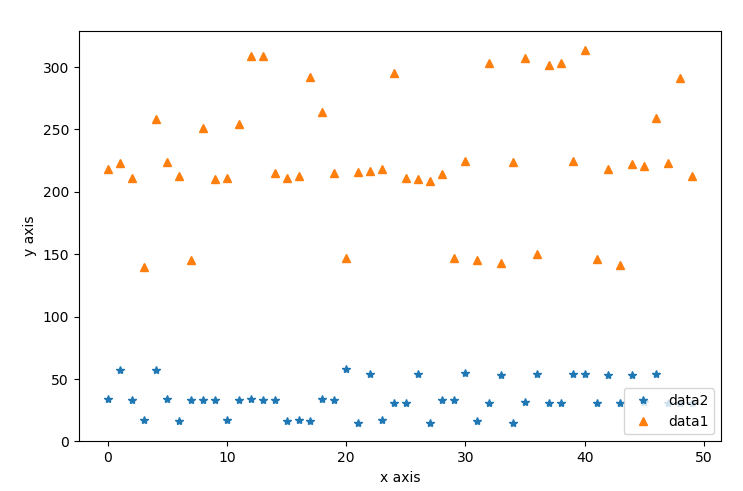
以上两部分 difference_sum_data_post + difference_time_use_without_computing_tdf = 20496 ms为两组数据在性能上的主要差异,分析原因在于点云规模不同,数据1点云的平均规模在7万级别,数据2点云的规模在1万级别,因此二者的表现差异比较大。
2 解决问题
通过降采样点云可以提高运算效率。