排序

(注意:n指数据规模;k指“桶”的个数;In-place指占用常数内存,不占用额外内存;Out-place指占用额外内存)
一、排序
将一组杂乱无章的数据按一定的规律次序排列起来。
排序的目的是什么?
便于查找!
排序算法的好坏如何衡量?
时间效率——排序速度(即排序所花费的全部比较次数)
空间效率——占内存辅助空间的大小
稳定性——若两个记录A和B的关键字值相等,但排序后A、B 的先后次序保持不变,则称这种排序算法是稳定的。
排序前 ( 56, 34, 47, 23, 66, 18, 82, 47 )
若排序后得到结果 ( 18, 23, 34, 47,47, 56, 66, 82 )
则称该排序方法是稳定的
若排序后得到结果 ( 18, 23, 34, 47, 47, 56, 66, 82 )
则称该排序方法是不稳定的
● 内部排序:指待排序记录全部存放在内存中排序的过程。
● 外部排序:指待排序记录的数量很大,以至内存不能容纳全 部记录,在排序过程中尚需对外存进行访问的过程。

二、插入排序
每步将一个待排序的对象,按其关键码大小,插入到前面已 经排好序的一组对象的适当位置上,直到对象全部插入为止。
插入排序有多种具体实现算法:
- 直接插入排序
- 希尔排序
(1)直接插入排序
每一趟将一个待排序的记录,按照其关键字的大小插入到有序队列的合适位置里,直到全部插入完成,比如斗地主抽牌就是这样的规则。
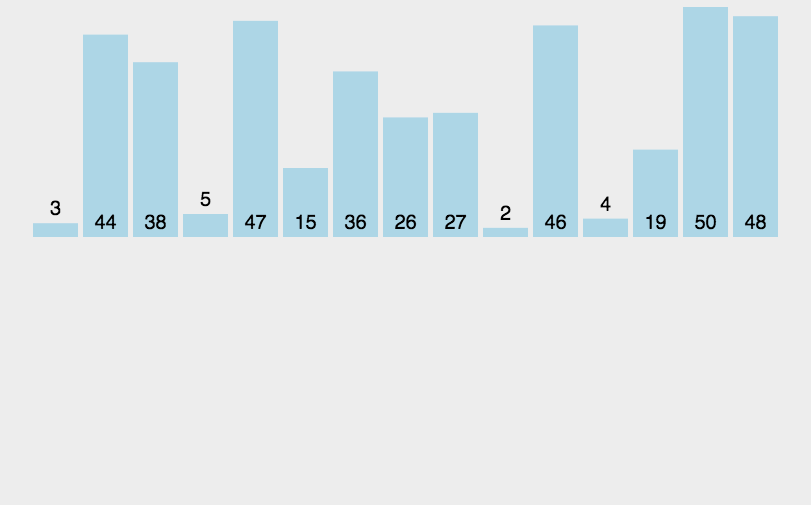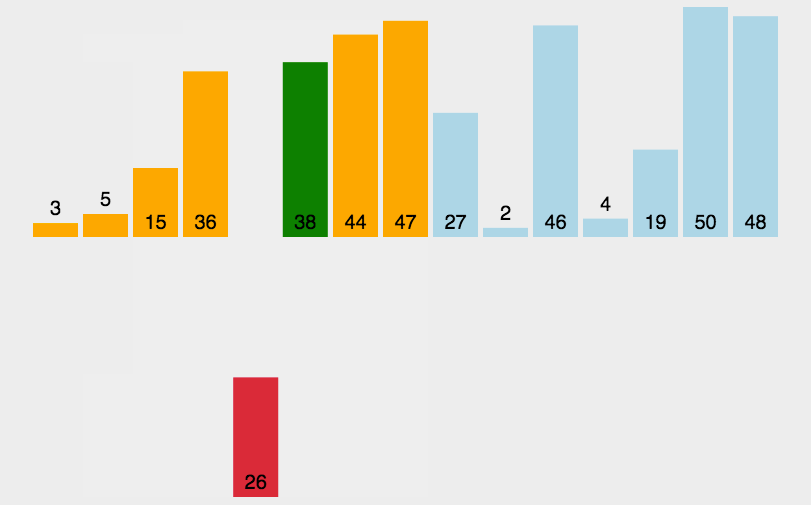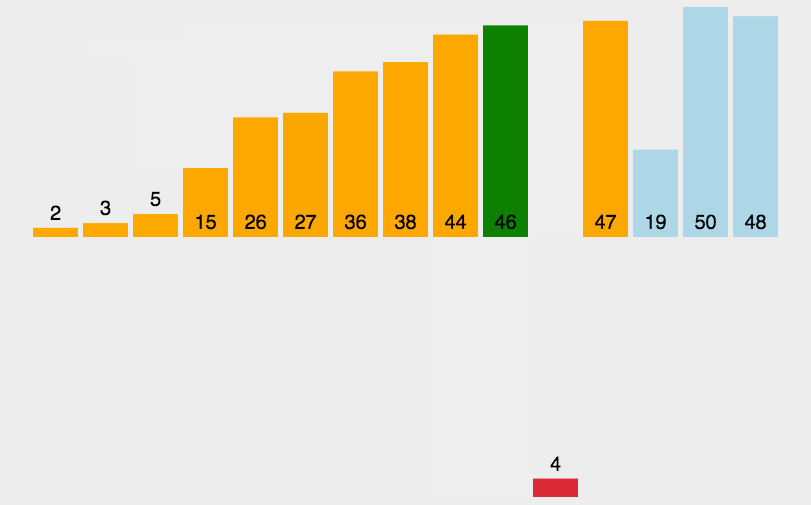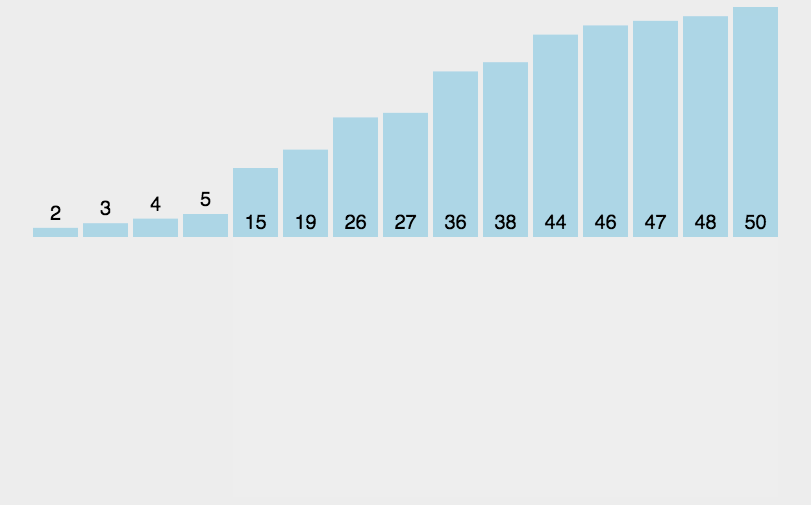
时间效率: 因为在最坏情况下,所有元素的比较次数总和 为(0+1+…+n-1)→O(n2)。故时间复杂度为O(n2)
空间效率:仅占用1个缓冲单元—O(1)
算法的稳定性:稳定
(2)希尔排序
先取一个正整数d1<n,把所有相隔d1的记录放一组,组内进行直接插入排序;然后取d2<d1,重复上述分组和排序操作;直至di=1, 即所有记录放进一个组中排序为止。
一般取d1=n/2, di+1=di/2,如果结果为偶数,则加1。

希尔排序是一种不稳定的排序方法
初始序列的不同会影响算法的效率
三、选择排序
每一次从待排序的数据元素中选出最小的一个元素,存放在 已排序列的后面,直到全部待排序的数据元素排完。
优点:实现简单
缺点:每趟只能确定一个元素,表长为n时需要n-1趟
前提:顺序存储结构
选择排序分为 (1)直接选择排序 (2)堆排序
(1)直接选择排序
在所有记录中选出最小的记录,把它与第1个记录交换,然后 在剩余的记录内选出最小的记录与第2个交换…依次类推。
(2)堆排序
堆是满足下列性质的数列{r1, r2, …,rn}
 堆排序即是利用堆的特性对记录序列进行排序的一种排序 方法。
堆排序即是利用堆的特性对记录序列进行排序的一种排序 方法。
将无序序列建成一个堆,得到关键字最小(或最大)的记 录;输出堆顶的最小(大)值后,使剩余的n-1个元素又建 成一个堆,则可得到n个元素的次小值;重复执行,得到一 个有序序列,这个过程叫堆排序。
输出堆顶元素之后,以堆中最后一个元素替代之;然后将 根结点值与左、右子树的根结点值进行比较,并与其中小 者进行交换;重复上述操作,直至叶子结点,将得到新的 堆,称这个从堆顶至叶子的调整过程为“筛选”。


堆排序的最坏时间复杂度为O(nlog2n),堆排序的平均性能接 近最坏性能。
堆排序的辅助空间为O(1)。
四、交换排序
交换排序的基本思想是两两比较待排序记录的关键码,如果 发生逆序(排列顺序与排序后的次序相反),则交换之,直 到所有记录都排好序为止。
交换排序的主要算法有:
- 冒泡排序
- 快速排序
(1) 冒泡排序
基本思路:每趟不断将记录两两比较,并按“前小后大”(或 “前大后小”)规则交换。
第一趟:第1个与第2个比较,大则交换;第2个与第3个比较, 大则交换,……关键字最大的记录交换到最后一个位置上;
第二趟:对前n-1个记录进行同样的操作,关键字次大的记 录交换到第n-1个位置上;
依次类推,则完成排序
 最好情况:初始排列已经有序,只执行一趟起泡,做 n-1 次 关键码比较,不移动对象。 最坏情形:初始排列逆序,要执行n-1趟起泡。
最好情况:初始排列已经有序,只执行一趟起泡,做 n-1 次 关键码比较,不移动对象。 最坏情形:初始排列逆序,要执行n-1趟起泡。
时间效率:O(n2) 因为要考虑最坏情况;
空间效率:O(1) 只在交换时用到一个缓冲单元
稳定性: 稳定,因为25和25*在排序前后的次序未改变
(2) 快速排序
从待排序列中任取一个元素 (例如取第一个) 作为中心,所有 比它小(或相等)的元素一律放前,所有比它大的元素一律 放后,形成左右两个子表;
然后再对各子表重新选择中心元素并按此规则调整,直到每 个子表的元素只剩一个。此时便为有序序列了。
优点:因为每趟可以确定不止一个元素的位置,而且呈指 数增加,所以特别快!
前提:顺序存储结构
 若待排记录的初始状态为按关键字有序时,快速排序将蜕化为冒泡排序,最坏时间复杂度为O(n2),最好时间复杂度为 O(nlog2n)
若待排记录的初始状态为按关键字有序时,快速排序将蜕化为冒泡排序,最坏时间复杂度为O(n2),最好时间复杂度为 O(nlog2n)
快速排序是一种不稳定的排序方法
五、归并排序
可以把一个长度为n 的无序序列看成是 n 个长度为 1 的有序子序列 ,首先做两两归并,得到 n / 2 个长度为 2 的有序子序列 ; 再做两两归并,…,如此重复,直到最后得到一个长度为 n 的 有序序列。

归并排序
时间效率: O(nlog2n)
空间效率: O(n)
稳定性:稳定
六、基数排序
基数排序与本系列前面讲解的七种排序方法都不同,它不需要比较关键字的大小。它是根据关键字中各位的值,通过对排序的N个元素进行若干趟“分配”与“收集”来实现排序的。
算法描述
取得数组中的最大数,并取得位数;
arr为原始数组,从最低位开始取每个位组成radix数组;
对radix进行计数排序(利用计数排序适用于小范围数的特点);

算法分析
最佳情况:T(n) = O(n * k) 最差情况:T(n) = O(n * k) 平均情况:T(n) = O(n * k)。基数排序有两种方法:MSD 从高位开始进行排序 LSD 从低位开始进行排序 。基数排序 vs 计数排序 vs 桶排序。这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
基数排序:根据键值的每位数字来分配桶
计数排序:每个桶只存储单一键值
桶排序:每个桶存储一定范围的数值
引用博文:https://blog.csdn.net/u012562943/article/details/100136531