在上一篇博客中我们讨论了车间调度问题的编码问题,具体说就是根据工件的个数和每个工件的工序数来生成01011这样的编码列表来表示可行解,具体的说一个工件包含多少道工序,那么这个工件的编号就出现多少次。从0101中我们可以看出总共有两个工件0和1,工件0下面有2道工序,工件1下面有2道工序,所以编码值0出现了2次,编码值1出现了2次。
如果想采用暴力法或随机搜索法,我们不能只生成一个可行解的编码列表,我们需要生成一组可行解的编码列表,再从这组可行解中挑选最优的。这组可行解的编码列表组成的集合叫作种群。大家思考一下如何编程实现种群的生成,大家看一下下面的python代码:
2 gene = [j for j in range(n) for t in I[j]] 3 population = [] 4 for i in range(ps): 5 random.shuffle(gene) 6 population.append([j for j in gene]) 7 return population
第1行: 我们定义了一个生成初始种群的函数,叫作InitPopulation,这个函数接收两个参数,ps 和 I。ps是个整型变量,它的值表示种群里可行解的个数,I是个list, 里面存放的是每个工件下每道工序使用的机器号和在该机器上加工的时间(即下面这个已知条件表格)。我们还是用上一篇博客的那两个工件,两台机器的已知条件表格来说明

在调用InitPopulation这个函数之前我们需要先定义好ps和I:
ps=10 //代表种群里有10个可行解
I=[[(1,3),(2,2)],[(2,5),(1,1)]]。
I 是一个list, 下面又分别有两个子list, 每个子list代表一个工件的信息,它们是I[0]=[(1,3),(2,2)] 和I[1]=[(2,5),(1,1)],子list里每个有序偶代表该工件下的各个工序信息。
n 表示工件的个数,这里 n=2。
m 表示机器的个数,这里 m=2。
第2行 gene是固定死的0011,即按工件号由小到大排列,每个工件号出现的次数与这个工件包含的工序数(子list的个数)相同。
第3行 定义一个空list命名为population用来存放10个可行解。
第 4,5,6 行 for循环,生成ps=10个染色体,存放在population中,最后返回population。具体做法是利用python的shuffle洗牌函数来随机打乱gene(即固定的0011)的顺序来生成新编码列表(第5行),Example:第一次shuffle(0011)洗牌后的结果可能是0101,第二次的结果是shuffle(0011)洗牌后的结果可能是1100,这样经过ps次shuffle操作就可以生成ps=10个编码列表存到population中(第6行)。
有了已知条件表格I,又有了每个可行解的编码列表s(如0011,0101等),我们可以为每个可行解构造出其对应的有向无环图G(解码环节)。代码如下:
1 def ComputeDAG(s, I): 4 G = [] 5 for t in s: G.append([]) 6 G.append([]) 7 T = [0 for j in range(n)] 8 last_task_job = [-1 for j in range(n)] 9 tasks_resource = [[-1 for j in range(n)] for m in range(m)] 10 st = [] # Returns for each task, its id within a job 11 for i in range(len(s)): 12 j = s[i] 13 t = T[j] 14 st.append(t) 15 r = I[j][t][0] 16 # If this is the final task of a job, add edge to the final node 17 if t + 1 == len(I[j]): G[-1].append(i) 18 # Wait for the previous task of the job 19 if t > 0: G[i].append(last_task_job[j]) 20 # Wait for the last task from other jobs using the same resource 21 G[i].extend([tasks_resource[r][j2] for j2 in xrange(I.n) 22 if j2 != j and tasks_resource[r][j2] > -1]) 23 T[j] = T[j] + 1 24 last_task_job[j] = i 25 tasks_resource[r][j] = i 26 return G, st
对上面代码的解释如下:
def ComputeDAG(s, I): """s是编码信息列表如0011,0101等,I存储已知条件表的信息""" G = [] """构造一个空list来存储图G,如下图所示""" for t in s: G.append([])"""每个工件的每道工序在G中都用一个节点表示,即每个节点也都是一个子list,存放其前驱节点在编码列表s中的下标""" G.append([])"""添加结束节点(无需添加开始节点),如下图所示""" T = [0 for j in range(n)]"""初始化一个长度为工件个数n的全0列表""" last_task_job = [-1 for j in range(n)]"""last_task_job记录每个工件自己最近加入G的工序在s中所对应的下标,初始化均为-1 """" tasks_resource = [[-1 for j in range(n)] for m in range(m)]"""见后面正文部分""" st = [] "记录s里每个下标(即G的节点)在其自身工件内的相对顺序,如:0,1,2,3..." for i in range(len(s)):""" 依次处理编码列表s的每个下标,s的下标与G的节点一一对应,相当于依次处理G的节点""" j = s[i]"""提取下标为i的节点对应的编码值,编码值就是该工序所属的工件号""" t = T[j]"""T[j]是个计数器 ,它记录下标为i的节点是其自身工件j的第几道工序(即内部相对顺序),如0,1,2,3,4...""" st.append(t)""" 将t存入st,st的解释见返回值部分""" r = I[j][t][0]""" 将下标为i的节点所使用的机器号存入r中,PS:机器号是I有序偶中的第一个数字(参见上文I的定义(已标红))""" # 判断i在其工件j的内部相对顺序号是否等于j的工序总数,若相等,则说明是j的最后一道工序,应该作为结束节点的前驱(对应下图黑色箭头) if t + 1 == len(I[j]): G[-1].append(i) # 若i不是其所属工件j的第一道工序,则工件j最近加入G的那个工序节点应该作为i的前驱(对应下图蓝色箭头) if t > 0: G[i].append(last_task_job[j]) # 如果之前加入G中的其他别的工件的节点也在使用和当前处理的节点i相同的机器,则它们都应该作为i的前驱(对应下面红色箭头) G[i].extend([tasks_resource[r][j2] for j2 in xrange(I.n) if j2 != j and tasks_resource[r][j2] > -1]) T[j] = T[j] + 1"""j工件的内部工序相对顺序计数器加1""" last_task_job[j] = i"""更新last_task_job[j],定义见上面""" tasks_resource[r][j] = i""" 更新tasks_resource, 定义见下面正文(已标红)""" return G, st""" 返回图G, st记录每个节点(即编码列表的下标)对应的工序在其自身工件内的相对顺序,如:0,1,2,3,4...(从0开始算)"""
特别说明一下:task_resource这个list, 以上面的已知条件表格为例,它的初始化形式是:
task_resource=[[-1,-1],[-1, -1]]
因为有两台机器, m=2,所以task_resource里面有两个子list分别对应这两个机器, 又因为有两个工件,n=2,所以每个子list里面各有两个数字分别对应这2个工件,都先初始化为-1, 以后每个数字代表相应工件最近一次使用这台机器的工序在s中的下标值。
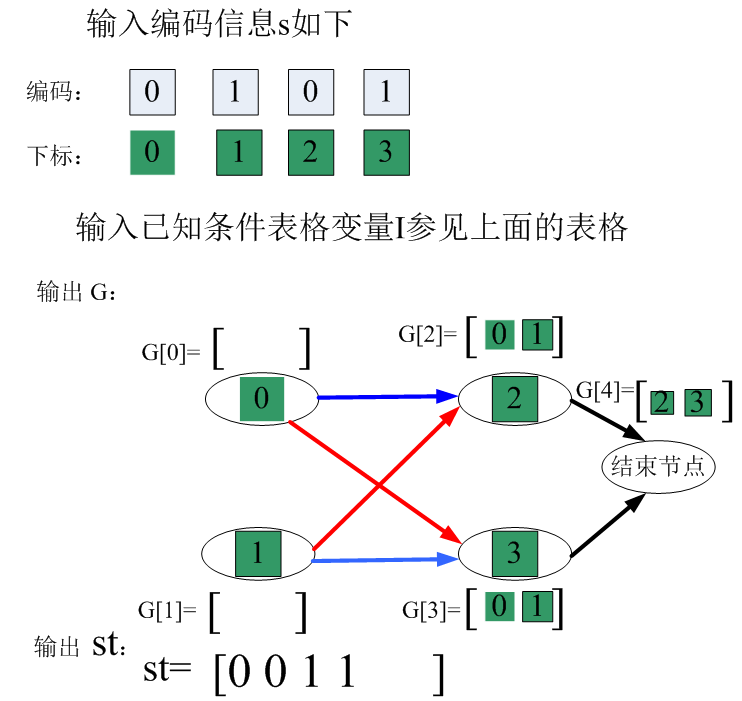
上面的程序输入为s和 I, 输出为有向图G和列表st,G中节点的个数为所有工序的总数(包括工件1的和工件2的)+1(结束节点),注意:G存放的是下标不是编码值:
G=[ [ ],[ ],[0,1],[0,1], [2,3] ]
利用可行解的编码列表重构出可行解对应的有向无环图后,我们可以利用关键路径法在图G上计算出这个可行解的总完成时间,具体流程参见上一篇博客。代码如下:
1 def ComputeStartTimes(s, I): 2 """This computes the start time of each task encoded in a chromosome of 3 the genetic algorithm. The last element of the output list is the 4 timespan.""" 5 G, st = ComputeDAG(s, I) 6 C = [0 for t in G] 7 for i in range(len(G)): 8 if len(G[i]) == 0: C[i] = 0 9 else: C[i] = max(C[k] + I[s[k]][st[k]][1] for k in G[i]) 10 return C
对代码的解释如下:
def ComputeStartTimes(s, I): """该函数返回一个一维列表C,列表C里各个值对应编码列表s中每道工序(对应G中的节点)的开工时间,C列表最后一个值(对应结束节点)存放可行解的总完成时间""" G, st = ComputeDAG(s, I)"""调用上面的构图函数创建有向无环图""" C = [0 for t in G]"C列表初始化为全0" for i in range(len(G)):"""遍历G中每一个节点""" if len(G[i]) == 0: C[i] = 0""" 如果节点i没有前驱,则i的开始时间为0,代表无需等待立即开始""" """否则,节点i的开始时间等于所有其前驱节点的开始时间+前驱节点自己的处理时间中和最大的那个值""" else: C[i] = max(C[k] + I[s[k]][st[k]][1] for k in G[i]) return C"""返回每个节点的开始时间"""
以编码0101为例,C=[0,0,5,5,7 ] 表示工件1的工序1的开始时间是0,工件2的工序1的开始时间是0,工件1的工序2的开始时间是5,工件2的工序2的开始时间是5,总完成时间是7。