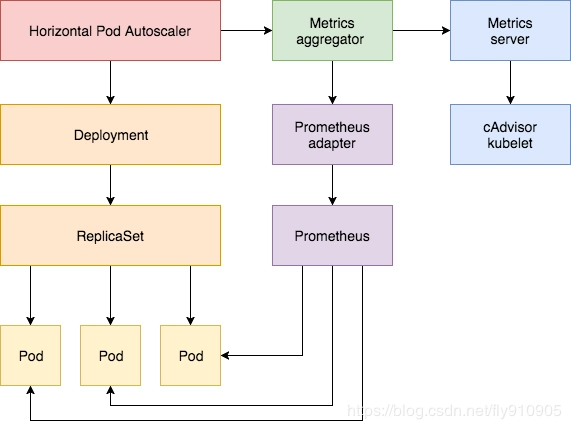
HPA控制器介绍
当系统资源过高的时候,我们可以使用如下命令来实现 Pod 的扩缩容功能
$ kubectl -n luffy scale deployment myblog --replicas=2
但是这个过程是手动操作的。在实际项目中,我们需要做到是的是一个自动化感知并自动扩容的操作。Kubernetes 也为提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA
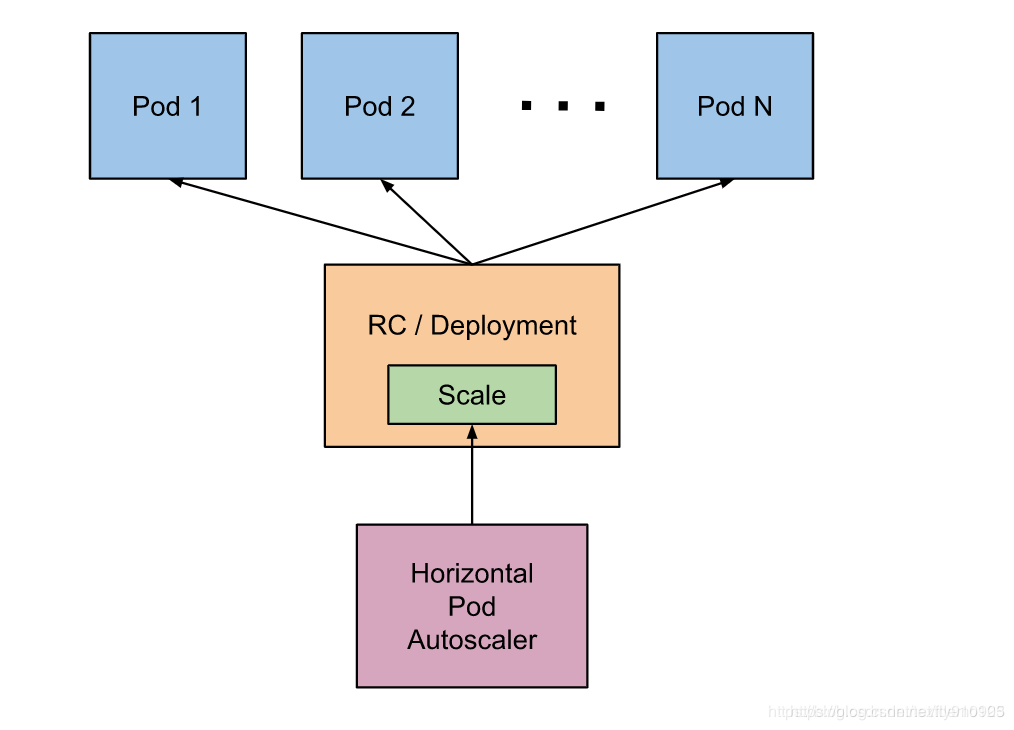
基本原理:HPA 通过监控分析控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量
HPA的实现有两个版本:
- autoscaling/v1,只包含了根据CPU指标的检测,稳定版本
- autoscaling/v2beta1,支持根据memory或者用户自定义指标进行伸缩
如何获取Pod的监控数据?
- k8s 1.8以下:使用heapster,1.11版本完全废弃
- k8s 1.8以上:使用metric-server
思考:为什么之前用 heapster ,现在废弃了项目,改用 metric-server ?
heapster时代,apiserver 会直接将metric请求通过apiserver proxy 的方式转发给集群内的 hepaster 服务,采用这种 proxy 方式是有问题的:
-
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/service_name[:port_name]/proxy -
proxy只是代理请求,一般用于问题排查,不够稳定,且版本不可控
-
heapster的接口不能像apiserver一样有完整的鉴权以及client集成
-
pod 的监控数据是核心指标(HPA调度),应该和 pod 本身拥有同等地位,即 metric应该作为一种资源存在,如metrics.k8s.io 的形式,称之为 Metric Api
于是官方从 1.8 版本开始逐步废弃 heapster,并提出了上边 Metric api 的概念,而 metrics-server 就是这种概念下官方的一种实现,用于从 kubelet获取指标,替换掉之前的 heapster。
Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,比如获取某一Pod的监控数据:
https://192.168.136.10:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
# https://192.168.136.10:6443/api/v1/namespaces/luffy/pods?limit=500
目前的采集流程:
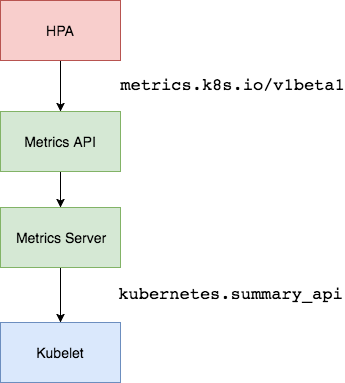
Metric Server
...
Metric server collects metrics from the Summary API, exposed by Kubelet on each node.
Metrics Server registered in the main API server through Kubernetes aggregator, which was introduced in Kubernetes 1.7
...
安装
官方代码仓库地址:https://github.com/kubernetes-sigs/metrics-server
Depending on your cluster setup, you may also need to change flags passed to the Metrics Server container. Most useful flags:
--kubelet-preferred-address-types- The priority of node address types used when determining an address for connecting to a particular node (default [Hostname,InternalDNS,InternalIP,ExternalDNS,ExternalIP])--kubelet-insecure-tls- Do not verify the CA of serving certificates presented by Kubelets. For testing purposes only.--requestheader-client-ca-file- Specify a root certificate bundle for verifying client certificates on incoming requests.
$ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.6/components.yaml
修改args参数:
...
84 containers:
85 - name: metrics-server
86 image: registry.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
87 imagePullPolicy: IfNotPresent
88 args:
89 - --cert-dir=/tmp
90 - --secure-port=4443
91 - --kubelet-insecure-tls
92 - --kubelet-preferred-address-types=InternalIP
...
执行安装:
$ kubectl create -f components.yaml
$ kubectl -n kube-system get pods
$ kubectl top nodes
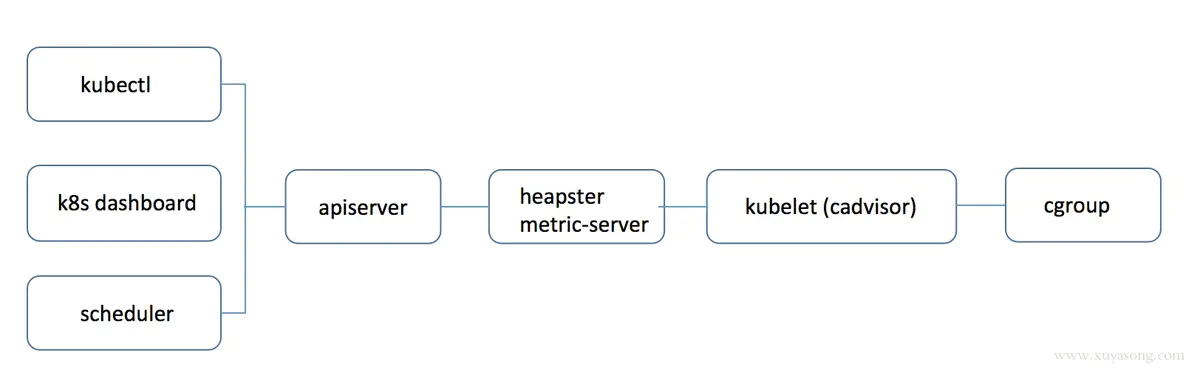
kubelet的指标采集
无论是 heapster还是 metric-server,都只是数据的中转和聚合,两者都是调用的 kubelet 的 api 接口获取的数据,而 kubelet 代码中实际采集指标的是 cadvisor 模块,你可以在 node 节点访问 10250 端口获取监控数据:
- Kubelet Summary metrics: https://127.0.0.1:10250/metrics,暴露 node、pod 汇总数据
- Cadvisor metrics: https://127.0.0.1:10250/metrics/cadvisor,暴露 container 维度数据
调用示例:
$ curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6InhXcmtaSG5ZODF1TVJ6dUcycnRLT2c4U3ZncVdoVjlLaVRxNG1wZ0pqVmcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1xNXBueiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImViZDg2ODZjLWZkYzAtNDRlZC04NmZlLTY5ZmE0ZTE1YjBmMCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbiJ9.iEIVMWg2mHPD88GQ2i4uc_60K4o17e39tN0VI_Q_s3TrRS8hmpi0pkEaN88igEKZm95Qf1qcN9J5W5eqOmcK2SN83Dd9dyGAGxuNAdEwi0i73weFHHsjDqokl9_4RGbHT5lRY46BbIGADIphcTeVbCggI6T_V9zBbtl8dcmsd-lD_6c6uC2INtPyIfz1FplynkjEVLapp_45aXZ9IMy76ljNSA8Uc061Uys6PD3IXsUD5JJfdm7lAt0F7rn9SdX1q10F2lIHYCMcCcfEpLr4Vkymxb4IU4RCR8BsMOPIO_yfRVeYZkG4gU2C47KwxpLsJRrTUcUXJktSEPdeYYXf9w" https://localhost:10250/metrics
kubelet虽然提供了 metric 接口,但实际监控逻辑由内置的cAdvisor模块负责,早期的时候,cadvisor是单独的组件,从k8s 1.12开始,cadvisor 监听的端口在k8s中被删除,所有监控数据统一由Kubelet的API提供。
cadvisor获取指标时实际调用的是 runc/libcontainer库,而libcontainer是对 cgroup文件 的封装,即 cadvsior也只是个转发者,它的数据来自于cgroup文件。
cgroup文件中的值是监控数据的最终来源,如
-
mem usage的值,
-
对于docker容器来讲,来源于
/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes -
对于pod来讲,
/sys/fs/cgroup/memory/kubepods/besteffort/pod[podId]/memory.usage_in_bytes或者/sys/fs/cgroup/memory/kubepods/burstable/pod[podId]/memory.usage_in_bytes
-
-
如果没限制内存,Limit = machine_mem,否则来自于
/sys/fs/cgroup/memory/docker/[id]/memory.limit_in_bytes -
内存使用率 = memory.usage_in_bytes/memory.limit_in_bytes
Metrics数据流:
思考:
Metrics Server是独立的一个服务,只能服务内部实现自己的api,是如何做到通过标准的kubernetes 的API格式暴露出去的?
kube-aggregator
kube-aggregator聚合器及Metric-Server的实现
kube-aggregator是对 apiserver 的api的一种拓展机制,它允许开发人员编写一个自己的服务,并把这个服务注册到k8s的api里面,即扩展 API 。
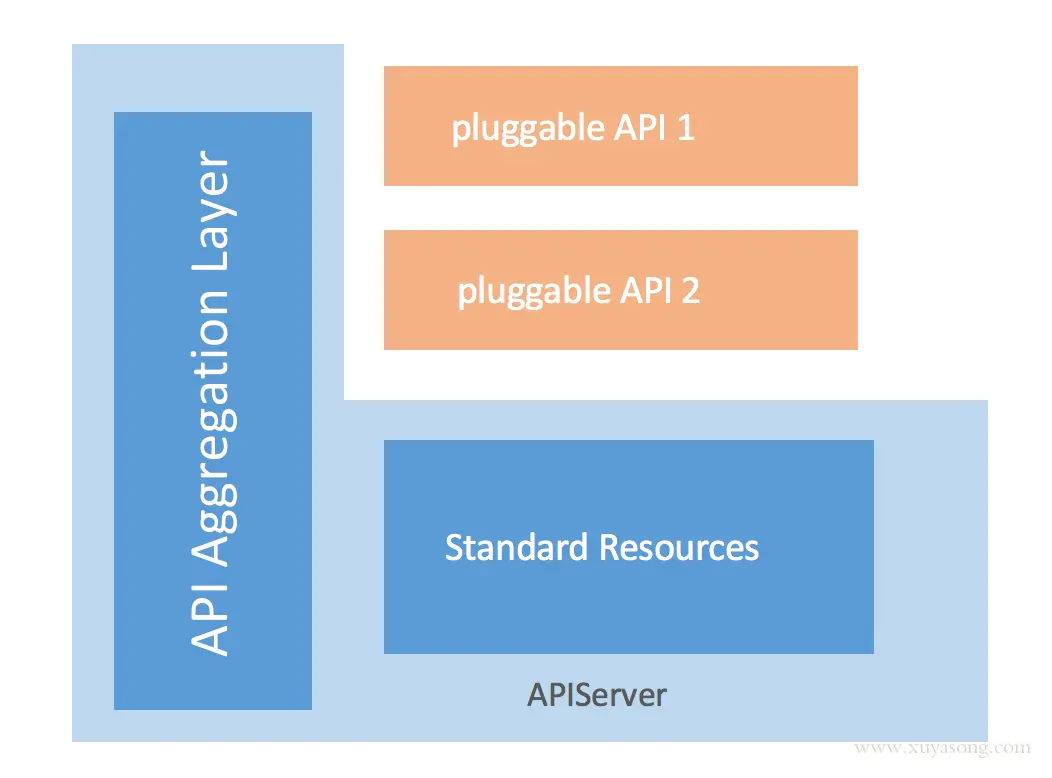
定义一个APIService对象:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.luffy.k8s.io
spec:
group: luffy.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: service-A # 必须https访问
namespace: luffy
port: 443
version: v1beta1
versionPriority: 100
k8s会自动帮我们代理如下url的请求:
proxyPath := "/apis/" + apiService.Spec.Group + "/" + apiService.Spec.Version
即:https://192.168.136.10:6443/apis/luffy.k8s.io/v1beta1/xxxx转到我们的service-A服务中,service-A中只需要实现 https://service-A/luffy.k8s.io/v1beta1/xxxx 即可。
看下metric-server的实现:
$ kubectl get apiservice
NAME SERVICE AVAILABLE
v1beta1.metrics.k8s.io kube-system/metrics-server True
$ kubectl get apiservice v1beta1.metrics.k8s.io -oyaml
...
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
port: 443
version: v1beta1
versionPriority: 100
...
$ kubectl -n kube-system get svc metrics-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP 10.110.111.146 <none> 443/TCP 11h
$ curl -k -H "Authorization: Bearer xxxx" https://10.110.111.146
{
"paths": [
"/apis",
"/apis/metrics.k8s.io",
"/apis/metrics.k8s.io/v1beta1",
"/healthz",
"/healthz/healthz",
"/healthz/log",
"/healthz/ping",
"/healthz/poststarthook/generic-apiserver-start-informers",
"/metrics",
"/openapi/v2",
"/version"
]
# https://192.168.136.10:6443/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
#
$ curl -k -H "Authorization: Bearer xxxx" https://10.110.111.146/apis/metrics.k8s.io/v1beta1/namespaces/luffy/pods/myblog-5d9ff54d4b-4rftt
$ curl -k -H "Authorization: Bearer xxxx" https://192.168.136.10:6443/apis/metrics.k8s.io/v1beta1/namespaces/luffy/pods/myblog-5d9ff54d4b-4rftt
HPA实践
基于CPU的动态伸缩
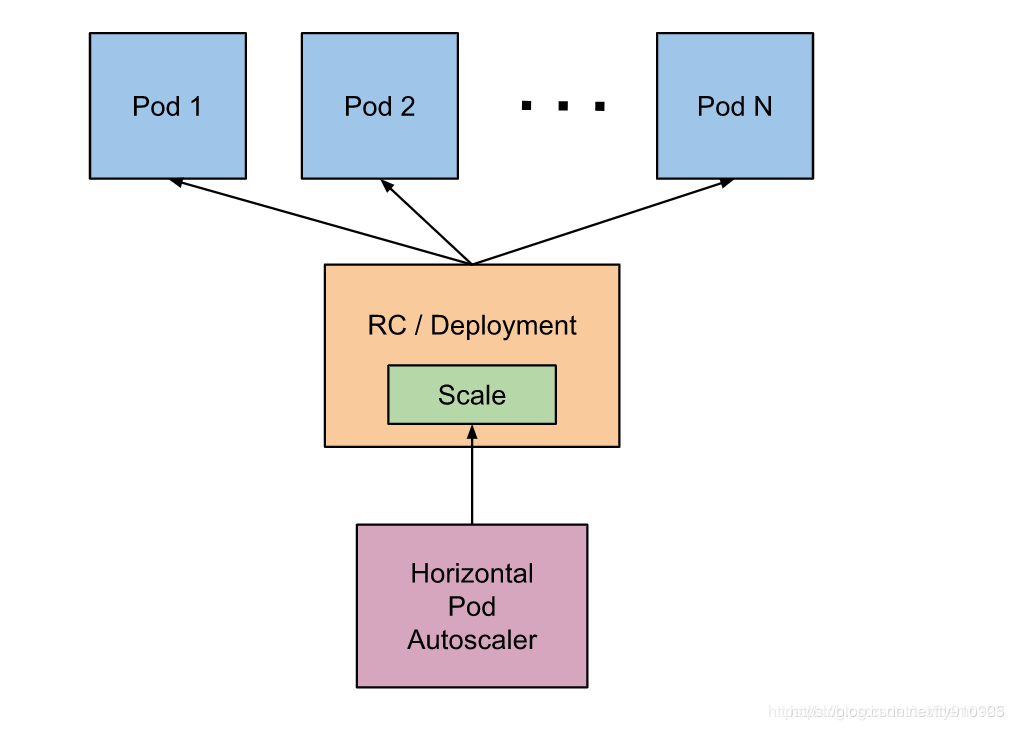
创建hpa对象:
# 方式一
$ cat hpa-myblog.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-myblog-cpu
namespace: luffy
spec:
maxReplicas: 3
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myblog
targetCPUUtilizationPercentage: 10
# 方式二
$ kubectl -n luffy autoscale deployment myblog --cpu-percent=10 --min=1 --max=3
Deployment对象必须配置requests的参数,不然无法获取监控数据,也无法通过HPA进行动态伸缩
验证:
$ yum -y install httpd-tools
$ kubectl -n luffy get svc myblog
myblog ClusterIP 10.104.245.225 <none> 80/TCP 6d18h
# 为了更快看到效果,先调整副本数为1
$ kubectl -n luffy scale deploy myblog --replicas=1
# 模拟1000个用户并发访问页面10万次
$ ab -n 100000 -c 1000 http://10.104.245.225/blog/index/
$ kubectl get hpa
$ kubectl -n luffy get pods
压力降下来后,会有默认5分钟的scaledown的时间,可以通过controller-manager的如下参数设置:
--horizontal-pod-autoscaler-downscale-stabilization
The value for this option is a duration that specifies how long the autoscaler has to wait before another downscale operation can be performed after the current one has completed. The default value is 5 minutes (5m0s).
是一个逐步的过程,当前的缩放完成后,下次缩放的时间间隔,比如从3个副本降低到1个副本,中间大概会等待2*5min = 10分钟
基于内存的动态伸缩
创建hpa对象
$ cat hpa-demo-mem.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-demo-mem
namespace: luffy
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-demo-mem
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: memory
targetAverageUtilization: 30
加压演示脚本:
$ cat increase-mem-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
namespace: luffy
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
测试deployment:
$ cat hpa-demo-mem-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo-mem
namespace: luffy
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: increase-mem-script
mountPath: /etc/script
resources:
requests:
memory: 50Mi
cpu: 50m
securityContext:
privileged: true
测试:
$ kubectl create -f increase-mem-config.yaml
$ kubectl create -f hpa-demo-mem.yaml
$ kubectl create -f hpa-demo-mem-deploy.yaml
$ kubectl -n luffy exec -ti hpa-demo-mem-7fc75bf5c8-xx424 sh
#/ sh /etc/script/increase-mem.sh
# 观察hpa及pod
$ kubectl -n luffy get hpa
$ kubectl -n luffy get po
基于自定义指标的动态伸缩
除了基于 CPU 和内存来进行自动扩缩容之外,我们还可以根据自定义的监控指标来进行。这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。
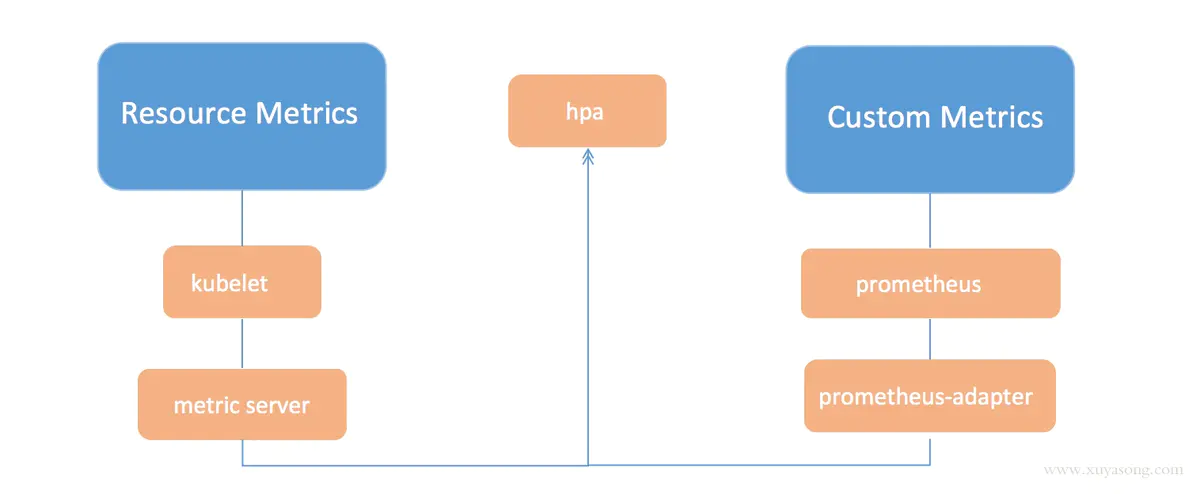
架构图: