【1】事件驱动
我们必须要讲明白什么是事件驱动,事件驱动模型或许这几年已经被大家说得烂了,听都不想听了。随着Nodejs的流行,大家都说,哎哟,事件驱动模型很牛逼,事件驱动模型非常快速blablabla。
实际上,事件驱动模型还有另外一个名字,而且更加出名的名字:io多路复用。
(1.1) io多路复用是啥?(通俗好理解)
噢,要讲明白io多路复用之前,我们还要知道一些概念,不要担心,我会用很傻的方式告诉你。
小张找基友小鹏:
小张第一次来到小鹏的宿舍楼,发现这个宿舍楼有一大堆的楼妈,为啥?因为学校竟然请了一堆楼妈来管理宿舍楼里的每一个宿舍,结果搞得一大堆楼妈唧唧咋咋的,乌烟瘴气。
重要的就是学校会给每个楼妈都发工资。小张顿时觉得,这个学校没药救了。
没错,现实中已经没有这种傻逼现象了,学校也不会傻到这种程度为每一个宿舍都请一个楼妈来管理。
了几十年,小张的儿子来找小鹏的儿子
不巧,过了一二十年,小张的儿子和小鹏的儿子也上了同一所学校,小张张要来找小鹏鹏。小张张听了父亲说,这个学校的舍管特别傻逼,会有一堆,能烦死你。
结果小张张来到了宿舍楼,发现现在只有一个楼妈了,哎哟,不错嘛,学校终于没那么傻逼了。但是,这个楼妈比较傻,小张张去问她:小鹏鹏在哪个寝室啊?
她说,我也不知道啊。我带你上去找吧?
于是乎,小张张和楼妈挨个挨个的找宿舍,最终花了半天时间找到了小鹏鹏....(小张张尿了。
又过去了差不多20年
此时,学校已经不是那个学校,张和鹏都挂得差不多了。新生代小春来找小丽,小春来到了这个宿舍,找到了楼妈。
这个楼妈就比较聪明了,每当一个学生入住新宿舍的时候,她就记录下这个人的名字,学号,电话,以及宿舍房号。
当小春找小丽的时候,楼妈掏出眼镜,查表,马上就能知道小丽在哪里了,小春几分钟就到达了小丽的宿舍....
(1.2)编程界对IO模型的发展
(1)fork/thread模型
对应到编程界,在最开始的时候,为了实现一个服务器可以支持多个客户端连接,人们想出了fork/thread等办法,当一个连接来到的时候,就fork/thread一个进程/线程去接收并且处理请求;
然而,当时估计是大家都穷吧,没啥钱买电脑,所以这个模型一直很好用,过去几十年都没有问题。
但是时代发展了,1980年代,计算机网络开始成型,越来越多的用户进行网络连接(其实也没多少),但是之前的fork/thread模型就不行了,太辣鸡了。(回想一下小张和小鹏与一大堆楼妈的故事)
(2)select函数发明
1983年,人们终于意识到了这种问题,所以发明了一种叫做「IO多路复用」的模型,这种模型的好处就是「没必要开那么多条线程和进程了」,一个线程一个进程就搞定了。随着计算机业务的增长,这种IO多路复用的模型看似太傻逼了点,回想一下小张张和小鹏鹏:
- 宿舍楼里有可能有上百间宿舍
- 为了寻找到其中一间宿舍,你必须得一间一间去找,浪费时间
对应的编程模型就是:一个连接来了,就必须遍历所有已经注册的文件描述符,来找到那个需要处理信息的文件描述符,如果已经注册了几万个文件描述符,那会因为遍历这些已经注册的文件描述符,导致cpu爆炸。
(3)epoll 方式
直到2002年,互联网时代爆炸,数以千万计的请求在全世界范围内发来发去,服务器大爆炸,人们通过改进「IO多路复用」模型,进一步的优化,发明了一个叫做epoll的方法。这个方法就是小春和小丽故事里聪明的楼妈。
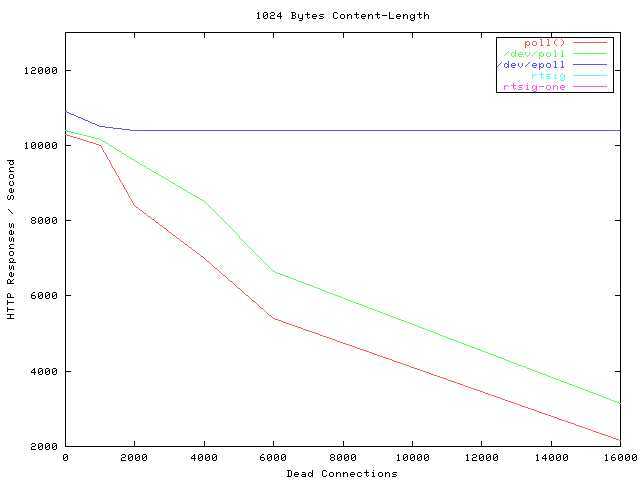
这就是当年的并发图,震撼人心的并发图。我们可以看到蓝色的线是epoll,性能几乎不受连接数的影响(dead connections),无敌的并发!
【2】事件驱动的一个缺点


事件驱动不是无敌的,在事件驱动模型中,处理事件的进程一定是单线程的。
在现代工业中我们会面临两个问题:
- 单线程模型不能有阻塞,一旦发生任何阻塞(包括计算机计算延迟)都会使得这个模型不如多线程。另外,单线程模型不能很好的利用多核cpu。
- 既然不能有阻塞,那我们只有用多线程去做异步io,那马上就会面临回掉地狱。
为了解决我上述说的两个问题人们做出了一些改进:
- 利用多进程,每个进程单条线程去利用多核CPU。但是这又引入了新的问题:进程间状态共享和通信。但是对于提升的性能来说,可以忽略不计。
- 发明了协程。
【3】协程
协程的概念是相对多进程或者多线程来说的,他是一种协作式的用户态线程
- 与之相对的,线程和进程是以抢占式执行的,意思就是系统帮我们自动快速切换线程和进程来让我们感觉同步运行的感觉,这个切换动作由系统自动完成
- 协作式执行说的就是,想要切换线程,你必须要用户手动来切换
协程为什么那么快原因就是因为,无需系统自动切换(系统自动切换会浪费很多的资源),而协程是我们用户手动切换,而且是在同一个栈上执行,速度就会非常快而且省资源。
但是,协程有他自己的问题:协程只能有一个进程,一个线程在跑,一旦发生IO阻塞,这个程序就会卡住。
所以我们要使用协程之前,必须要保证我们所有的IO都必须是非阻塞的。
3.1 所有IO非阻塞/异步IO
IO无非就是几种
- 读(硬盘的)的
- 写(硬盘的)的
- 网络请求(读和写)
所有的读和写,网络请求接口都要设置成非阻塞式的,当系统内核把这些玩意儿执行完毕以后,再通过回调函数,通知用户处理。在用户空间上来看,我们就一直保持在一个线程,一个进程之中,因此,这种速率极高!
为什么Nodejs并发量会那么变态的原因就是这一点:nodejs因为js线程只有一条(底层的IO使用多线程来实现非阻塞),为了让程序不会卡住,就一定要把所有的IO变成非阻塞异步,通过回调来告诉用户。
那么问题就来了:
- 我们进行IO操作的目的是因为我们想获得某些数据然后再开始进行操作,所以我们不得不在回调函数中操作。
- 我们在回调函数中获取到我们想要的数据,我们依靠这段数据又他妈的想要获取另外一段数据,怎么办?继续回调。
- 一两层你可能就觉得不行了,45678层呢?
3.2 协程真正目的
协程的真正目的其实并不是为了解决高并发而存在的,而是为了解决这种蛋痛的无限回调而存在的
使用协程之后,我们就可以像使用「同步」的方法去写异步的调用,刚刚开始听到的时候,你可能会懵逼了。
不过没事,等我们写代码的时候就会深刻体会了。
3.3 总结
在接下去的web时代里,异步io配合协程就是主导。
i/O多路复用技术已经出现了快40年了,不是新东西
【参考文档】
转自:https://www.zhihu.com/question/28594409/answer/345897182
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。