一.实验
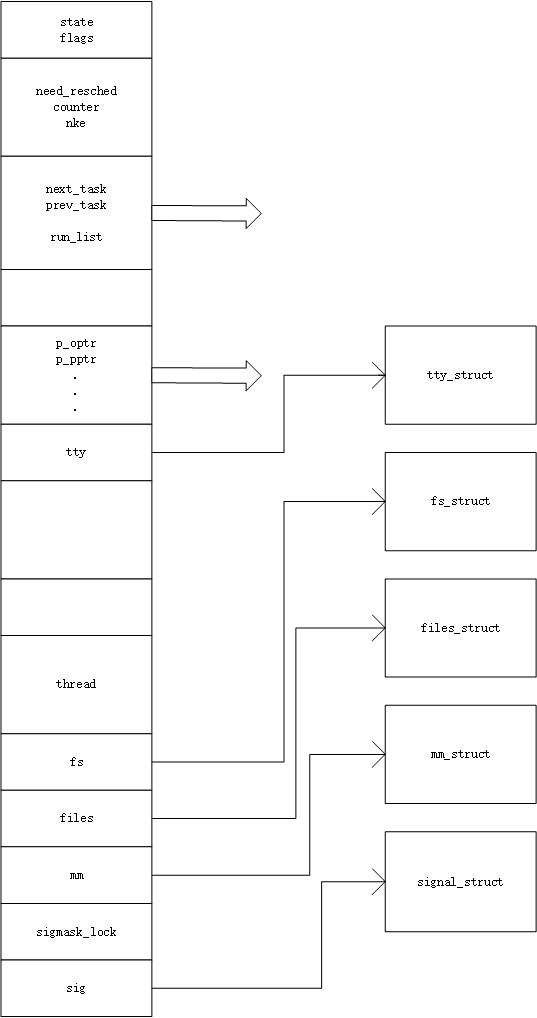
1.1task_struct数据结构
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。它定义在linux-3.18.6/include/linux/sched.h文件中。
这个结构体定义非常庞大,目测有300多行代码,所以只摘录了部分关键定义:
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack; /*进程堆栈*/
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
pid_t pid;
pid_t tgid;
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
}
用一张比较形象的图表可以说明进程描述符大体结构和其功能:
1.2分析sys_clone如何创建进程和修改task_struct
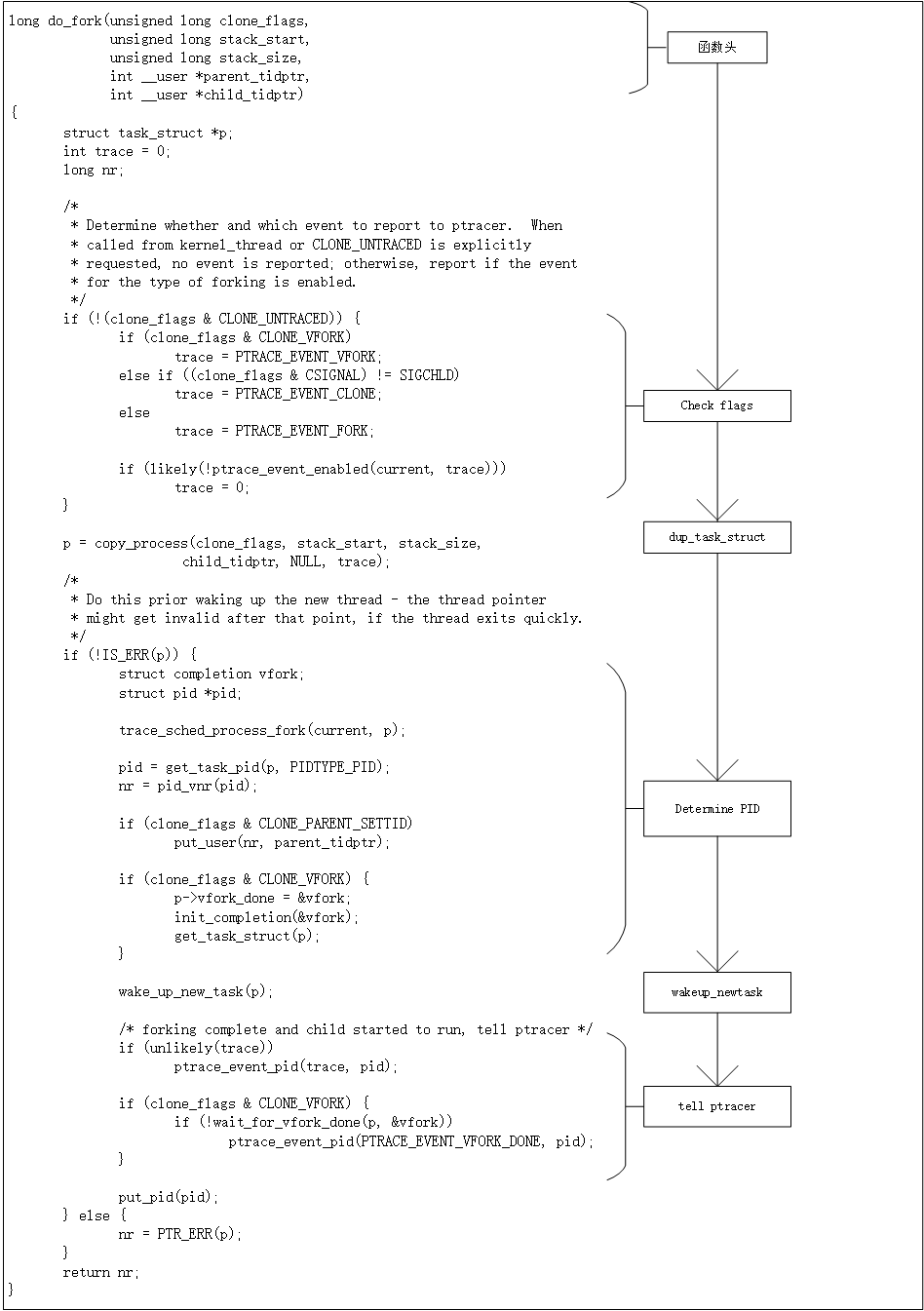
系统调用服务例程sys_clone, sys_fork, sys_vfork三者最终都是调用do_fork函数完成。这三者的区别详细见——Linux中fork,vfork和clone详解(区别与联系)。do_fork函数原型位于linux-3.18.6/kernel/fork.c。
单从do_fork这个函数的参数来看,创建一个新的进程需要传入的参数有:clone_flags,从字面意思这个参数是克隆的父进程的状态;stack_start,为要创建进程的堆栈的起始位置,联合下一个参数stack_size(堆栈大小)共同决定了该进程的堆栈区域;parent_tidptr和child_tidptr传入的目的是将该进程置于系统进程链表。下面从实现角度分析各个部分的功能(右边为do_fork流程):
1.3使用gdb跟踪分析fork调用内核函数sys_clone的过程
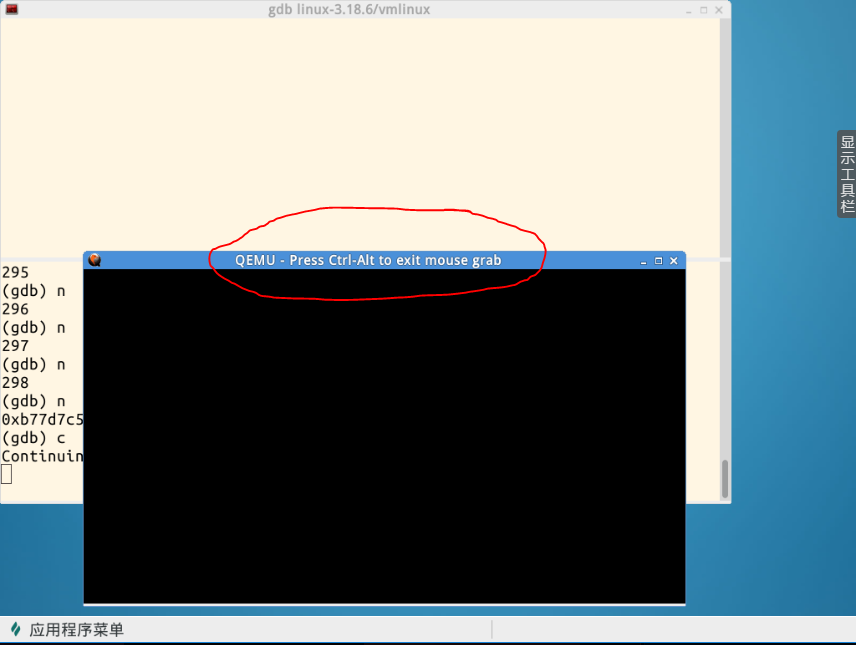
PS:继上次作业,我发现一个问题——在实验楼环境下使用gdb跟踪MenuOS启动后输入命令后会出现死机,然后只能重复之前步骤重新来一遍操作。本实验开始时有些头疼,因为要想完成对fork命令的追踪也必须在Qemu虚拟机中输入命令,果然在最开始时还是出现了同样的问题。不得已我决定将3.18.6的内核下载到自己的虚拟机,结果出现了尴尬的现象,就是我的Ubuntu64位虚拟机能开启,但却是黑屏,上网查资料后于事无补,很多方法试了都没用,所以一怒之下从磁盘中删去了该虚拟机(我之前的linux所有程序都在该虚拟机上,从linux内核原理与分析课一开始就用的这个虚拟机,可想而知里面有多少重要的东西)。如果我之前抓了快照恢复一下可能就好了,然而我重来没有抓取过快照,即使出了问题也直接把虚拟机扔了重新创建一个。所以抓拍快照很重要!抓拍快照很重要!抓拍快照很重要。然而等我新建虚拟机时候发现引导界面也是黑屏,这时我预感到我可能犯了愚蠢的错误,等我打开其他虚拟机,同样是黑屏!!!立刻重启实体机,好了,黑屏不存在了!数据恢复不了那个虚拟机,再怎么说它也是一个系统。所以我白白给自己创造了一个巨大的问题!接着重新建一个Ubuntu,等到我一步步把内核下载好,编译的时候又出现问题——我的Ubuntu是64位,实验要求32位!强忍内心的愤怒查资料下载了32位库,然而问题并没有解决(貌似它并没有找见我下载的32位库在哪,我也不知道在哪。。。)至此我再没有耐心又回到了实验楼!值得反思的一个事实是,很多时候在你跋山涉水经历万千磨难后最终发现你一开始要找的答案就在原点,然而一开始你却不知道它就在脚下!我想,明白这个道理比我做这个实验得到的理论知识更有意义!原来在进入Qemu虚拟机后必须按Ctrl+Alt后才能再回到桌面环境,这句话就写在:
解决“死机”问题后,仍旧选择实验楼环境:
基本命令如下:
cd LinuxKernel
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c //在makefile中编译命令用的是 test.c,这是改名的原因!
cd ..
qemu -kernel linux3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
gdb linux3.18.6/vmlinux
验证是否成功将fork添加:
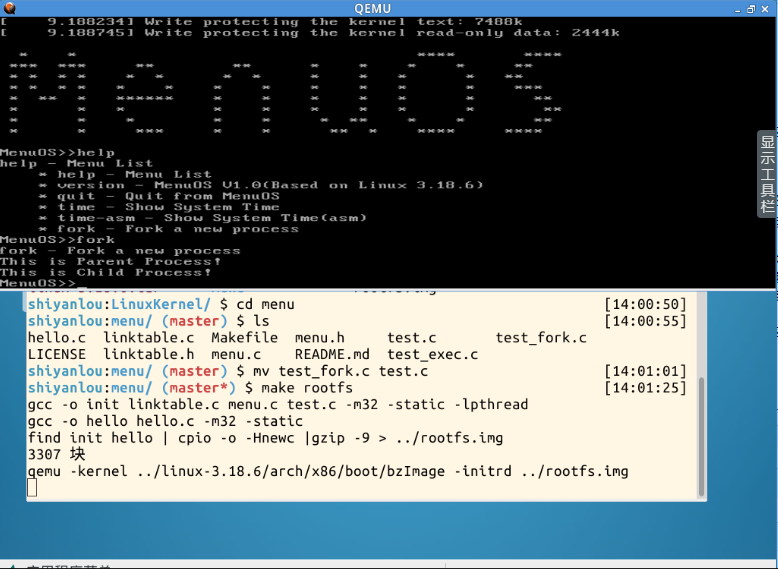
在创建进程的关键函数上设置断点:
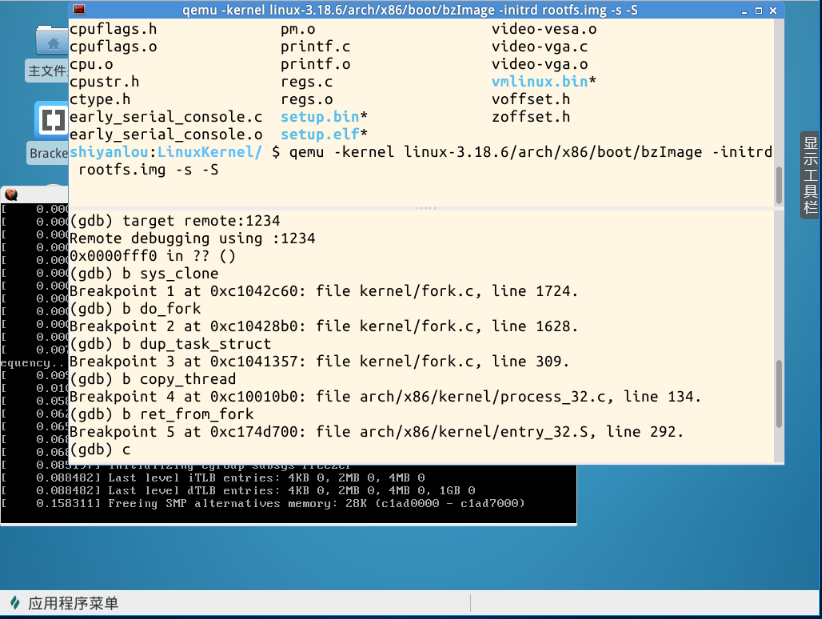
起初没解决PS中的难题时我是直接在内核启动时就设置了上图的断点,得出如下结论:
- 内核启动时创建过很多进程!
- 尽管创建过很多进程,但不会调用ret_from_fork函数!
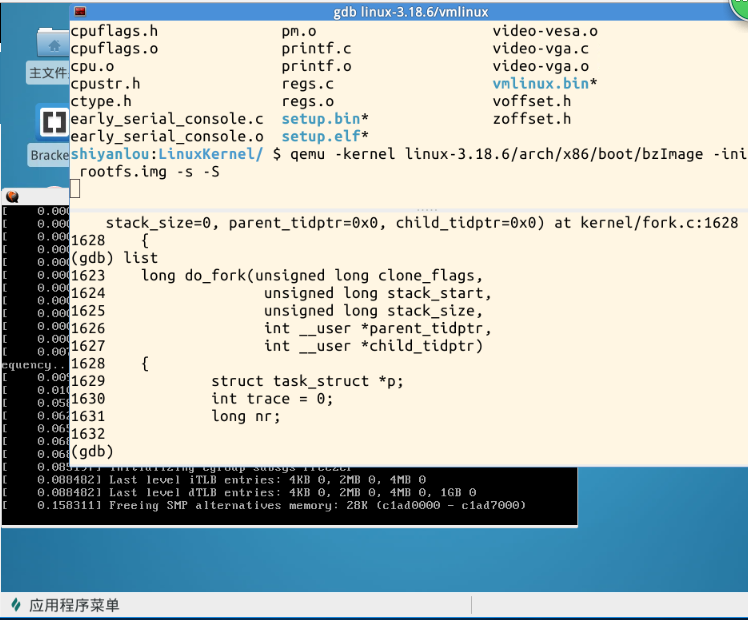

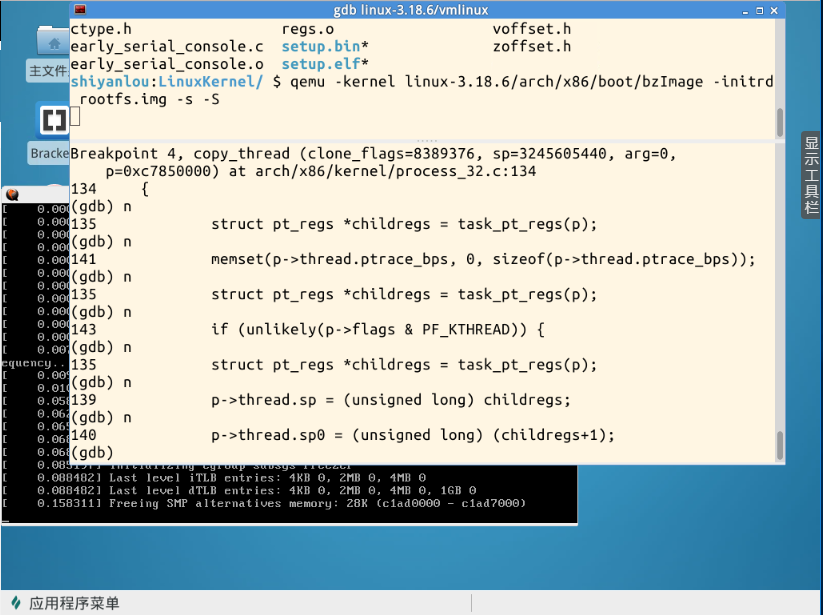
从上面的图中大家可以看到,这时候MenuOS并没有完全启动,我同样追踪到了do_fork、dup_task_struct、copy_process和copy_thread。下面的截图是解决PS中“问题”后追踪到的ret_from_fork:
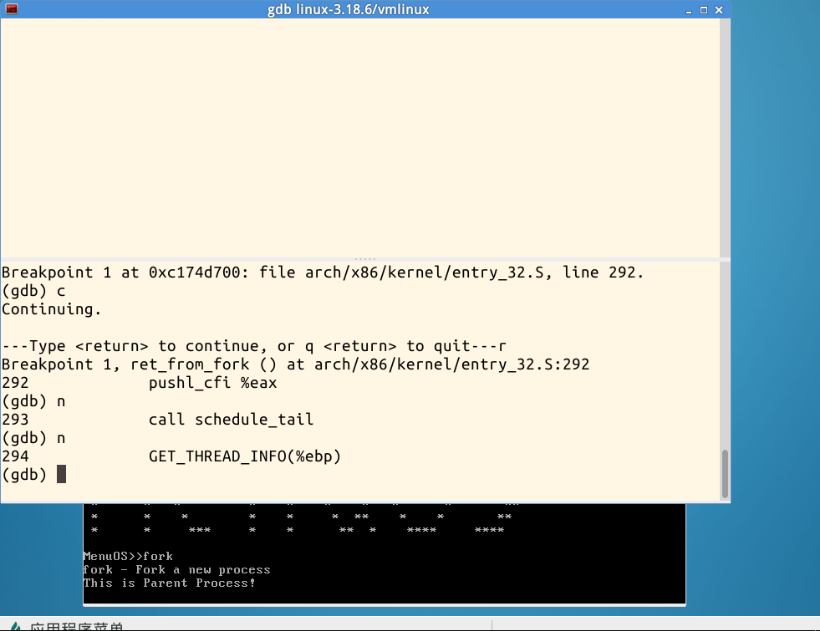
1.4实验总结
本次实验最为关心的问题就是新的进程从哪开始执行?上面两张图足以说明这个问题。ret_from_fork中跳转到syscall_exit后面的代码虽然追踪不到,但在它结束时,子进程创建完成。syscall_exit属于系统调用中的一个环节,从上次实验的结果来看,接下来的步骤还有syscall_exit_work!这也从侧面证实上次实验结果中的一个问题,那就是在work_pending中有一个判断,是否发生进程调度!所以在syscall_exit的时候会发生进程调度,最起码可能会创建一个新的进程!
二.课本十一、十二章
2.1相对时间与绝对时间
如果某个事件在5s后被调度执行,那么系统所需要的不是绝对时间,而是相对时间(比如,相对现在起5s后);相反,如果要求管理当前日期和当前时间,则内核不但要计算流逝的时间而且还要计算绝对时间。系统定时器以某种频率自行触发(经常被称为击中或射中)时钟中断,该频率可以通过编程预定,称作节拍率。当时钟中断发生时,内核就通过一种特殊的中断处理程序对其进行处理。
2.2jiffies
全局变量jiffies用来记录系统启动以来产生的节拍总数。启动时,内核将该变量初始化为0,此后,每次时钟中断处理程序就会增加该变量的值。jiffies的定义:
extern unsigned long volatile jiffies和extern u64 jiffies_64
jiffies回绕是指当jiffies达到最大值时,它的值变回0重新开始。
2.3实时时钟
实时时钟是用来持久存放系统时间的设备,即使系统关闭后,它也可以靠主板上的微型电池供电保持系统的计时。在PC体系结构中,RTC和CMOS集成在一起,而且RTC的运行和BIOS的保存设置都是同一个电池供电。
2.4延迟执行——schedule_timeout()
最理想的延迟执行方法是使用schedule_timeout()函数,该方法会让需要延迟执行的任务睡眠到指定的延迟时间耗尽后再重新运行。当指定时间到期后,内核唤醒被延迟的任务并将其重新放回运行队列,用法:set_current_state(TASK_INTERRUPTIBLE);schedule_timeout(s*HZ)
2.5slab
slab层(slab分配器)把不同的对象划分为告诉缓存组,其中每个高速缓存组存放不同类型对象(这好像与普通的高速缓存有区别?)。每种对象类型对应一个高速缓存;高速缓存又被划分为slab。slab由一个或多个物理连续的页组成。每个高速缓存可以由多个slab组成。slab描述符如下:
struct slab{
struct list_head list; //满、部分满或空链表
unsigned long colouroff; //slab着色的偏移量
void *s_mem; //在slab中的第一个对象
undigned int inuse; //slab中已经分配的对象数
keme_bufctl_t free; //第一个空闲对象
}
一个新的告诉缓存通过以下函数创建:
struct kmem_cache *kmem_cache_create(const char *name,size_t size,size_t align,unsigned long flags, woid(*ctor)(void *));。
读完课本,我觉得slab就是cache的一种实现类型。