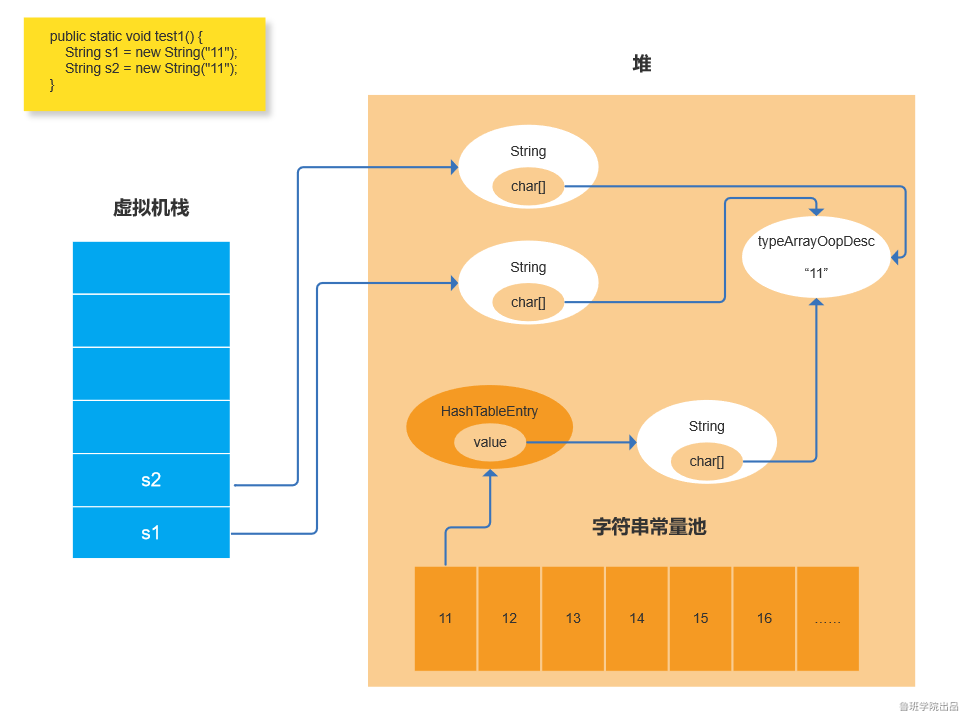
简介
字符数组的存储方式
字符串常量池
字符串在java程序中被大量使用,为了避免每次都创建相同的字符串对象及内存分配,JVM内部对字符串对象的创建做了一定的优化,在Permanent Generation中专门有一块区域用来存储字符串常量池(一组指针指向Heap中的String对象的内存地址)。
在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个HashTable,默认值大小长度是1009;这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。字符串常量由一个一个字符组成,放在了StringTable上。在JDK6.0中,StringTable的长度是固定的,长度就是1009,因此如果放入String Pool中的String非常多,就会造成hash冲突,导致链表过长,当调用String#intern()时会需要到链表上一个一个找,从而导致性能大幅度下降;
- 在JDK6.0及之前版本中,String Pool里放的都是字符串常量;
- 在JDK7.0中,由于String#intern()发生了改变,因此String Pool中也可以存放放于堆内的字符串对象的引用。关于String在内存中的存储和String#intern()方法的说明。
字符串Hashcode
不通方式创建字符串在JVM存储的形式
-
双引号方式
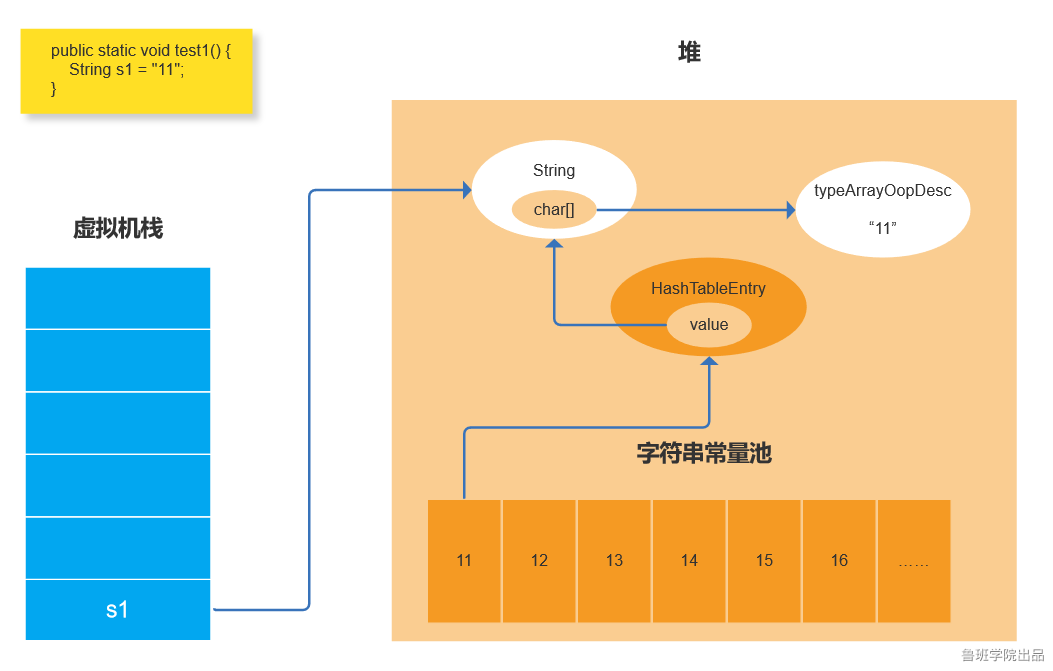
双引号引起来的字符串,首先从常量池中查找是否存在此字符串。如果不存在,则在常量池中添加此字符串。在堆中创建字符串对象,因String底层是通过char数组形式存储的,所以同时会在堆中生成一个TypeArrayOopDesc用来存储char数组对象。如果存在,则直接引用此字符串对象。
测试代码1:
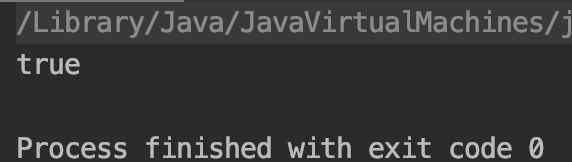
public static void test1(){ String s1="11"; String s2="11"; System.out.println(s1==s2); }
测试结果:
原因分析:
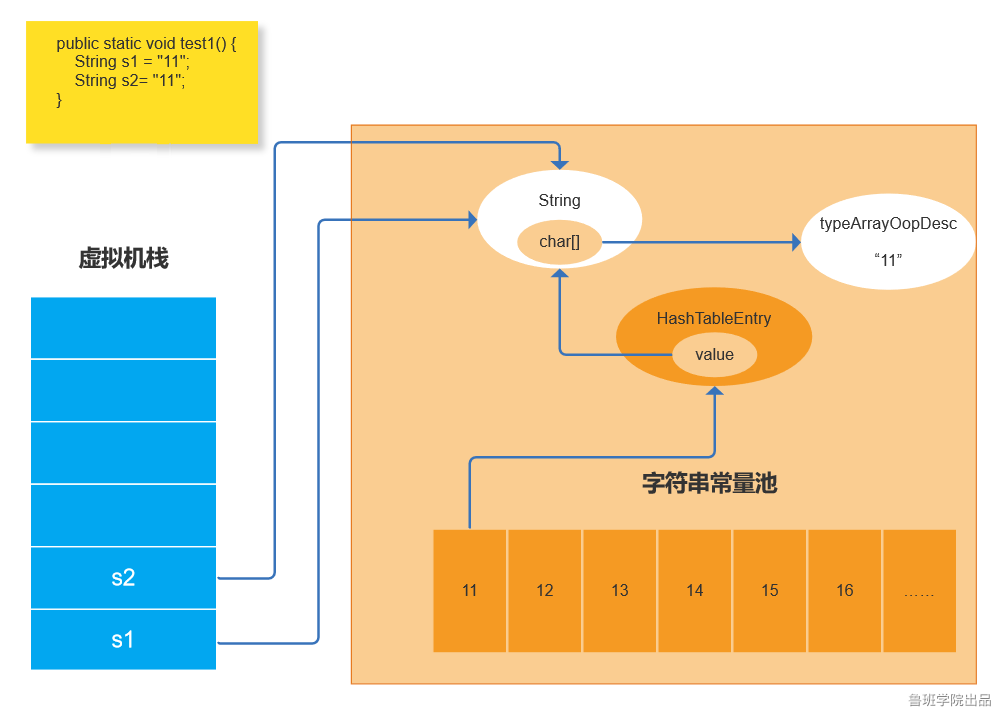
s1代码执行后,常量池中添加了“11”这个常量,在堆中也创建了String对象并引用此常量的。当s2代码执行时,先在常量池中查找是否存在“11”这个常量,发现常量池中存在这个值,就找到引用此常量的字符串对象,将s2的引用指向找到的字符串对象。因为s1和s2指向同一个地址,所以比较结果为true。
-
new String
1、首先从常量池中查找是否存在括号内的常量,如果不存在,则在常量池中添加此字符串。在堆中创建字符串对象,因String底层是通过char数组形式存储的,所以同时会在堆中生成一个TypeArrayOopDesc用来存储char数组对象。如果存在,则直接引用堆中存在的字符串对象。
2、通过new方式创建的String对象,每次都会在Heap上创建一个新的实例。并将此新实例中char数组对象,指向第一步堆中的已经存在的TypeArrayOopDesc。
测试代码:
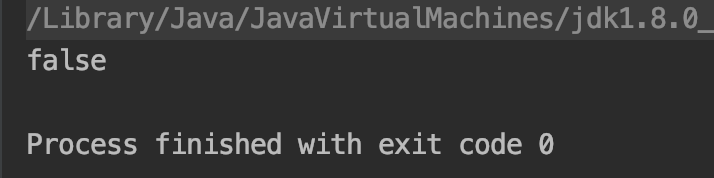
public static void test2() { String s1 = new String("11"); String s2 = new String("11"); System.out.println(s1 == s2); }
测试结果:
原因分析:
通过new方式创建的String对象,每次都会在Heap上创建一个新的实例。所以s1和s2的分别指向了不同的实例,引用地址不同。
测试代码:
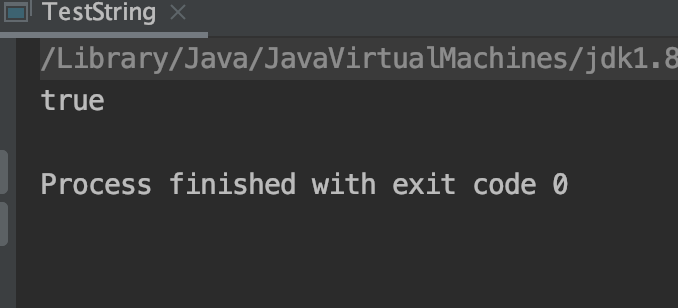
public static void test3() { String s1 = new String("11"); String s2 = "11"; System.out.println(s1 == s2); }
测试结果:
原因分析:
当执行s1时,首先会将括号内的字面量常量“11”添加到常量池中,并且在堆中生成字符串实例及char数组实例TypeArrayOopDesc。再通过new方式创建的String对象,会在Heap上新创建一个实例,此新实例中char数组不需要新的实例,指向堆中的已存在的TypeArrayOopDesc。
当执行s2时,在常量池中发现常量已存在,则直接将虚拟机栈的指向堆中代表此常量的字符串实例。
因此s1和s2的分别指向了不同的实例,引用地址不同。
【缺图】
字符串在JVM中是如何拼接的
测试代码:
public static void test4(){ String s2="1"+"1"; String s1="11"; System.out.println(s1==s2); }
测试结果:
原因分析:
文件在编译期成字节码时,编译器将“1”+“1”变成了“11”,编译后,相当于s2="11"。就与上面的测试代码1相同了,具体原因见测试代码1的原因分析。
测试代码:
public static void test5(){ String s1="1"; String s2="1"; String s3=s1+s2; String s4="11"; System.out.println(s3==s4); }
测试结果:
原因分析:
编译器在编译时无法确定s3的值,是在运行时才能确定,保存在jvm的堆里面,在拼接的时候,先在常量池里面生成是s1、s2的字符串,在执行加号的时候,会从常量池中取出s1、s2常量,在堆中生成两个字符串对象,然后再生成第三个字符串对象来保存两个对象拼接后的值。
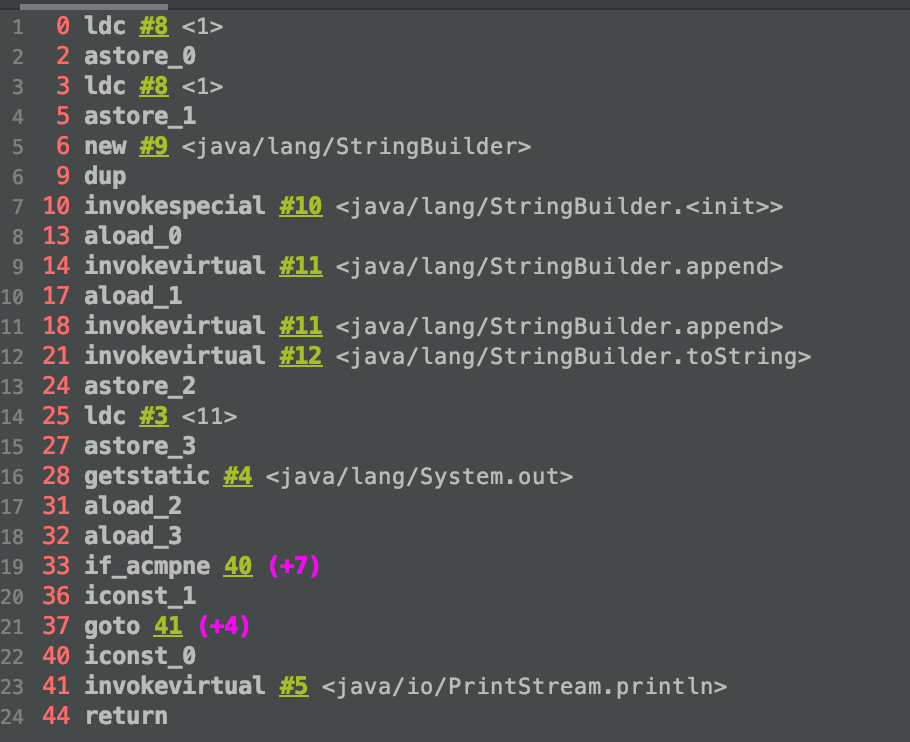
测试代码:
public static void test6() { final String s1 = "1"; final String s2 = "1"; String s3 = s1 + s2; String s4 = "11"; System.out.println(s3 == s4); }
测试结果:
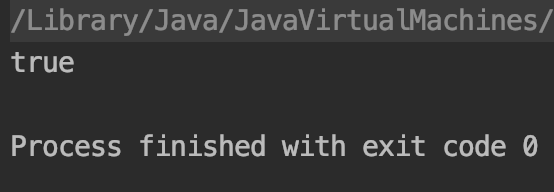
原因分析:
通过s1、s2增加final修饰符,s1和s2的值赋值后不允许改变,这样编译器在编译时会把s3编译成s3="11",所以在执行时会字符串常量池中添加“11”这个常量,执行s4时会在常量池中找到“11”这个常量, s4会执行堆中已存在的字符串对象。因此s3和s4相等。
intern做了什么
intern()方法:
public String intern()
JDK源代码如下图:

返回字符串对象的规范化表示形式。
一个初始时为空的字符串池,它由类 String 私有地维护。
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(该对象由 equals(Object) 方法确定),
则返回池中的字符串。否则,将此 String 对象添加到池中,并且返回此 String 对象的引用。
它遵循对于任何两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
所有字面值字符串和字符串赋值表达式都是内部的。
返回:
一个字符串,内容与此字符串相同,但它保证来自字符串池中。
尽管在输出中调用intern方法并没有什么效果,但是实际上后台这个方法会做一系列的动作和操作。
在调用”ab”.intern()方法的时候会返回”ab”,但是这个方法会首先检查字符串池中是否有”ab”这个字符串,
如果存在则返回这个字符串的引用,否则就将这个字符串添加到字符串池中,然会返回这个字符串的引用。
测试代码:
public static void test8_3(){ String s1="11"; String s2=new String("11"); String s3=s2.intern(); System.out.println(s1==s2);//#1 System.out.println(s1==s3);//#2 }
测试结果:
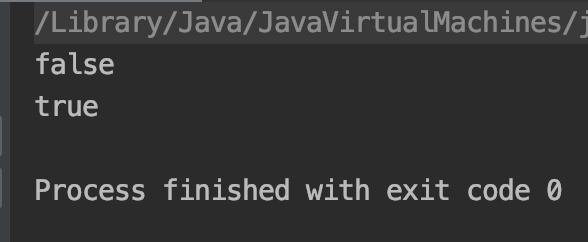
原因分析:
结果 #1:因为s1指向的是字符串中的常量,s2是在堆中生成的对象,所以s1==s2返回false。
结果 #2:s2调用intern方法,会将s2中值(“string”)复制到常量池中,但是常量池中已经存在该字符串(即s1指向的字符串),
所以直接返回该字符串的引用,因此s1==s2返回true。
测试代码:
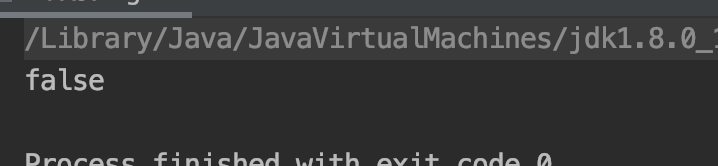
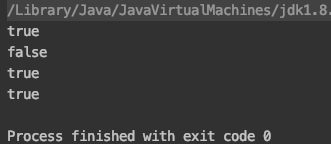
public static void test8_4(){ String s1="1"; final String s2="1"; String s3="11"; String s4="1"+"1"; String s5=s1+"1"; String s6=s2+"1"; String s7=new String("11").toString().intern(); System.out.println(s3==s4);//#1 System.out.println(s3==s5);//#2 System.out.println(s3==s6);//#3 System.out.println(s3==s7);//#4 }
测试结果:
原因分析:
通过反编译文件,比较容易理解:
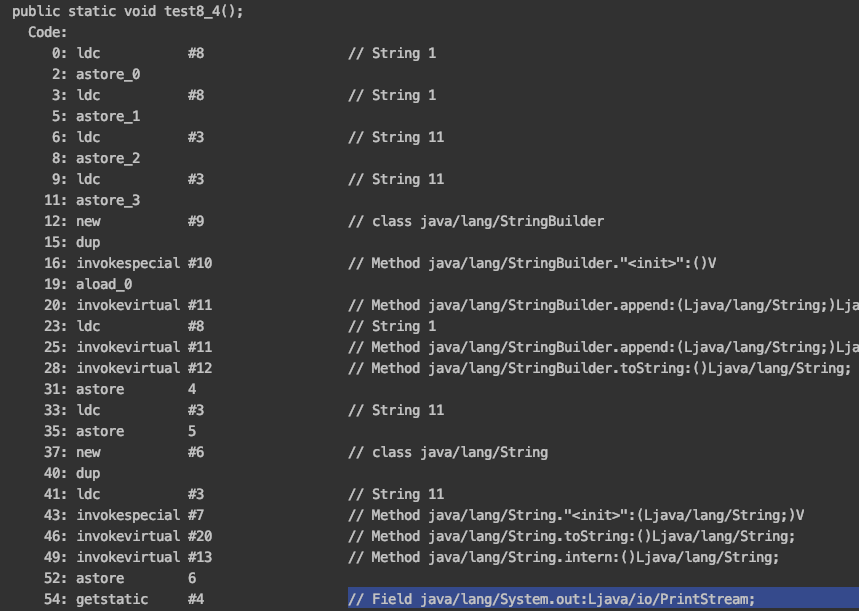
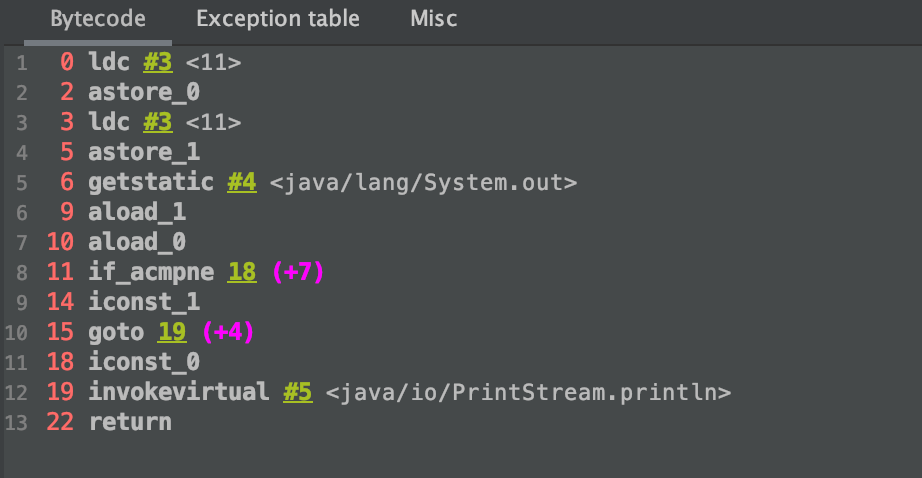
在解释上述执行过程之前,先了解两条指令:
ldc:Push item from run-time constant pool,从常量池中加载指定项的引用到栈。
astore_<n>:Store reference into local variable,将引用赋值给第n个局部变量。
现在我们开始解释字节码的执行过程:
0: ldc #8 :加载常量池中的第八项(“1”)到栈中。
2: astore_0 :将1中的引用复制给第零个局部变量,即 String s1="1";
3: ldc #8 :加载常量池中的第八项(“1”)到栈中。
5: astore_1 :将3中的引用赋值给第一个局部变量,即 final String s2="1";
6: ldc #3 :加载常量池中的第三项(“11”)到栈中。
8: astore_2 :将6中的引用赋值给第二个局部变量,即 String s3="11";
9: ldc #3 :加载常量池中的第三项(“11”)到栈中。
11: astore_3 :将9中的引用赋值给第三个局部变量,即 String s4="11";
结果#1:s3==s4 肯定会返回true,因为s3和s4都指向常量池中的同一引用地址。
其实在JAVA 1.6之后,常量字符串的“+”操作,编译阶段直接会合成为一个字符串。
12: new #9:生成StringBuilder的实例。
15: dup :赋值12生成对象的引用并压入栈中。
16: invokespecial #10: 滴啊用常量池中的第十项,即StringBuilder.<init>方法。
以上三条指令的作用是生成一个StringBuilder的对象。
19: aload_0 :加载第零个局部变量的值,即“1”
20: invokevirtual #11 : 调用StringBuilder对象的append方法。
23: ldc #8 :加载常量池中第八项(“1”)到栈中。
25: invokevirtual #11 :调用StringBuilder对象的append方法。
28: invokevirtual #12 :调用StringBuilder对象的toString方法。
31: astore 4 :将28中的结果引用赋值给第四个局部变量,即对变量s5进行赋值。
结果 #2:因为s5实际上是stringBuilder.append()生成的结果,所以与s3不相等,结果返回false。
33: ldc #3:加载常量池中第三项(“11”) 到栈中。
35: astore 5 :将33中的引用赋值给第五个局部变量,即s6=“11”。
结果 #3 :因为s3和s6指向的都是常量池中相同的引用,所以s3==s6返回true。
这里我们还能发现一个现象,对于加了final属性的字段,编译期直接进行了常量替换,而对于非final字段则是在运行期进行赋值处理的。
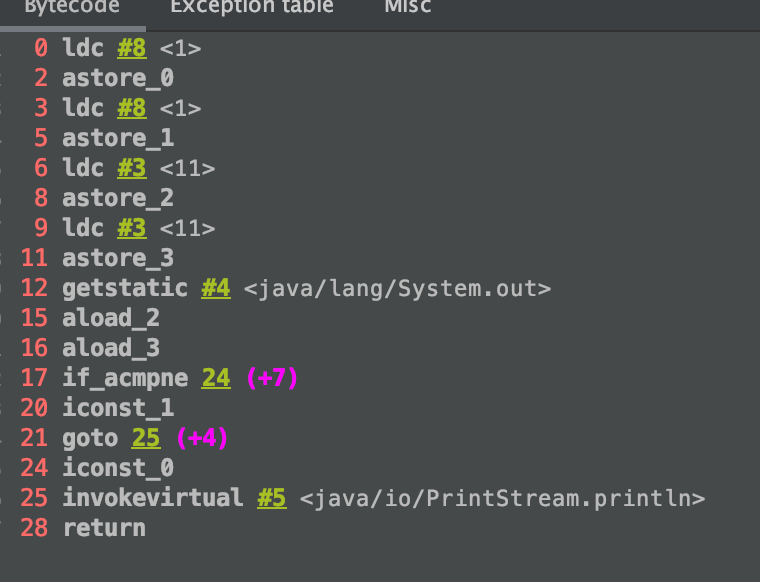
37: new #6 :创建String对象。
40: dup :复制引用并压如栈中。
41: ldc #3:加载常量池中的第三项(“11”)到栈中。
43: invokespecial #7 :调用String.”<init>”方法,并传42步骤中的引用作为参数传入该方法。
46: invokevirtual #20 :调用String.tostring()方法。
49: invokevirtual #13 :调用String.intern方法。
从37到49的对应的源码就是new String("11").toString().intern();
52: astore 6 :将49步返回的结果赋值给变量6,即s7指向11在常量池中的位置。
结果 #6 :因为s7和str3都指向的都是常量池中的同一个字符串,所以s3==s7返回true。
测试代码:
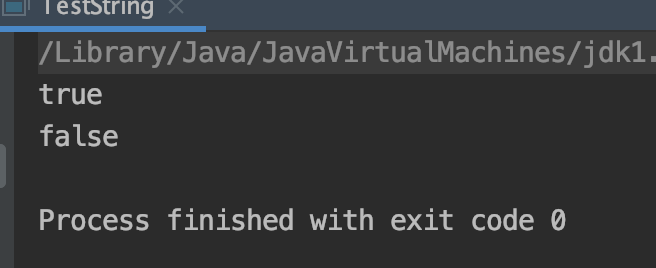
public static void test8_5_1(){ String s1=new String("1")+new String("1"); s1.intern(); String s2="11"; System.out.println(s1==s2);//#1 } public static void test8_5_2(){ String s2="11"; String s1=new String("1")+new String("1"); s1.intern(); System.out.println(s1==s2);//#2 }
测试结果:
原因分析:
JDK 1.7后,对于第一种情况返回true,但是调换了一下位置返回的结果就变成了false。这个原因主要是从JDK 1.7后,
HotSpot 将常量池从永久代移到了元空间,正因为如此,JDK 1.7 后的intern方法在实现上发生了比较大的改变,
JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,
如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。所以:
结果 #1:在第一种情况下,因为常量池中没有“11”这个字符串,所以会在常量池中生成一个对堆中的“11”的引用,
而在进行字面量赋值的时候,常量池中已经存在,所以直接返回该引用即可,因此s1和s2都指向堆中的字符串,返回true。
结果 #2:调换位置以后,因为在进行字面量赋值(String s2 = “11″)的时候,常量池中不存在,所以s2指向的常量池中的位置,
而s1指向的是堆中的对象,再进行intern方法时,对s1和s2已经没有影响了,所以返回false。
测试代码:
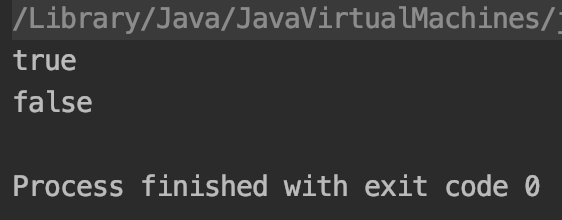
public static void test8_6_1(){ String s1=new StringBuilder("1").append("1").toString(); System.out.println(s1==s1.intern());//#1 } public static void test8_6_2(){ String s1=new StringBuilder("11").toString(); System.out.println(s1==s1.intern());//#2 }
测试结果:
原因分析:
结果#1 :
String s1 = new StringBuilder("1").append("1").toString();
System.out.println(s1==s1.intern());
上面的代码等价于下面的代码
String a = "1";
String b = "1";
String str3 = new StringBuilder(a).append(b).toString();
System.out.println(s1==s1.intern());
很容易分析出:
“11” 最先创建在堆中 s1.intern()然后缓存在字符串常连池中 运行结果为true.
结果#2:
String s1 = new StringBuilder("11").toString();
System.out.println(s1==s1.intern());
可以写成下面的形式
String a = "11";
String s1 = new StringBuilder(a).toString();
System.out.println(s1==s1.intern());
很容易分析出:
“11” 最先创建在常量池中, 运行结果为false.