很喜欢这个人总结的风格:https://www.cnblogs.com/yx-zhang/p/9572221.html,图画的也特别形象。
不要觉得画图麻烦,画图是最形象的,300文字不如一张图直观,直接找别人画的图也可以。
MapReduce原理如下图,流程顺序如下:
- 切片:数据逻辑上划分为多个split
- Map阶段:一个split对应一个map程序来处理,数据以kv对的形式传给map。
- Shuffle
- Map Shuffle:map程序执行完,结果会写进内存的环形缓冲区。缓冲区到一定比例后,先根据key和partition来排序,排序好开始溢写到磁盘上形成小文件。小文件再合并成大文件,最终形成一个多个partition聚合的大文件,partition内部是按照key有序排列的。
- Reduce Shuffle:通过网络传输将各Map节点输出的文件拷贝到内存缓冲区,相同partition的数据汇聚到一个reduce中。由于内存远小于这些文件,只要到达一定比例又会开始溢写到磁盘,同样地在溢写之前也会按key来排序。这些溢写的小文件重新由后台线程进行多次合并,最终形成一个有序的大文件。大文件形成kv形式,其中V值会生成一个迭代器供reduce程序使用。
- Reduce阶段:根据Shuffle阶段给的迭代器,reduce程序进行业务处理,生成kv结果输出给hdfs。
- combine:都发生在溢写到磁盘之前,可以对相同key的数据做一些合并。但只能做累加这种操作。
可以注意到Map和Reduce中的排序这种操作都是在内存中做的。

总结一个简单的版本:
数据split划分成kv--》map程序处理kv数据--》结果输出到内存缓冲区,一定比例开始溢写--》溢写前按key,partition排序--》开始溢写小文件到磁盘--》合并成包含多个partition,且每个partition内部按key有序的大文件--》通过网络传输将各Map节点的文件拷贝到内存中--》内存缓冲区一定比例开始溢写---》溢写前按key排序---》溢写小文件到磁盘,多次合并成大文件,期间保证key有序--》大文件依然是KV形式,将V值输出为迭代器供使用——》Reduce处理并输出kv结果给hdfs
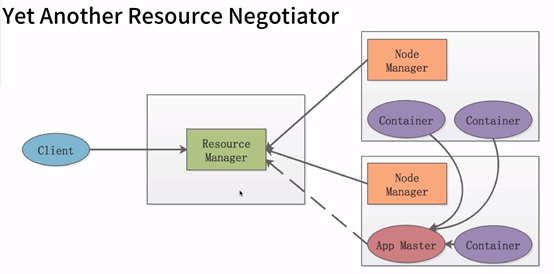
MapReduce在集群中运行,依赖于Yarn。Yarn原理如下:
- Resoruce Manager:只是清楚集群资源情况,负责协调资源,但不负责每个节点具体的事儿。
- Node Manager:每个节点有一个NodeManager,负责为应用程序创建APP Master、创建Container。当RM给他通知时,他来具体分配Container资源给AM。
- App Master:一个应用程序由一个App Master 来管理,App Master 负责将一个程序运行在各个节点的Container中。
- Container:内存 CPU资源抽象为Container
基于上面的关系,所以MapReduce on Yarn在集群运行的流程是:(https://www.cnblogs.com/yx-zhang/p/9572378.html)
1.客户端向RM提交请求,
——————————————————————————————————————————————
带着以下几个还不清楚的问题,去看mapreduce视频(一遍是看不懂的。而且不够明确):
1.要导入哪些依赖包
2.你能否独立写出wordcount程序
3.企业中一般怎么打包和测试这类程序