








基本去噪自编码器
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 显存自适应分配
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练
# 自编码器的数据相似性,使用手写数字集
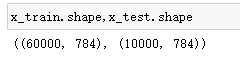
(x_train,y_train),(x_test,y_test) = tf.keras.datasets.mnist.load_data()

x_train = x_train.reshape(x_train.shape[0],-1)
x_test = x_test.reshape(x_test.shape[0],-1) #3维reshape成2维 -1的意思就是28*28
# 归一化
x_train = tf.cast(x_train,tf.float32)/255
x_test = tf.cast(x_test,tf.float32)/255
# 增加噪声
factor = 0.5 # 噪声系数
# 在x_train的基础上增加噪声数据 点与点相加 保证 形状不变
x_train_noise = x_train + factor*np.random.normal(size = x_train.shape)
x_test_noise = x_test + factor*np.random.normal(size = x_test.shape)
# 控制到0-1范围之间
x_train_noise = np.clip(x_train_noise,0.,1.)
x_test_noise = np.clip(x_test_noise,0.,1.)
n = 10
# 绘制增加噪声后的数据
plt.figure(figsize=(10,2))
for i in range(1,n):
ax = plt.subplot(1,n,i)
plt.imshow(x_train_noise[i].reshape(28,28))

# 输入784 压缩到长度32的向量 在还原输出784
input_size = 784
hidden_size = 32
output_size = 784
# 创建输入
input = tf.keras.layers.Input(shape=(input_size,)) # 输入的形状
# encode 编码
en = tf.keras.layers.Dense(hidden_size,activation="relu")(input) # 对输入形状进行编码为32长度向量
# decode 解码
de = tf.keras.layers.Dense(output_size,activation="sigmoid")(en) # 还原
# 创建模型
model = tf.keras.Model(inputs=input,outputs=de)
model.summary()

# 编译
model.compile(
optimizer="adam",
loss="mse"
)
# 训练
model.fit(x_train_noise,x_train, # 输入的是带噪声的图片 目标数据是原图
epochs=50, # 训练步数
batch_size = 256, # 每次训练256个数据
shuffle=True, # 乱序
validation_data=(x_test_noise,x_test)
)


# 使用
encode = tf.keras.Model(inputs=input,outputs=en) # 获取编码器
input_de = tf.keras.layers.Input(shape=(hidden_size,))
output_de = model.layers[-1](input_de)#从模型最后一层 0x262423e1940 调用input_de
decode = tf.keras.Model(inputs=input_de,outputs=output_de)
# 使用test进行测试
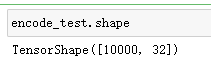
encode_test = encode(x_test_noise) # 使用encode去调用x_test_noise 得到编码后的test数据
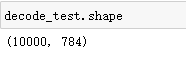
decode_test = decode.predict(encode_test) # 使用decode去调用test 得到解码后的test数据
x_test_noise = x_test.numpy() # 转换成numpy格式
# 绘图 10张图片
n = 10
plt.figure(figsize=(20,4)) # 画布长20宽4
for i in range(1,n): # 循环从1画到n
ax = plt.subplot(2,n,i) # 绘制此图,2行 n列 的第i张图片
plt.imshow(x_test_noise[i].reshape(28,28)) # 绘制第i张图片 reshape 成28*28的图片格式
ax = plt.subplot(2,n,i + n) # 绘制对应的图片 2行 n列 n+1个
plt.imshow(decode_test[i].reshape(28,28))

卷积去噪自编码器
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 显存自适应分配
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练
# 自编码器的数据相似性,使用手写数字集
(x_train,y_train),(x_test,y_test) = tf.keras.datasets.mnist.load_data()
x_train = np.expand_dims(x_train,-1)
x_test = np.expand_dims(x_test,-1) #3维变四维

# 归一化
x_train = tf.cast(x_train,tf.float32)/255
x_test = tf.cast(x_test,tf.float32)/255
# 增加噪声
factor = 0.5 # 噪声系数
# 在x_train的基础上增加噪声数据 点与点相加 保证 形状不变
x_train_noise = x_train + factor*np.random.normal(size = x_train.shape)
x_test_noise = x_test + factor*np.random.normal(size = x_test.shape)
# 控制到0-1范围之间
x_train_noise = np.clip(x_train_noise,0.,1.)
x_test_noise = np.clip(x_test_noise,0.,1.)
n = 10
# 绘制增加噪声后的数据
plt.figure(figsize=(10,2))
for i in range(1,n):
ax = plt.subplot(1,n,i)
plt.imshow(x_train_noise[i].reshape(28,28))
# 输入784 压缩到长度32的向量 在还原输出784
input_size = 784
hidden_size = 32
output_size = 784
# 创建输入
input = tf.keras.layers.Input(shape=x_train.shape[1:]) # 输入的形状
# encode 编码
x = tf.keras.layers.Conv2D(16,3,activation="relu",padding="same")(input)# 28*28*16
x = tf.keras.layers.MaxPooling2D(padding="same")(x) # 14*14*16
x = tf.keras.layers.Conv2D(32,3,activation="relu",padding="same")(x) # 14*14*32
x = tf.keras.layers.MaxPooling2D(padding="same")(x) # 7*7*32
# decode 解码
x = tf.keras.layers.Conv2DTranspose(16,3,strides=2,
activation="relu",
padding="same")(x) # 反卷积 14*14*16
x = tf.keras.layers.Conv2DTranspose(1,3,strides=2,
activation="sigmoid",
padding="same")(x) # 28*28*1
# 创建模型
model = tf.keras.Model(inputs=input,outputs=x)

# 编译
model.compile(
optimizer="adam",
loss="mse"
)
# 训练
model.fit(x_train_noise,x_train, # 输入的是带噪声的图片 目标数据是原图
epochs=50, # 训练步数
batch_size = 256, # 每次训练256个数据
shuffle=True, # 乱序
validation_data=(x_test_noise,x_test)
)

