作者:吴晓军
原文:https://zhuanlan.zhihu.com/p/27424282
模型验证(Validation)
在Test Data的标签未知的情况下,我们需要自己构造测试数据来验证模型的泛化能力,因此把Train Data分割成Train Set和Valid Set两部分,Train Set用于训练,Valid Set用于验证。
- 简单分割
将Train Data按一定方法分成两份,比如随机取其中70%的数据作为Train Set,剩下30%作为Valid Set,每次都固定地用这两份数据分别训练模型和验证模型。这种做法的缺点很明显,它没有用到整个训练数据,所以验证效果会有偏差。通常只会在训练数据很多,模型训练速度较慢的时候使用。
- 交叉验证
交叉验证是将整个训练数据随机分成K份,训练K个模型,每次取其中的K-1份作为Train Set,留出1份作为Valid Set,因此也叫做K-fold。至于这个K,你想取多少都可以,但一般选在3~10之间。我们可以用K个模型得分的mean和std,来评判模型得好坏(mean体现模型的能力,std体现模型是否容易过拟合),并且用K-fold的验证结果通常会比较可靠。
如果数据出现Label不均衡情况,可以使用Stratified K-fold,这样得到的Train Set和Test Set的Label比例是大致相同。
模型集成(Ensemble)
曾经听过一句话,”Feature为主,Ensemble为后”。Feature决定了模型效果的上限,而Ensemble就是让你更接近这个上限。Ensemble讲究“好而不同”,不同是指模型的学习到的侧重面不一样。举个直观的例子,比如数学考试,A的函数题做的比B好,B的几何题做的比A好,那么他们合作完成的分数通常比他们各自单独完成的要高。
常见的Ensemble方法有Bagging、Boosting、Stacking、Blending。
Bagging
Bagging是将多个模型(基学习器)的预测结果简单地加权平均或者投票。Bagging的好处在于可以并行地训练基学习器,其中Random Forest就用到了Bagging的思想。举个通俗的例子,如下图:
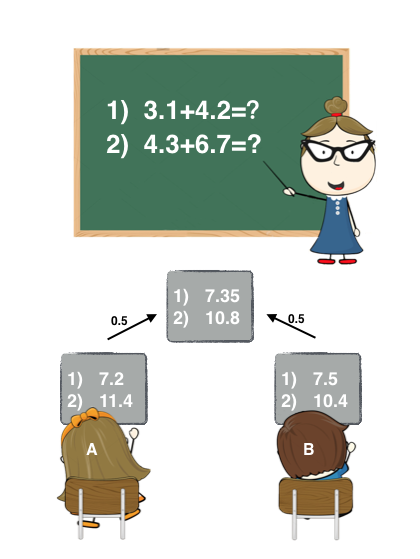
老师出了两道加法题,A同学和B同学答案的加权要比A和B各自回答的要精确。
Bagging通常是没有一个明确的优化目标的,但是有一种叫Bagging Ensemble Selection的方法,它通过贪婪算法来Bagging多个模型来优化目标值。在这次比赛中,我们也使用了这种方法。
Boosting
Boosting的思想有点像知错能改,每训练一个基学习器,是为了弥补上一个基学习器所犯的错误。其中著名的算法有AdaBoost,Gradient Boost。Gradient Boost Tree就用到了这种思想。
我在1.2.3节(错误分析)中提到Boosting,错误分析->抽取特征->训练模型->错误分析,这个过程就跟Boosting很相似。
Stacking
Stacking是用新的模型(次学习器)去学习怎么组合那些基学习器,它的思想源自于Stacked Generalization这篇论文。如果把Bagging看作是多个基分类器的线性组合,那么Stacking就是多个基分类器的非线性组合。Stacking可以很灵活,它可以将学习器一层一层地堆砌起来,形成一个网状的结构,如下图:
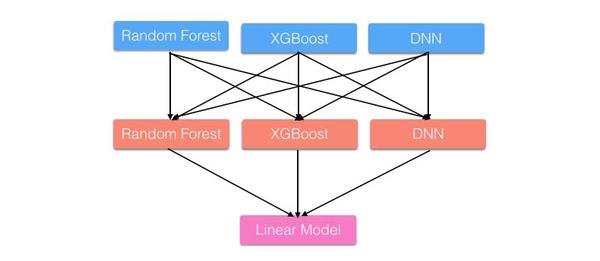
举个更直观的例子,还是那两道加法题:
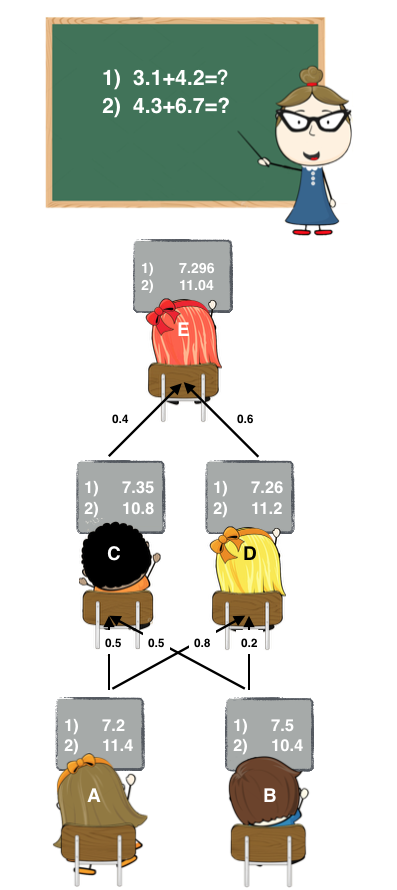
这里A和B可以看作是基学习器,C、D、E都是次学习器。
- Stage1: A和B各自写出了答案。
- Stage2: C和D偷看了A和B的答案,C认为A和B一样聪明,D认为A比B聪明一点。他们各自结合了A和B的答案后,给出了自己的答案。
- Stage3: E偷看了C和D的答案,E认为D比C聪明,随后E也给出自己的答案作为最终答案。
在实现Stacking时,要注意的一点是,避免标签泄漏(Label Leak)。在训练次学习器时,需要上一层学习器对Train Data的测试结果作为特征。如果我们在Train Data上训练,然后在Train Data上预测,就会造成Label Leak。为了避免Label Leak,需要对每个学习器使用K-fold,将K个模型对Valid Set的预测结果拼起来,作为下一层学习器的输入。如下图:

由图可知,我们还需要对Test Data做预测。这里有两种选择,可以将K个模型对Test Data的预测结果求平均,也可以用所有的Train Data重新训练一个新模型来预测Test Data。所以在实现过程中,我们最好把每个学习器对Train Data和对Test Data的测试结果都保存下来,方便训练和预测。
对于Stacking还要注意一点,固定K-fold可以尽量避免Valid Set过拟合,也就是全局共用一份K-fold,如果是团队合作,组员之间也是共用一份K-fold。如果想具体了解为什么需要固定K-fold,请看这里。