一、n-gram-model
谈到词向量则必须要从语言模型讲起,传统的统计语言模型是对于给定长度为m的句子,计算其概率分布P(w1, w2, ..., wm),以表示该句子存在的可能性。该概率可由下列公式计算得到:
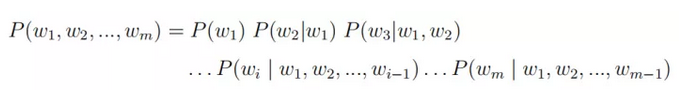
但实际过程中句子的长度稍长便会为估计带来很大难度,因此n-gram 模型对上述计算进行简化:假定第i个词的出现仅与其前n-1个词有关,即:
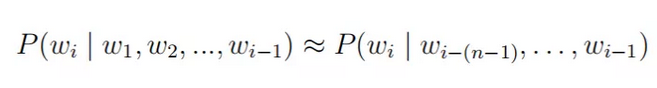
实际计算中,通常采用n元短语在语料中出现的频率来估计其概率:

为保留句子原有的顺序信息,我们当然希望n越大越好,但实际上当n略大时,该n元短语在语料中出现的频率就会越低,用上式估计得到的概率就容易出现数据稀疏的问题。而神经网络语言模型的出现,有效地解决了这个问题。
二、Neural Network Language Model(NNLM)
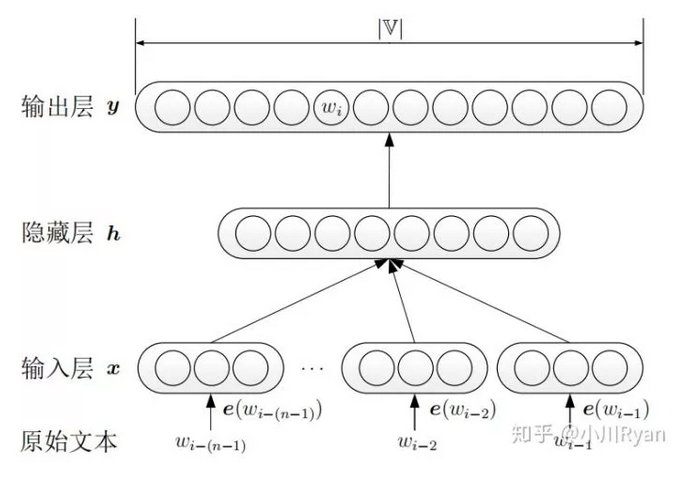
神经网络语言模型不使用频率来估计n元短语出现的概率,而是通过神经网络训练得到一个语言模型,所以会有如下优势:

首先将原始文本进行one-hot编码,在分别乘以词嵌入矩阵,得到每个词的词向量表示,拼接起来作为输入层。输出层后加上softmax,将y转换为对应的概率值。模型采用随机梯度下降对
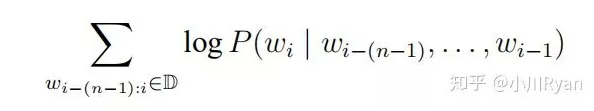
进行最大化。
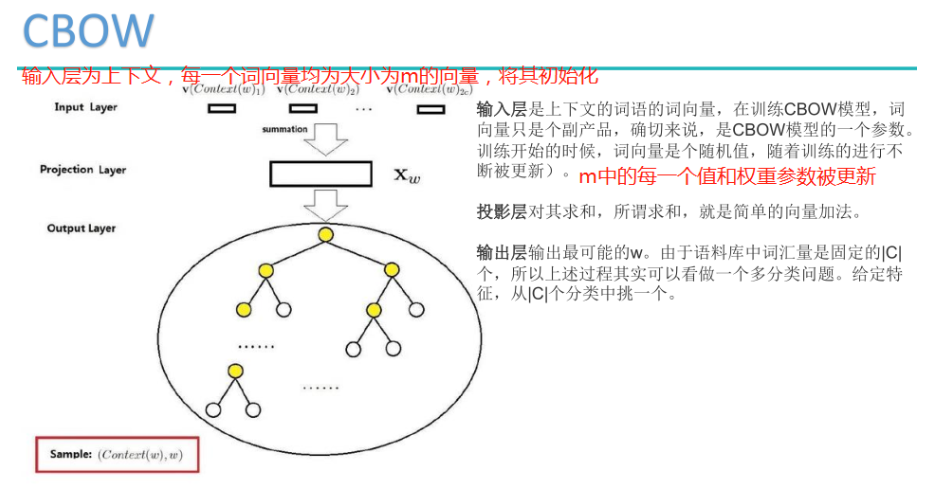
三、CBOW(continous Bag of words)
CBOW的主要思想是将一句话中的某个词挖去,用其上下文对其进行预测,输出的时候是一个哈夫曼树,或者称之为分层softmax,采用的也是随机梯度下降法进行优化。
四、CBOW的优化-Hierarchical Softmax
为什么要用Hierarchical Softmax?
未优化的CBOW和Skip-gram中,输出层后采用一般的softmax层,在预测每个词的概率时都要累加一次分母的归一化项,而指数计算的复杂度又比较高,因此一旦词典的规模比较大,预测的效率将会极其低下。

Hierarchical Softmax首先以词典中的每个词在语料中出现的次数(或频率)为权重,构建一棵哈夫曼树,叶子节点为词典中的每个词的one-hot表示,每个非叶子结点也表示为一个向量。此时,从根节点到每一个叶子节点的路径都可以由一串哈夫曼编码来表示,如假设向左结点为0,向右结点为1,上图中的“cat”就可以表示为01.
在预测过程中,每一个非叶子结点都用自身的向量表示来做一次二分类(如使用逻辑回归),分类的结果便导向其是去到左结点还是右结点,这样一来,预测为"cat"的概率就可表示为P(结点1==0)*P(结点5==1)了,更复杂的树结构也以此类推。此法在预测某一个特定的词的概率时就只需考虑从根节点到该叶子结点这几步了,从O(V)级别降到O(log(v)),使预测的效率大大提升

原始模型需要计算

由于使用的是softmax()函数,时间复杂度为 O(|V|),因此计算代价很大,对大规模的训练语料来说,非常不切实际的。
Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。Huffman树是二叉树,在叶子节点及叶子节点的权给定的情况下,该树的带权路径长度最短(一个节点的带权路径长度指根节点到该节点的路径长度乘以该节点的权,树的带权路径长度指全部叶子节点的带权路径长度之和)。
直观上可以看出,叶子节点的权越大,则该叶子节点就应该离根节点越近。因此对于模型来说就是,词频越高的词,距离根节点就越近。从根节点出发,到达指定叶子节点的路径是唯一的。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。改成树结构后,平均时间复杂度为 O(log|V|) ,相比于使用softmax()函数有很大提高。
五、Negative Sampling 负采样
负采样的目的依然是为改善在预测每一个词的概率时,普通softmax需要累加一次归一化项带来的高计算成本问题,其核心思想是将对每一个词概率的预测都转化为小规模的监督学习问题。具体地,对于语料中的某个句子,如“I want a glass of orange juice to go along with my cereal.”选取"orange"为上文,然后把预测为"juice"标记为1(即正样本),再选取句子中的k个其他词为负样本,假如k=4,就像这样:

再将采样到的这些样本用来训练一个逻辑回归模型。这样一来,在预测"orange"一词下文出现的词的概率时,尽管还是需要迭代比较多次来看哪个词的概率最大,但在每次迭代时,计算softmax时:
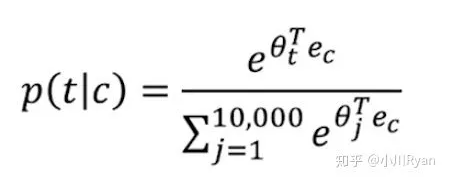
分母的归一化项就不用再像上式这样累加词典中所有的词,仅需要累加采样到的5个词就好了,同样大大地提高了训练效率。至于k的选取,Mikolov的论文中提及对于规模比较小的语料,k一般选在5到20之间,规模较大则控制在5以内。
关键是如何采样?
