简介
SQLAlchemy的组件架构图
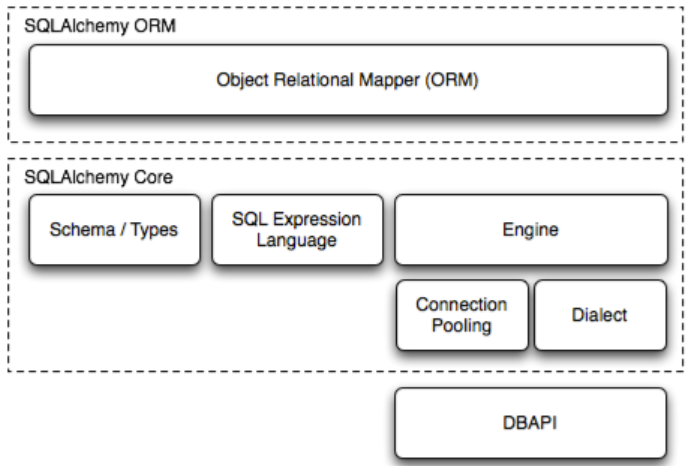
上面,SQLAlchemy的两个最重要的前端部分是对象关系映射器(ORM)和 Core。
Core包含SQLAlchemy的SQL和数据库集成与描述服务的广度,其中最突出的部分是SQL Expression Language。
SQL Expression Language: (SQL表达式语言)是一个完全独立于ORM软件包的工具包,它提供了一个构建由可组合对象表示的SQL表达式的系统,然后可以针对特定事务范围内的目标数据库“执行”该SQL表达式,并返回结果集。插入,更新和删除(即DML)是通过传递表示这些语句的SQL表达式对象以及表示每个语句要使用的参数的字典来实现的
ORM: 建立在Core之上,提供了一种使用映射到数据库模式的域对象模型的方法。使用ORM时,SQL语句的构建方式与使用Core时几乎相同,但是DML的任务(此处指数据库中业务对象的持久性)是通过称为工作单元的模式自动进行的,该模式可转换为将可变对象的状态更改为INSERT,UPDATE和DELETE构造,然后根据这些对象调用它们。SELECT语句还通过特定于ORM的自动化和以对象为中心的查询功能得到了增强。
安装
pip install sqlalchemy
查看版本
import sqlalchemy
print(sqlalchemy.__version__)
# 返回
1.4.11
创建连接引擎
from sqlalchemy import create_engine
engine = create_engine('数据库+数据库驱动://数据库地址, echo=True, future=True)
- echo: 该参数将指示,
Engine以将它发出的所有SQL记录到Python记录器中,并记录到标准输出中。 - future: 设置为True以便我们能使用到2.0版本的用法
- 目前SQLAlchemy为1.4版本, 该版本是一个1.x版本到将来2.0版本的过渡版本, 因此引入了2.0版本的大部分用法, 在具体的API使用时, 我们可以选择是否使用2.0版本的用法, 将
future设置为True则认为使用2.0版本的新用法.
创建内存中的SQLite数据库连接
from sqlalchemy import create_engine
engine = create_engine('sqlite+pysqlite:///:memory:', echo=True, future=True)
创建mysql数据库连接
sqlalchemy支持多种python连接mysql的驱动, 如MySQLdb , mysqlclient, pymysql, aiomysql 等, 默认为MySQLdb, 这里使用pymysql
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://user:password@ip/db_name', echo=True)
直接执行sql语句
创建表, 插入数据
from sqlalchemy import create_engine
from sqlalchemy import text
from sqlalchemy.orm import Session
engine = create_engine("mysql+pymysql://root:xx@xx/test_db", encoding='utf-8', echo=True)
with Session(engine) as session:
# 执行sql语句, 创建表
session.execute(text('create table some_table(x int, y int)'))
# 插入一条数据
session.execute(text('insert into some_table values (1, 2)'))
# 执行时添加参数, 插入多条数据
session.execute(text('insert into some_table values (:a, :b)'), [{'a': 2, 'b': 4}, {'a': 3, 'b': 6}])
# 提交
session.commit()
# 打印
sqlalchemy.engine.Engine SHOW VARIABLES LIKE 'sql_mode'
sqlalchemy.engine.Engine [raw sql] {}
sqlalchemy.engine.Engine SHOW VARIABLES LIKE 'lower_case_table_names'
sqlalchemy.engine.Engine [generated in 0.00073s] {}
sqlalchemy.engine.Engine SELECT DATABASE()
sqlalchemy.engine.Engine [raw sql] {}
sqlalchemy.engine.Engine BEGIN (implicit)
sqlalchemy.engine.Engine create table some_table(x int, y int)
sqlalchemy.engine.Engine [generated in 0.00047s] {}
sqlalchemy.engine.Engine insert into some_table values (1, 2)
sqlalchemy.engine.Engine [generated in 0.00059s] {}
sqlalchemy.engine.Engine insert into some_table values (%(a)s, %(b)s)
sqlalchemy.engine.Engine [generated in 0.00058s] ({'a': 2, 'b': 4}, {'a': 3, 'b': 6})
sqlalchemy.engine.Engine COMMIT
查询
from sqlalchemy import create_engine
from sqlalchemy import text
from sqlalchemy.orm import Session
engine = create_engine("mysql+pymysql://root:xx@xx/test_db", encoding='utf-8', echo=True)
with Session(engine) as session:
# 查询
result = session.execute(text('select * from some_table'))
print(result, type(result))
# 打印
sqlalchemy.engine.Engine BEGIN (implicit)
sqlalchemy.engine.Engine select * from some_table
sqlalchemy.engine.Engine [generated in 0.00011s] {}
<sqlalchemy.engine.cursor.CursorResult object at 0x7fb665252f70> <class 'sqlalchemy.engine.cursor.CursorResult'>
sqlalchemy.engine.Engine ROLLBACK
查询结果result类似生成器, 只能遍历一遍, 遍历第二遍时就是空数据
-
- 通过
result.all()获取所有结果, 返回一个列表
- 通过
print(result.all(), type(result.all()))
# 打印[(1, 2), (2, 4), (3, 6)] <class 'list'>
-
- 通过for循环遍历结果, 同时进行元祖拆包赋值
for x, y in result:
print(x, y)
-
- 通过普通for循环遍历结果, 每条记录row类似具名元祖(
namedtuple), 可以通过下列三种方式访问字段(具名元祖的属性不能通过下面的映射方式访问, 可以通过其他两种方式访问)
- 通过普通for循环遍历结果, 每条记录row类似具名元祖(
for row in result:
print(row, type(row))
print('3.1. 通过索引下标获取字段值')
print(row[0], row[1])
print('3.2. 通过属性名称获取字段值')
print(row.x, row.y)
print('3.3. 通过map映射获取字段值')
print(row['x'], row['y'])# 打印(1, 2) <class 'sqlalchemy.engine.row.Row'>
3.1. 通过索引下标获取字段值
1 2
3.2. 通过属性名称获取字段值
1 2
3.3. 通过map映射获取字段值
1 2
在语句中绑定参数: bindparams
stmt = text('select * from some_table where y>:y order by x, y').bindparams(y=3)
with Session(engine) as session:
result = session.execute(stmt)
for x, y in result:
print(x, y)
# 打印
sqlalchemy.engine.Engine BEGIN (implicit)
sqlalchemy.engine.Engine select * from some_table where y>%(y)s order by x, y
sqlalchemy.engine.Engine [generated in 0.00050s] {'y': 3}
2 4
3 6
使用ORM
创建-表模型类
1.设置注册表
SQLAlchemy的表需要存放在MetaData集合中, 在SQLAlchemy的CORE中通过MetaData定义实例
from sqlalchemy import MetaData
metadata = MetaData()
在SQLAlchemy的ORM中通过注册registry对象定义, 在registry对象中包含了MetaData对象
from sqlalchemy.orm import registry
mapper_registry = registry()
# 在mapper_registry中可以查看MetaData
print(mapper_registry.metadata)
2.创建表模型基类
Base = mapper_registry.generate_base()
3.定义表模型类
from sqlalchemy import Column, String, Integer, ForeignKey
from sqlalchemy.orm import relationship
class User(Base):
"""用户表模型类"""
# 表名
__tablename__ = 'user_account'
# 表字段
id = Column(Integer, primary_key=True)
name = Column(String(30))
fullname = Column(String(50))
# 关系字段(ORM专用属性), 里面的模型名和字段名需要和对应关系表中定义一致
addresses = relationship('Address', back_populates='user')
def __repr__(self):
return f"User=(id={self.id!r}, name={self.name!r}, fullname={self.fullname!r})"
class Address(Base):
"""地址表模型类"""
# 表名
__tablename__ = 'address'
# 表字段
id = Column(Integer, primary_key=True)
email = Column(String(30), nullable=True)
user_id = Column(Integer, ForeignKey('user_account.id'))
# 关系字段(ORM专用属性), 里面的模型名和字段名需要和对应关系表中定义一致
user = relationship('User', back_populates="addresses")
def __repr__(self):
return f"Address=(id={self.id!r}, email={self.email!r})"
4.迁移至数据库
mapper_registry.metadata.create_all(engine)
插入-通过模型类实例
1.实例化类, 创建数据行对象
# 实例化类, 手动传入参数
ming = User(name='ming', fullname='xiao ming')
# 通过字段拆包方式传递参数
hong_dict = {'name': 'hong', 'fullname': 'xiao hong'}
hong = User(**hong_dict)
print(ming)
print(hong)
# 打印结果
User=(id=None, name='ming', fullname='xiao ming')
User=(id=None, name='hong', fullname='xiao hong')
2.add将实例添加到session中
with Session(engine) as session:
# 将实例添加到session中
session.add(ming)
session.add(hong)
# 查看session中新添加的对象
print('查看session中新添加的对象')
print(session.new)
# 打印结果
查看session中新添加的对象
IdentitySet([User=(id=None, name='ming', fullname='xiao ming'), User=(id=None, name='hong', fullname='xiao hong')])
3.flush写入数据库(可选)
这一步是可选的, 可以不手动执行, 当调用session.commit时会自动执行刷新
# flush写入数据库
print('flush写入数据库')
session.flush()
# 再次查看new发现IdentitySet已经清空了
print('再次查看new发现IdentitySet已经清空了')
print(session.new)
# 再次查看实例对象, 已经自动生成了id
print('再次查看实例对象, 已经自动生成了id')
print(ming)
print(hong)
# 打印结果
flush写入数据库
BEGIN (implicit)
sqlalchemy.engine.Engine INSERT INTO user_account (name, fullname) VALUES (%(name)s, %(fullname)s)
sqlalchemy.engine.Engine [generated in 0.00027s] {'name': 'ming', 'fullname': 'xiao ming'}
sqlalchemy.engine.Engine INSERT INTO user_account (name, fullname) VALUES (%(name)s, %(fullname)s)
sqlalchemy.engine.Engine [cached since 0.009322s ago] {'name': 'hong', 'fullname': 'xiao hong'}
再次查看new发现IdentitySet已经清空了
IdentitySet([])
再次查看实例对象, 已经自动生成了id
User=(id=9, name='ming', fullname='xiao ming')
User=(id=10, name='hong', fullname='xiao hong')
此时数据还没有正式写入数据库中, 需要进行提交
4.提交会话
# 提交
print('提交')
session.commit()
# 打印结果
提交
2021-05-02 17:35:14,200 INFO sqlalchemy.engine.Engine COMMIT
更新
通过单个模型类实例更新
from sqlalchemy import select
# 查询一条数据
with Session(engine) as session:
hua = session.execute(select(User).filter_by(name='hua')).scalar_one()
print('查询结果')
print(hua)
print('修改fullname字段')
hua.fullname = 'da hua'
print('修改后, 会在session.dirty中记录, 标记这条记录是"脏"的')
print(hua in session.dirty)
print('提交')
session.commit()
print('再次查看是否是dirty')
print(hua in session.dirty)
# 返回结果
sqlalchemy.engine.Engine BEGIN (implicit)
sqlalchemy.engine.Engine SELECT user_account.id, user_account.name, user_account.fullname FROM user_account WHERE user_account.name = %(name_1)s
sqlalchemy.engine.Engine [generated in 0.00018s] {'name_1': 'hua'}
查询结果
User=(id=11, name='hua', fullname='xiao hua')
修改fullname字段
修改后, 会在session.dirty中记录, 标记这条记录是"脏"的
True
提交
sqlalchemy.engine.Engine UPDATE user_account SET fullname=%(fullname)s WHERE user_account.id = %(user_account_id)s
sqlalchemy.engine.Engine [generated in 0.00021s] {'fullname': 'da hua', 'user_account_id': 11}
sqlalchemy.engine.Engine COMMIT
再次查看是否是dirty
False
通过update语句更新
from sqlalchemy import update
with Session(engine) as session:
session.execute(update(User).where(User.name == 'ming').values(fullname='da ming'))
session.commit()
删除
通过单个模型类实例删除
from sqlalchemy import select
with Session(engine) as session:
hua = session.get(User, 11)
session.delete(hua)
session.commit()
# 返回结果
BEGIN (implicit)
sqlalchemy.engine.Engine SELECT user_account.id AS user_account_id, user_account.name AS user_account_name, user_account.fullname AS user_account_fullname FROM user_account WHERE user_account.id = %(pk_1)s
sqlalchemy.engine.Engine [generated in 0.00017s] {'pk_1': 11}
sqlalchemy.engine.Engine SELECT address.id AS address_id, address.email AS address_email, address.user_id AS address_user_id FROM address WHERE %(param_1)s = address.user_id
sqlalchemy.engine.Engine [generated in 0.00017s] {'param_1': 11}
sqlalchemy.engine.Engine DELETE FROM user_account WHERE user_account.id = %(id)
ssqlalchemy.engine.Engine [generated in 0.00017s] {'id': 11}
sqlalchemy.engine.Engine COMMIT
通过delete语句删除
from sqlalchemy import delete
with Session(engine) as session:
session.execute(delete(User).where(User.name == 'hua'))
session.commit()
查询
select
字段别名 label
stmt_1 = select(('user_name:' + User.name).label('user_name'), User.fullname.label('fullname')).order_by(User.name)
# 对应sql
SELECT :name_1 || user_account.name AS user_name, user_account.fullname AS fullname FROM user_account ORDER BY user_account.name
查询整张表所有字段和查询表中指定字段的区别
print('1. 查询整张表字段')
stmt_1 = select(User)
print(stmt_1)
print('2. 查询表的指定字段name和fullname')
stmt_2 = select(User.name, User.fullname)
print(stmt_2)
with Session(engine) as session:
row = session.execute(stmt_1).first()
print('查询整张表字段的返回结果')
print(row)
print(row[0])
print(row[0].name, row[0].fullname)
row = session.execute(stmt_2).first()
print('查询指定字段name和fullname的返回结果')
print(row) print(row.name, row.fullname)
print('3. 两种方式一起使用')
stmt_3 = select(User.name, Address).where(User.id == Address.user_id).where(User.name == 'gang')
print(stmt_3)
row = session.execute(stmt_3).first()
print(row)
# 打印结果
1. 查询整张表字段
SELECT user_account.id, user_account.name, user_account.fullname FROM user_account
2. 查询表的指定字段name和fullname
SELECT user_account.name, user_account.fullname FROM user_account
......
查询整张表的返回结果
(User=(id=9, name='ming', fullname='da ming'),)
User=(id=9, name='ming', fullname='da ming')
name:ming, fullname:da ming
......
查询指定字段name和fullname的返回结果
('ming', 'da ming')
name:ming, fullname:da ming
3. 两种方式一起使用
SELECT user_account.name, address.id, address.email, address.user_id FROM user_account, address WHERE user_account.id = address.user_id AND user_account.name = :name_1
......
('gang', Address=(id=1, email='123@qq.com'))
可以看到在查询整张表字段中, 返回的是一个只有一个元素的元祖(User=(id=9, name='ming', fullname='da ming'),), 这个元祖的第一个元素是整个User对象
而查询指定字段中, 返回的是由所查询字段组成的元祖('ming', 'da ming')
即可以理解为查询整张表字段的返回结果需要取第一个元素[0]才能拿到数据行对象, 而查询指定字段的返回结果本身就是数据行对象
查询结果获取方式
统一实例:
from sqlalchemy import create_engine
sync_engine = create_engine('mysql+pymysql://root:alex-gcx@47.102.114.90/cy_account', echo=True, future=True)
with Session(sync_engine) as session:
stmt = select(User).where(User.user_name.ilike('user1%'))
result = session.execute(stmt)
# all() 获取全部数据, 返回列表, 每个元素是Row对象, row对象是一个元组, 第一个元素是模型类对象User
for row in result.all():
print(type(row))
# <class 'sqlalchemy.engine.row.Row'>
print(row)
# (< models.users.User object at 0x7f9b0ee7c910 >,)
print(type(row[0]))
# <class 'models.users.User'>
print(row[0])
# <models.users.User object at 0x7fca5562bac0>
# first() 获取第一条数据, 返回Row对象, row对象是一个元组, 第一个元素是模型类对象User
row = result.first()
print(type(row))
# <class 'sqlalchemy.engine.row.Row'>
print(row)
# (< models.users.User object at 0x7fd184332130 >,)
print(type(row[0]))
# <class 'models.users.User'>
print(row[0])
# <models.users.User object at 0x7fca5562bac0>
# one() 获取一条数据, 返回Row对象, row对象是一个元组, 第一个元素是模型类对象User
# 当没有数据或者有多条数据时, 抛出异常NoResultFound或MultipleResultsFound
row = result.one()
print(type(row))
print(row)
# scalars() 返回ScalarResult对象, 可以进行for循环遍历, 每个元素是模型类对象User
# scalars().all() 返回模型类列表, 可以进行for循环遍历, 每个元素是模型类对象User
for row in result.scalars():
print(type(row))
# <class 'models.users.User'>
print(row)
# < models.users.User object at 0x7f4ac5930910 >
# scalars().first() 返回第一个模型类对象
row = result.scalars().first()
print(type(row))
# <class 'models.users.User'>
print(row)
# < models.users.User object at 0x7f4ac5930910 >
# scalar_one() 返回一个模型类对象
# 当没有数据或者有多条数据时, 抛出异常NoResultFound或MultipleResultsFound
row = result.scalar_one()
print(type(row))
print(row)
# 查询部分字段, 返回row对象
stmt = select(User.user_name, User.user_id).where(User.user_name.ilike('user%'))
result = session.execute(stmt)
row = result.first()
print(type(row))
# <class 'sqlalchemy.engine.row.Row'>
print(row)
# ('user1_test', 1)
print('1. Row对象可以通过索引下标获取字段值')
print(row[0], row[1])
print('2. Row对象可以通过属性名称获取字段值')
print(row.user_name, row.user_id)
print('3. Row对象可以通过map映射获取字段值')
print(row['user_name'], row['user_id'])
# scalars() 返回ScalarResult对象, 可以进行for循环遍历, 但每个元素是select字段的第一个字段的类型
for row in result.scalars():
print(type(row))
print(row)
- all() : 获取全部数据, 返回列表, 每个元素是
Row对象,row对象是一个元组, 第一个元素是模型类对象User - first(): 获取第一条数据, 返回
Row对象,row对象是一个元组, 第一个元素是模型类对象User - one(): 获取一条数据, 返回
Row对象,row对象是一个元组, 第一个元素是模型类对象User, 当没有数据或者有多条数据时, 抛出异常NoResultFound或MultipleResultsFound - scalars(): 返回
ScalarResult对象, 可以进行for循环遍历, 每个元素是模型类对象User - scalars().all() : 返回模型类列表, 可以进行for循环遍历, 每个元素是模型类对象User
- scalars().first(): 返回第一个模型类对象
- scalar(): 返回第一个模型类对象(同scalars().first())
- scalar_one(): 返回一个模型类对象, 当没有数据或者有多条数据时, 抛出异常
NoResultFound或MultipleResultsFound
注: 当查询指定字段时, 如果使用scalar, 那么得到的对象是select字段的第一个字段的类型, 获取不到其他所查询的字段, 所以这时不推荐使用scalar
where
多个where条件
# 第一种. 多次调用where
stmt = select(User).where(User.name == 'gang').where(User.fullname == 'xiao gang')
# 第二种. 同时接收多个表达式
stmt = select(User).where(User.name == 'gang', User.fullname == 'xiao gang')
# 第三种. 使用and_()和or_()
stmt = select(User).where(or_(User.name == 'gang', and_(User.name == 'ming', User.fullname == 'xiao ming')))
# stmt对应sql
SELECT user_account.id, user_account.name, user_account.fullname FROM user_account
WHERE user_account.name = :name_1 OR user_account.name = :name_2 AND
user_account.fullname = :fullname_1
filter_by
为了对单个实体进行简单的“相等”比较,还有一种流行的方法,Select.filter_by()该方法接受与列键或ORM属性名称匹配的关键字参数。它将针对最左边的FROM子句或最后加入的实体进行过滤:
stmt = select(User).filter_by(name='gang', fullname='xiao gang')
比较运算符
# 等于==
User.id == 5
# 不等于!=
User.id != 5
# 大于>
User.id > 5
# 大于等于>=
User.id >= 5
# 小于<
User.id < 5
# 小于等于<=
User.id <= 5
in
# in
User.id.in_([1, 2, 3])
# 空列表也有效
User.id.in_([])
# not_in
User.id.not_in([1, 2, 3])
# 空列表也有效
User.id.not_in([])
# 元组in(多字段同时in)
from sqlalchemy import tuple_
tup = tuple_(User.name, User.fullname)
stmt = select(User).where(tup.in_([('ming', 'xiao ming'), ('gang', 'xiao gang')]))
# 对应sql
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE (user_account.name, user_account.fullname) IN ([POSTCOMPILE_param_1])
# 子查询in
stmt = select(Address).where(Address.user_id.in_(select(User.id)))
# 对应sql
SELECT address.id, address.email, address.user_id
FROM address
WHERE address.user_id IN (SELECT user_account.id FROM user_account)
is
# 显示调用is_, 一般与None或者null()一起使用
stmt = select(User).where(User.id.is_(None))
from sqlalchemy import null
stmt = select(User).where(User.id.is_(null()))
# 当==与None或null()一起使用时, 会自动调用is_
a = None
stmt = select(User).where(User.id == a)
# 对应sql
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE user_account.id IS NULL
# is_not用法同is_
stmt = select(User).where(User.id.is_not(None))
# 对应sql
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE user_account.id IS NOT NULL
like
# like
stmt = select(User).where(User.name.like('%ng%'))
# ilike不区分大小写的like(会把两边的字段都转为小写)
stmt = select(User).where(User.name.ilike('%NG%'))
# 对应sql
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE lower(user_account.name) LIKE lower(:name_1)
# notlike
stmt = select(User).where(User.name.notlike('%ng%'))
# notilike不区分大小写的notlike(会把两边的字段都转为小写)
stmt = select(User).where(User.name.notilike('%NG%'))
字符串包含
最终会转换为like和||的配合使用
# startswith, 以...开头
stmt = select(User).where(User.fullname.startswith('xiao'))
# 对应sql
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE (user_account.fullname LIKE :fullname_1 || '%')
# endswith, 以...结尾
stmt = select(User).where(User.fullname.endswith('ng'))
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE (user_account.fullname LIKE '%' || :fullname_1)
# contains, 包含...
stmt = select(User).where(User.fullname.contains('n'))
# 对应sql
SELECT user_account.id, user_account.name, user_account.fullname
FROM user_account
WHERE (user_account.fullname LIKE '%' || :fullname_1 || '%')
from
- 通常, SQLAlchemy能够从
select的字段中推断出具体from哪张表, 如
stmt = select(User)
- 而如果同时
select了两张表的字段, 那么将得到一个逗号分隔的FROM子句
stmt = select(User.name, Address.email)
# 对应sql
SELECT user_account.name, address.email
FROM user_account, address
-
这个时候由于没有表关联关系, 所以会出现笛卡尔积的情况, 因此需要加上两表的关联
-
第一种方法是: 通过
join_from()加上关联, 它使我们可以明确指定JOIN的左侧和右侧, 若设置了外键, 则会自动加上on的字段关联关系
stmt = select(User.name, Address.email).join_from(User, Address)
# 对应sql
SELECT user_account.name, address.email
FROM user_account JOIN address ON user_account.id = address.user_id
- 第二种方法是: 通过
join()加上关联, 它仅指定JOIN的右侧,而推断出左侧, 若设置了外键, 则会自动加上on的字段关联关系
stmt = select(Address.email, User.name).join(User)
# 对应sql(可以看到Address在join左侧,User在右侧)
SELECT address.email, user_account.name
FROM address JOIN user_account ON user_account.id = address.user_id
- 当
join()无法推断时, 也可以再加上select_from()显式指定join左侧
stmt = select(Address.email).select_from(User).join(Address)
# 对应sql
SELECT address.email
FROM user_account JOIN address ON user_account.id = address.user_id
select_from()还有一个用法是, 当select中的字段不是表字段时, 无法推断from的表是什么, 就可以用select_from()显式指定表
from sqlalchemy import func
stmt = select(func.count('*')).select_from(User)
# 对应sql
SELECT count(:count_2) AS count_1 FROM user_account
- 手动设置on字句
前面JOIN的示例说明了Select构造可以在两个表之间进行联接并自动产生ON子句。
如果联接的左目标和右目标没有这样的约束,或者存在多个约束,则需要直接指定ON子句。
可以使用select_from与join联合使用
stmt = select(User.name, Address.email).select_from(User).join(Address, User.id == Address.user_id)
# 对应sql
SELECT user_account.name, address.email
FROM user_account JOIN address ON user_account.id = address.user_id
# 外连接
stmt = select(User.name, Address.email).join(Address, isouter=True)
# 对应sql(left join, 左边的User是主表,右边的Address是外表, 会把主表user的数据全部取出来)
SELECT user_account.name, address.email
FROM user_account LEFT OUTER JOIN address ON user_account.id = address.user_id
# 返回结果
('ming', 'ming@163.com')
('ming', 'ming@qq.com')
('hong', None)
('gang', '123@163.com')
('gang', '123@qq.com')
注: SQL还具有RIGHT OUTER JOIN。SQLAlchemy不会直接实现它;相反,请颠倒表格的顺序,然后使用LEFT OUTER JOIN。
order by
# 正序
stmt = select(User).order_by(User.name)
# 倒序
stmt = select(User).order_by(User.name.desc())
group by/having
表数据:
user_account表
| id | name | fullname |
|---|---|---|
| 9 | ming | da ming |
| 10 | hong | xiao hong |
| 13 | gang | xiao gang |
address表
| id | user_id | |
|---|---|---|
| 1 | gang@qq.com | 13 |
| 2 | gang@163.com | 13 |
| 3 | ming@qq.com | 9 |
| 4 | ming@163.com | 9 |
可以看到用户ming有两条address, 用户gang有两条address, 用户hong没有address
# group by
# 查询每个用户对应地址数
stmt = select(User.name, func.count(Address.id).label('count')).join(Address, isouter=True).group_by(User.name)
# 对应sql
SELECT user_account.name, count(address.id) AS count
FROM user_account LEFT OUTER JOIN address ON user_account.id = address.user_id GROUP BY user_account.name
# 查询结果(每个用户的数量都计算出来了, 包括hong)
('ming', 2)
('hong', 0)
('gang', 2)
# having
# 查询地址数大于1的用户, having
stmt = select(User.name, func.count(Address.id).label('count')).join(Address, isouter=True).group_by(User.name).having(func.count(Address.id) > 1)
# 对应sql
SELECT user_account.name, count(address.id) AS count
FROM user_account LEFT OUTER JOIN address ON user_account.id = address.user_id
GROUP BY user_account.name HAVING count(address.id) > :count_1
# 查询结果
('ming', 2)
('gang', 2)
直接使用字段别名进行group by或者order by
from sqlalchemy import desc
stmt = select(Address.user_id, func.count(Address.id).label('count')).group_by('user_id').order_by('user_id', desc('count'))
# 对应sql
SELECT address.user_id, count(address.id) AS count
FROM address GROUP BY address.user_id
ORDER BY address.user_id, count DESC
表别名 aliased
from sqlalchemy.orm import aliased
u = aliased(User)
a = aliased(Address)
stmt = select(u.name, a.email).join(a)
# 对应sql
SELECT user_account_1.name, address_1.email
FROM user_account AS user_account_1 JOIN address AS address_1 ON user_account_1.id = address_1.user_id
子查询
subquery()
# subquery()构造子查询结构
sub = select(func.count(Address.id).label('count'), Address.user_id).group_by('user_id').subquery()
print('subquery:', sub)
# 使用子查询
stmt = select(User.name, sub.c.count).join_from(User, sub)
print(stmt)
注: 使用子查询的字段时, 中间需要加上.c属性: sub.c.count
# 打印结果
subquery: SELECT count(address.id) AS count, address.user_id FROM address GROUP BY address.user_id
SELECT user_account.name, anon_1.count
FROM user_account JOIN (SELECT count(address.id) AS count, address.user_id AS user_id
FROM address GROUP BY address.user_id) AS anon_1 ON user_account.id = anon_1.user_id
# 查询结果
('ming', 2)
('gang', 2)
cte()
用法与subquery()相同, 只是在使用子查询时, 会将子查询转为with语句的sql
# cte()构造子查询结构
cte = select(func.count(Address.id).label('count'), Address.user_id).group_by('user_id').cte()print('cte:', cte)
# 使用子查询
stmt = select(User.name, cte.c.count).join_from(User, cte)
print(stmt)
注: 使用子查询的字段时, 中间需要加上.c属性: sub.c.count
# 打印结果
cte: SELECT count(address.id) AS count, address.user_id FROM address GROUP BY address.user_id
WITH anon_1 AS
(SELECT count(address.id) AS count, address.user_id AS user_id FROM address GROUP BY address.user_id)
SELECT user_account.name, anon_1.count
FROM user_account JOIN anon_1 ON user_account.id = anon_1.user_id
union / union all
from sqlalchemy import union, union_all
stmt1 = select(User.name).where(User.name == 'ming')
stmt2 = select(User.name).where(User.name.like('%ng%'))
stmt_union = union(stmt1, stmt2)
stmt_union_all = union_all(stmt1, stmt2)
print('stmt_union:', stmt_union)
print('stmt_union_all:', stmt_union_all)
# 打印结果
stmt_union:
SELECT user_account.name
FROM user_account
WHERE user_account.name = :name_1
UNION
SELECT user_account.name
FROM user_account
WHERE user_account.name LIKE :name_2
# 查询结果
('ming',)
('hong',)
('gang',)
stmt_union_all:
SELECT user_account.name
FROM user_account
WHERE user_account.name = :name_1
UNION ALL
SELECT user_account.name
FROM user_account
WHERE user_account.name LIKE :name_2
# 查询结果
('ming',)
('ming',)
('hong',)
('gang',)
SQL函数及返回类型
# count()
>>> print(select(func.count()).select_from(user_table))
SELECT count(*) AS count_1
FROM user_account
# lower()
>>> print(select(func.lower("A String With Much UPPERCASE")))
SELECT lower(:lower_2) AS lower_1
# now()
>>> stmt = select(func.now())
>>> with engine.connect() as conn:
... result = conn.execute(stmt)
... print(result.all())
# 函数返回类型
>>> func.now().type
DateTime()
>>> func.max(Column("some_int", Integer)).type
Integer()
对象关系
在上面的模型类定义时, 定义了两个模型关系, User和Address, 一个User对象可以有多个Address对象
from sqlalchemy.orm import relationship
class User(Base):
__tablename__ = 'user_account'
# ... Column mappings
addresses = relationship("Address", back_populates="user")
class Address(Base):
__tablename__ = 'address'
# ... Column mappings
user = relationship("User", back_populates="addresses")
print('1. 创建一个User对象gang')
gang = User(name='gang', fullname='xiao gang')
print(gang)
print('此时gang的addresses属性还是空')
print(gang.addresses)
print('2. 创建一个Address对象qq')
qq = Address(email="123@qq.com")
print('3. 将qq追加到gang的addresses属性中')
gang.addresses.append(qq)
print('查看gang的addresses属性')
print(gang.addresses)
print('追加的同时, 在qq的user属性中也添加了gang这个对象')
print(qq.user)
print('4. 在创建address对象时, 也可以指定其user属性')
print('如创建一个新address对象email_163, 给其user属性赋值为用户gang')
email_163 = Address(email='123@163.com', user=gang)
print('查看gang的addresses, 可以看到新追加了一个地址email_163')
print(gang.addresses)
print('5. 将gang对象添加到session中, 可以发现其关联的其他对象如qq和163也会一并自动添加到session中')
with Session(engine) as session:
session.add(gang)
print(qq in session)
print(email_163 in session)
print('6. 提交')
session.commit()
# 打印结果
1. 创建一个User对象gang
User=(id=None, name='gang', fullname='xiao gang')
此时gang的addresses属性还是空
[]
2. 创建一个Address对象qq
3. 将qq追加到gang的addresses属性中
查看gang的addresses属性
[Address=(id=None, email='123@qq.com')]
追加的同时, 在qq的user属性中也添加了gang这个对象
User=(id=None, name='gang', fullname='xiao gang')
4. 在创建address对象时, 也可以指定其user属性
如创建一个新address对象email_163, 给其user属性赋值为用户gang
查看gang的addresses, 可以看到新追加了一个地址email_163
[Address=(id=None, email='123@qq.com'), Address=(id=None, email='123@163.com')]
5. 将gang对象添加到session中, 可以发现其关联的其他对象如qq和163也会一并自动添加到session中
True
True
6. 提交
BEGIN (implicit)
sqlalchemy.engine.Engine INSERT INTO user_account (name, fullname) VALUES (%(name)s, %(fullname)s)
sqlalchemy.engine.Engine [generated in 0.00016s] {'name': 'gang', 'fullname': 'xiao gang'}
sqlalchemy.engine.Engine INSERT INTO address (email, user_id) VALUES (%(email)s, %(user_id)s)
sqlalchemy.engine.Engine [generated in 0.00017s] {'email': '123@qq.com', 'user_id': 13}
sqlalchemy.engine.Engine INSERT INTO address (email, user_id) VALUES (%(email)s, %(user_id)s)
sqlalchemy.engine.Engine [cached since 0.008612s ago] {'email': '123@163.com', 'user_id': 13}
sqlalchemy.engine.Engine COMMIT
模型基类
通常每张表都需要创建日期(create_time), 创建人(create_by), 更新时间(update_time), 更新人(update_by)这四个字段, 且两个日期都需要在创建或者更新时自动更新为当前时间, 那么可以定义一个基类, 让每张表的模型类继承这个基类, 就不需要每张表都重复定义字段了, 基类定义如下:
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, DATETIME, Integer
Base = declarative_base()
class BaseModel(Base):
"""模型基类"""
# 指明这是一个基类
__abstract__ = True
# 创建时自动设置当前时间
create_time = Column(DATETIME, server_default=func.now())
# 创建和更新时自动设置当前时间
update_time = Column(DATETIME, server_default=func.now(), onupdate=func.now())
create_by = Column(Integer)
update_by = Column(Integer)
# 异步时与server_default配合一起使用
__mapper_args__ = {"eager_defaults": True}
其他类继承即可, 如:
from sqlalchemy import Column, Integer
from models.base_model import BaseModel
class User(BaseModel):
__tablename__ = 'user'
user_id = Column(Integer, primary_key=True)
异步支持
通用案例
import asyncio
from sqlalchemy import Column
from sqlalchemy import DateTime
from sqlalchemy import ForeignKey
from sqlalchemy import func
from sqlalchemy import Integer
from sqlalchemy import String
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.future import select
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy.orm import selectinload
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class A(Base):
__tablename__ = "a"
id = Column(Integer, primary_key=True)
data = Column(String)
create_date = Column(DateTime, server_default=func.now())
bs = relationship("B")
# required in order to access columns with server defaults
# or SQL expression defaults, subsequent to a flush, without
# triggering an expired load
__mapper_args__ = {"eager_defaults": True}
class B(Base):
__tablename__ = "b"
id = Column(Integer, primary_key=True)
a_id = Column(ForeignKey("a.id"))
data = Column(String)
async def async_main():
engine = create_async_engine(
"postgresql+asyncpg://scott:tiger@localhost/test",
echo=True,
)
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.drop_all)
await conn.run_sync(Base.metadata.create_all)
# expire_on_commit=False will prevent attributes from being expired
# after commit.
async_session = sessionmaker(
engine, expire_on_commit=False, class_=AsyncSession
)
async with async_session() as session:
async with session.begin():
session.add_all(
[
A(bs=[B(), B()], data="a1"),
A(bs=[B()], data="a2"),
A(bs=[B(), B()], data="a3"),
]
)
stmt = select(A).options(selectinload(A.bs))
result = await session.execute(stmt)
for a1 in result.scalars():
print(a1)
print(f"created at: {a1.create_date}")
for b1 in a1.bs:
print(b1)
result = await session.execute(select(A).order_by(A.id))
a1 = result.scalars().first()
a1.data = "new data"
await session.commit()
# access attribute subsequent to commit; this is what
# expire_on_commit=False allows
print(a1.data)
asyncio.run(async_main())