神经网络过拟合问题
这其实是个玄学
train loss 不断下降,test loss趋于不变,说明网络过拟合;也就是测试集没有被训练,也有可能是梯度消失问题
查看神经网络的层
model1 = Sequential()
model1.add(Embedding(max_words, embedding_dim))
model1.add(LSTM((LSTM_units)))
model1.add(Dense(3, activation='softmax'))
model1.summary()
这里只有简单的三层神经网络,lstm层之后直接到输出层了,这个网络是非常简单的,同时也存在一个问题,就是容易导致梯度消失
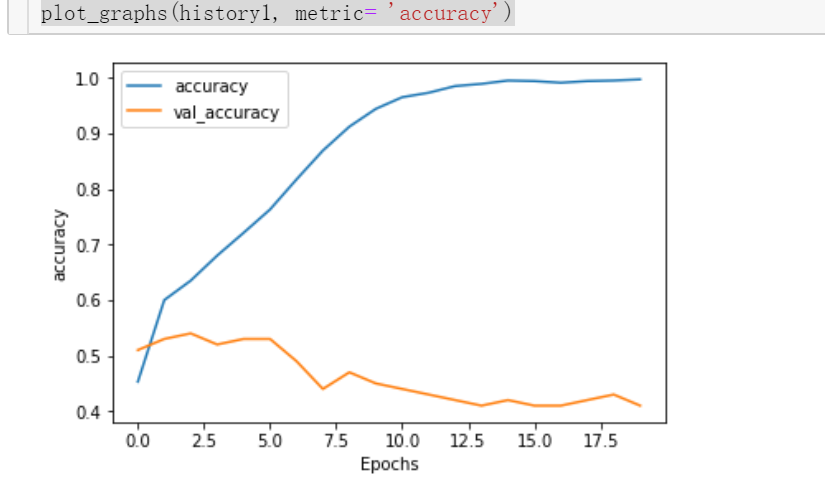
测试集的精度在下降,因此没有被训练。接下来增加dense层,激活函数为relu,在现有的研究成果中,relu激活函数是已经被证明了可以有效的解决梯度消失问题
整流线性单元(ReLU)是最广泛使用的激活函数,因为它解决了梯度消失的问题。更早时候,Sigmoid 和 Tanh 函数都是最常用的激活函数。但是它们都会遇到梯度消失的问题,即在反向传播中,梯度在到达初始层的过程中,值在变小,趋向于 0。这不利于神经网络向具有更深层的结构扩展。ReLU 克服了这个问题,因此也就可以允许神经网络扩展到更深的层。refs
因此增加一个dense层,激活函数是relu
model = Sequential()
model.add(Embedding(max_words, embedding_dim))
model.add(Dropout(0.2))
model.add(LSTM(LSTM_units))
model.add(Dense(24, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.summary()


从结果来看训练集的误差是不断下降的,但是验证集的误差并没有下降,因此这里可是是数据预处理存在的问题,但是验证集和训练集数据预处理的是一致的,而且样本也是随机打乱的,因此排除数据集的问题。因此考虑样本分布是否在进入下一层的时候发生了改变
对于神经网络这种包含多个隐层的模型,在训练过程中,各层参数不停变化,所以各个隐层都会面对”covariate shift“的问题,这个问题不仅仅会发生在输入层,而是在神经网络内部都会发生,因此是”internal covariate shift“。
Batch normalization的基本思想:深层神经网络在做非线性变换前的输入值在训练过程中,其分布逐渐发生偏移,之所以训练收敛慢,一般是整体分布逐渐往非线性激活函数的两端靠近,这导致了反向传播时浅层神经网络的梯度消失。而batch normalization就是通过一定的规范化手段,将每个隐层输入的分布强行拉回到均值为0方差为1的标准正态分布上去,这使得输入值落回到非线性激活函数”敏感“区域。这使得梯度变大,学习速度加快,大大提高收敛速度。cnblogs
因此增加bn和dropout查看效果
model3 = Sequential()
model3.add(Embedding(max_words, embedding_dim))
model3.add(Dropout(0.2))
model3.add(LSTM(LSTM_units))
model3.add(BatchNormalization())
model3.add(Dropout(0.2))
model3.add(Dense(24, activation='relu'))
model3.add(BatchNormalization())
model3.add(Dropout(0.2))
model3.add(Dense(3, activation='softmax'))
model3.summary()


比之前的效果要好一些,但是,验证集的loss似乎还是没什么变化,需要再逛一下论坛~
究竟是发生了什么可怕的情况???
梯度消失、大量神经元失活、梯度爆炸和弥散、学习率过大或过小等。。。
目前学长提到的解决方案是增加一个dense层,把神经网络变更深,随着深度的增加容易过拟合,因此加入bn和dropout降低过拟合

解决方案感觉其实是存在冲突的,但其实是我这边代码的bug,
early stoping和dropout,bn都增加了,但是效果不是很满意,因此是感觉是数据的bug
还是需要进一步再产看