
1、研究动机
当前的语义分割主要利用RGB图像,加入多源信息作为辅助(depth, Thermal等)可以有效提高语义分割的准确率,即融合多模态信息可以有效提高准确率。当前方法主要包括两种:
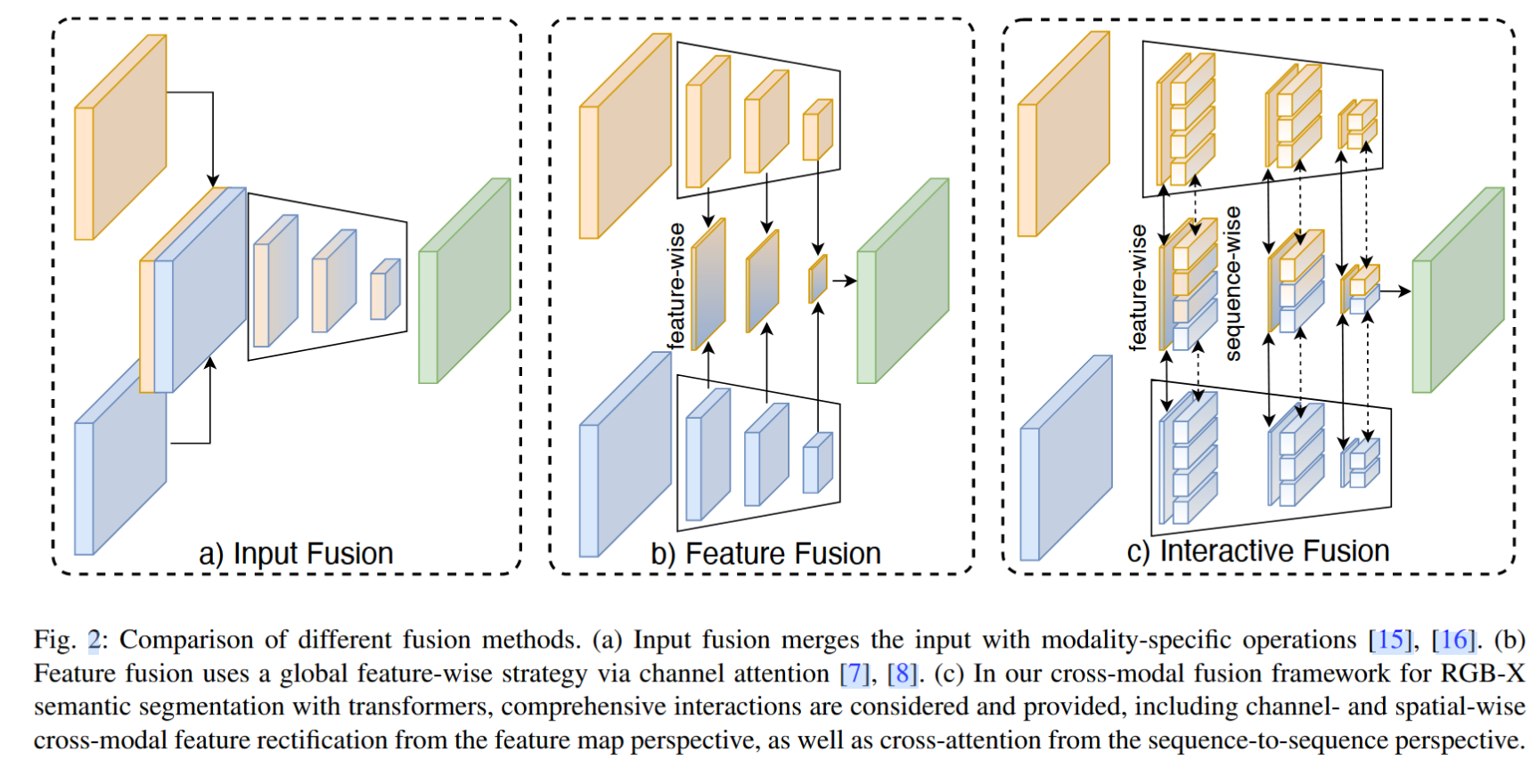
- Input fusion: 如下图a所示,将RGB和D数据拼接在一起,使用一个网络提取特征。
- Feature fusion: 如下图b所示,将分别用两个网络提取RGB和D的特征,然后在网络中间进行特征交互融合。
作者提出的CMX,特点为:comprehensive interactions are considered, including channel and spatial-wise cross-modal feature rectification from the feature map, as well as cross-attention from the sequence-to-sequence perspective.
2、主要方法
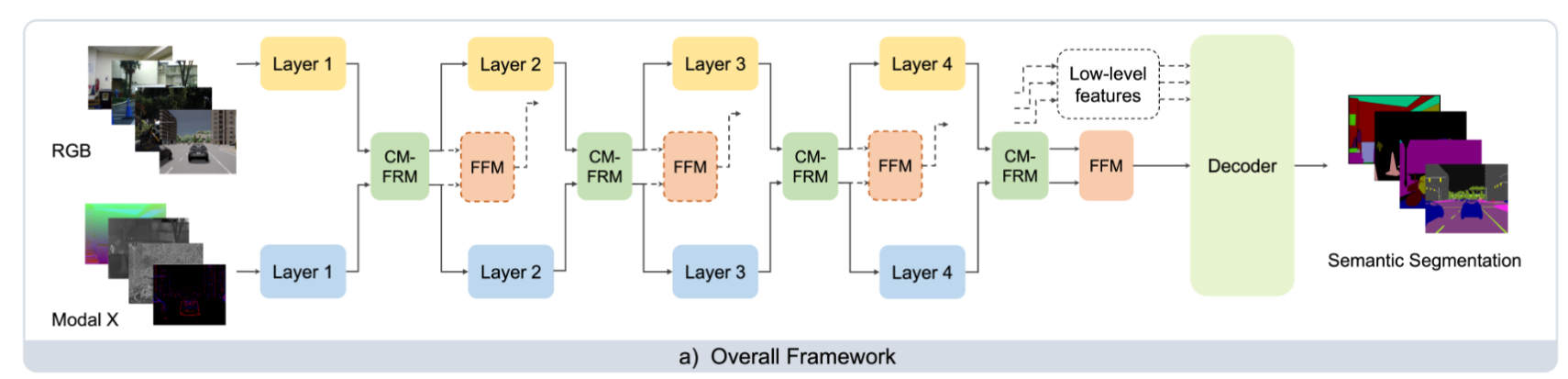
CMX的主要方框架如下图所示,使用两个并行主干从RGB和X模态输入中提取特征,中间输入 CM-FRM (cross-modal feature rectification module)进行特征修正,修正后的特征继续传入下一层。此外,同一层的特征还被输入FFM(feature fusion module)融合。下面将仔细介绍 CM-FRM 和 FFM。
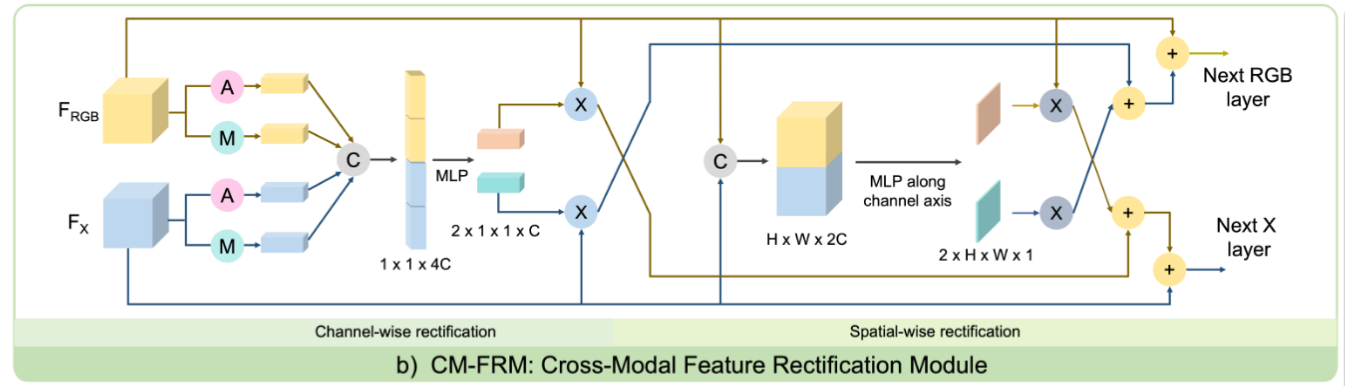
CM-FRM: cross-modal feature rectification module 结构如下图所示,输入的两个特征大小均为CHW, 然后分别使用 average pooling 和 max pooling 池化为1x1xC维向量,拼接为1x1x4C,通过 MLP 和 sigmoid,分别对上下分支的特征进行校正。后续对特征进行一个空间级的注意力计算,但是这里的注意力计算进行了“交叉”。最终输出时,采用了下面形式:\(X_{out}=X_{in}+\lambda_CX^{C}_{rec}+\lambda_SX^{S}_{rec}\) 。融合中用到了两个超参数,实验中值均为0.5。
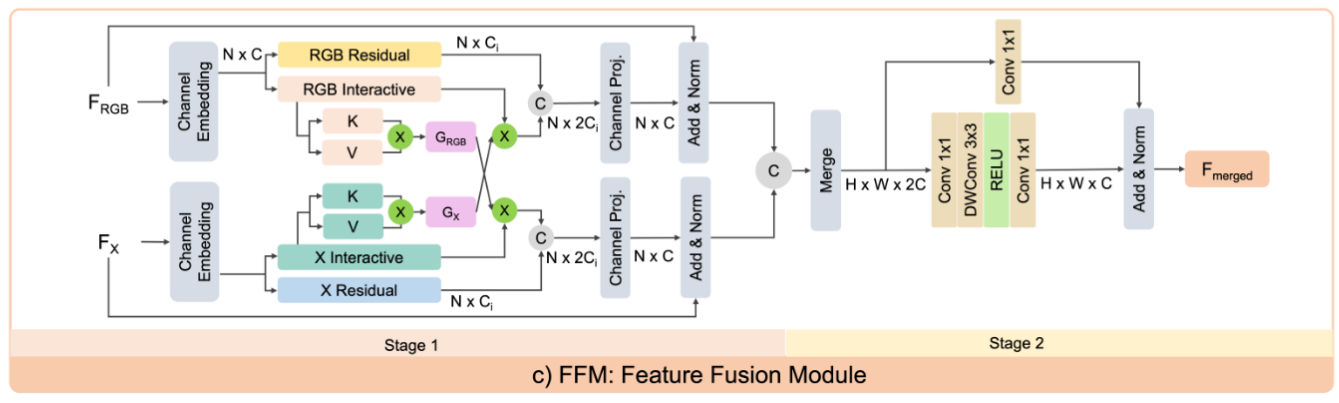
FFM:feature fusion module 结构如下图所示,可以看出,是基于 Transformer 的。和其他方法不同的是,这里把两个模态对等处理了。只不过在QKV计算上,使用了《Efficient Attention: Attention with Linear Complexities》里的处是方法,可以降低attention的计算量。在FFN部分,采用了Depth-wise conv取代MLP,同时,残差连接添加了一个 1x1卷积可以进一步提升效果。
实验部分可以参考作者论文,这里不再多说。