1.Redis是什么
Redis是一个使用ANSI C(C语言) 编写的开源的高性能的Key-Value的NoSQL数据库(非关系型数据库)。
2.Redis特点
1.基于内存
2.可持久化数据
3.具有丰富的数据结构类型,适应非关系型数据的存储需求
4.支持绝大多数主流开发语言,如C、C++、Java、Python、R、JavaScript等。
5.支持集群模式,高效、稳定。
3.数据模型(A)
1.键值对形式。
2.Redis的数据结构类型,指的就是Redis值的结构类型。
4.Redis作用
1.本质是数据库,能存储数据。
Redis能灵活处理非关系型数据的读、写问题,是对MySQL等关系型数据库的补充。
新浪微博就是使用Redis集群做数据库。
2.缓存数据。
所谓缓存,就是将数据加载到内存中后直接使用,而不是每次都通过IO流从磁盘上读取。好处:读写效率高。
而Redis则是将数据直接存储在内存中,只有当内存空间不足时,将部分数据持久化到磁盘上。
5.Redis安装(Linux)
Redis官方只提供了源码,并没有提供经过编译之后的安装包。因此,安装Redis,要先编译、后安装。(即源码安装方式)
5.1 redis安装步骤
1.下载,上传到Linux服务器,并解压
2.预编译(实际上是检查编译环境的过程)
进入目录: cd /opt/soft/redis-3.2.9/deps/jemalloc
执行预编译 ./configure
在预编译的过程中,会检测安装redis所需的相关依赖,依次安装即可。
如:缺少c编译环境 yum -y install gcc-c++
预编译不是必须的步骤,它只是在检查编译过程中需要的环境是否满足。通常源码包中,都有一个可执行的configure脚本,这个脚本执行预编译的脚本。但是有一些源码包中,没有该文件,可以省略预编译步骤。
3.编译 进入/opt/soft/redis-3.2.9/src
make
4.安装 进入/opt/soft/redis-3.2.9/src
make install
5.启动redis服务端(指定配置文件)
拷贝redis.conf文件到/etc 目录下,方便管理。
cp /opt/soft/redis-3.2.9/redis.conf /etc/
/usr/local/bin/redis-server /etc/redis.conf
6.启动redis客户端,登陆 /usr/local/bin/redis-cli
6.redis.conf常用配置说明
6.1 requirepass (设置密码)
给redis设置密码
在/etc/redis.conf中设置密码(退出redis登录用quit)
找到上面这行代码改成
设置密码后需要重新启动redis服务端 才会生效
在客户端使用auth命令,验证密码。
6.2 databases(数据库)
Redis默认有16个数据库,寻址角标从0开始。
默认连接db0
客户端使用select命令可切换数据库
6.3 port(端口)
指定redis的服务端口,默认6379
6.4 daemonize(后台进程)
Redis默认关闭后台进程模式,改成yes,redis服务在后台启动。
6.5 loglevel(日志级别)
6.6 logfile(日志输出文件)
Redis日志输出目录,默认不输出日志到文件。
6.7 dbfilename(持久化文件名)、 dir(文件路径)
指定数据持久化的文件名及目录。
7.将redis添加为系统服务
7.1 第一步:开启后台模式
修改配置文件,将daemonize改为yes
7.2 第二步:创建shell脚本
Linux系统服务,在/etc/init.d目录下创建redis脚本
########################### #chkconfig: 2345 10 90 #description: Start and Stop redis PATH=/usr/local/bin:/sbin:/usr/bin:/bin REDISPORT=6379 EXEC=/usr/local/bin/redis-server REDIS_CLI=/usr/local/bin/redis-cli ##判断redis是否启动了 PIDFILE=/var/run/redis_6379.pid CONF="/etc/redis.conf" PASSWORD=$(cat $CONF|grep '^s*requirepass'|awk '{print $2}'|sed 's/"//g') case "$1" in start) if [ -f $PIDFILE ] then echo "$PIDFILE exists, process is already running or crashed" else echo "Starting Redis server..." $EXEC $CONF fi if [ "$?"="0" ] then echo "Redis is running..." fi ;; stop) if [ ! -f $PIDFILE ] then echo "$PIDFILE does not exist, process is not running" else PID=$(cat $PIDFILE) echo "Stopping ..." if [ -z $PASSWORD ] then $REDIS_CLI -p $REDISPORT shutdown else $REDIS_CLI -a $PASSWORD -p $REDISPORT shutdown fi #$REDIS_CLI -p $REDISPORT SHUTDOWN while [ -x ${PIDFILE} ] do echo "Waiting for Redis to shutdown ..." sleep 1 done echo "Redis stopped" fi ;; restart|force-reload) ${0} stop ${0} start ;; *) echo "Usage: /etc/init.d/redis {start|stop|restart|force-reload}" >&2 exit 1 esac ##############################
7.3 第三步:添加shell脚本可执行权限
chmod +x /etc/init.d/redis
7.4 第四步:添加Redis开机启动
7.4 第四步:添加Redis开机启动
8.Redis的值(value)的数据结构类型
一般说Redis的数据结构类型,指的就是redis的值value的类型;
Redis常用的数据结构类型:string、list、set、sortedSet、hash
9.Redis的使用
9.1 key的类型
redis的key 值是二进制安全的,这意味着可以用任何二进制序列作为key值,从形如”foo”的简单字符串到一个JPEG文件的内容都可以。空字符串也是有效key值。
redis建议使用字符串做为key的类型
9.2 key取值规范
1.键值不需要太长,消耗内存,在数据中查找这类键值的计算成本较高
2.键值不宜过短,可读性较差,通常建议见名知意。
例:user:id:1:username;user:id:1:password 。通过user:id:1*查询。这就是一种命名方式(不一定要使用这种方式)
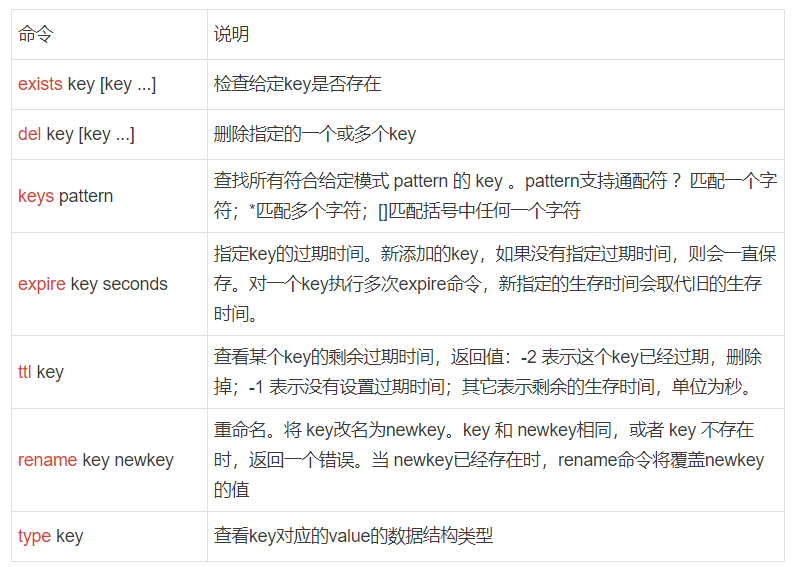
9.3 Key命令
9.4 string类型
string类型是redis最常用的数据结构类型,存储的值为字符串。
string类型相关命令

String类型的应用场景
1.做与统计有关的业务,如新浪微博(微信朋友圈)中的点赞功能
2.解决多线程的线程安全问题。
Redis的key是单线程模式,这就意味一瞬间只有一个线程能够持有这个key,所以可以使用redis解决部分涉及线程安全的业务,比如说抢购、秒杀。
再比如学习多线程时模拟买票窗口的卖票业务。
9.5 List类型
特点:
1.基于Linked List实现
2.元素是字符串类型
3.列表头尾增删快,中间增删慢,增删元素是常态
4.元素可以重复出现
5.最多包含2^32-1元素
列表的索引:从左至右,从0开始;从右至左,从-1开始
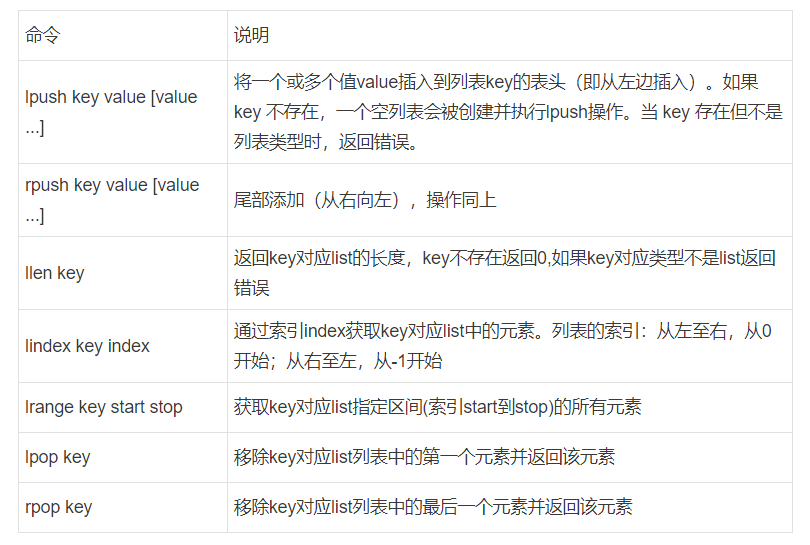
List类型相关命令
List类型应用场景
1.处理排名类业务。如新浪微博评论、论坛回帖楼层等。
2.聊天室
9.6 Hash类型(散列)
特点
1.由Field(字段)和与之关联的value组成map键值对
2.field和value是字符串类型;
3.一个hash中最多包含2^32-1键值对。
Hash相关命令

Hash的作用
节约内存空间:
redis每创建一个键,都会为这个键储存一些附加的管理信息(比如这个键的类型,这个键最后一次被访问的时间等等)可以说redis的key相对于值来说,更珍贵!所以数据库里面的键越多,redis数据库服务器在储存附加管理信息方面耗费的内存就越多,在获取key对应的value值时cpu的开销也会更多 。
Hash结构可以将具有关联关系的一组key-value,存储到同一个hash结构中,从而减少key的数量。所以在能使用hash的时候尽量使用hash。
不适合使用Hash的场景
在需要只对hash中某个字段设置过期时,就不建议使用hash。Redis的key的过期功能只能对键操作,而Hash结构不能单独对某一个filed设置过期功能。
9.7 Set类型(集合)
特点
1.无序的、去重的;
2.元素是字符串类型;
3.最多包含2^32-1元素。
Set相关命令

Set应用场景
新浪微博的共同关注:当用户访问另一个用户的时候,会显示出两个用户共同关注哪些相同的用户(交集)
9.8 SortedSet类型(有序集合)
特点
1.类似Set集合;
2.有序的、去重的;
3.元素是字符串类型;
4.每一个元素都关联着一个浮点分数值(Score),并按照分数值从小到大的顺序排列集合中的元素。分数值可以相同,相同时按字典顺序排列
5.最多包含2^32-1元素
SortedSet类型相关命令

SortedSet类型适用场景
适用于需要有序且唯一的业务或操作:
如,网易音乐排行榜:
每首歌的歌名作为元素(唯一、不重复)
每首歌的播放次数作为分值
用zrevrange来获取播放次数最多的歌曲(就是最多播放榜了,云音乐热歌榜,没有竞价,没有权重)
10.使用Jedis连接redis服务器
Jedis是Redis官方推荐的Java连接开发工具,可以通过java代码操作redis数据库,就类似于jdbc
10.1 使用jedis连接redis可能会出现的问题及解决方案:
1.ip绑定问题
使用Jedis连接redis服务器需要把Redis的配置文件redis.conf里的bind 127.0.0.1(或bind localhost)注释掉,这句话的意思是仅允许本机才能访问。我们需要让redis服务器允许其他主机访问
2.保护模式(如果设置了密码可以进行密码验证,不用关闭保护模式)
DENIED Redis is running in protected mode because protected mode is enabled…
关闭保护模式:把Redis的配置文件redis.conf中的protected-mode 的yes改成no
10.2 Jedis 相关jar包导入
10.3 Jedis连接redis服务端
package com.gjs.jedis; import org.junit.Test; import redis.clients.jedis.Jedis; public class TestJedis { @Test public void testJedisConnect() throws Exception { //创建客户端指定连接服务器端主机ip和端口,端口不指定时默认使用6379 Jedis jedis = new Jedis("192.168.192.128", 6379); System.out.println("连接redis服务器端成功!"); jedis.auth("1234"); //登录验证 //测试连接 System.out.println("redis服务器是否运行:"+jedis.ping()); System.out.println("redis服务器信息:"+jedis.info()); //关闭连接 jedis.close(); } }
10.4 Key测试
jedis类中大部分方法名都与对应的命令同名
@Test public void testKey() throws Exception { //创建客户端指定连接服务器端主机ip和端口,端口不指定时默认使用6379 Jedis jedis = new Jedis("192.168.192.128", 6379); System.out.println("连接redis服务器端成功!"); //登录验证 jedis.auth("1234"); jedis.set("name", "zhangsan");//加入数据 System.out.println("获取key对应的值:"+jedis.get("name")); Set<String> keys = jedis.keys("*");//使用通配符进行模糊查询 System.out.println("获取所有key的值:"+keys); //关闭连接 jedis.close(); }
10.5 List测试
@Test public void testList() throws Exception { //创建客户端指定连接服务器端主机ip和端口,端口不指定时默认使用6379 Jedis jedis = new Jedis("192.168.192.128", 6379); System.out.println("连接redis服务器端成功!"); //登录验证 jedis.auth("1234"); jedis.lpush("list", new String[] {"a","c","b"});//添加数据 Long len = jedis.llen("list");//获取长度 System.out.println("list长度:"+len); System.out.println("list元素:"+jedis.lrange("list", 0, len)); System.out.println("指定索引位置的元素:"+jedis.lindex("list", 1)); //关闭连接 jedis.close(); }
10.6 Hash测试
@Test public void testHash() throws Exception { //创建客户端指定连接服务器端主机ip和端口,端口不指定时默认使用6379 Jedis jedis = new Jedis("192.168.192.128", 6379); System.out.println("连接redis服务器端成功!"); //登录验证 jedis.auth("1234"); //添加数据 jedis.hset("user", "id", "1"); jedis.hset("user", "name", "zhangsan"); jedis.hset("user", "password", "123456"); //获取所有元素 Map<String, String> user = jedis.hgetAll("user"); System.out.println("获取hash的所有字段值:"+user); //关闭连接 jedis.close(); }
10.7 Set测试
@Test public void testSet() throws Exception { //创建客户端指定连接服务器端主机ip和端口,端口不指定时默认使用6379 Jedis jedis = new Jedis("192.168.192.128", 6379); System.out.println("连接redis服务器端成功!"); //登录验证 jedis.auth("1234"); //添加数据 jedis.sadd("set1",new String[] {"a","s","d","f","g"}); jedis.sadd("set2", new String[] {"a","s","z","x"}); //获取所有元素 Set<String> set1 = jedis.smembers("set1"); System.out.println("获取set的所有元素:"+set1); System.out.println("获取元素数量:"+jedis.scard("set1")); //获取交并补集,方法参数是可变的 Set<String> inter = jedis.sinter("set1","set2"); System.out.println("获取交集:"+inter); Set<String> union = jedis.sunion("set1","set2"); System.out.println("获取并集:"+union); Set<String> diff = jedis.sdiff("set1","set2"); System.out.println("获取差集:"+diff); //关闭连接 jedis.close(); }
10.8 SortedSet测试
@Test public void testSortedSet() throws Exception { //创建客户端指定连接服务器端主机ip和端口,端口不指定时默认使用6379 Jedis jedis = new Jedis("192.168.192.128", 6379); System.out.println("连接redis服务器端成功!"); //登录验证 jedis.auth("1234"); //添加数据 Map<String, Double> scoreMembers = new HashMap<>(); scoreMembers.put("a", 1d); scoreMembers.put("b", 3d); scoreMembers.put("c", 2d); jedis.zadd("sortSet", scoreMembers); //获取数据 //获取分数值在指定区间的元素并按分数值由小到大排序 Set<String> zrange = jedis.zrange("sortSet", 0, 3); System.out.println(zrange); //关闭连接 jedis.close(); }
11.Redis持久化
Redis持久化,就是将内存中的数据,永久保存到磁盘上。
Redis持久化有两种方式:RDB(Redis DB)、AOF(AppendOnlyFile)。
11.1 RDB(快照模式)
在默认情况下,Redis 将数据库快照保存在名字为dump.rdb的二进制文件中,可以在redis.conf配置文件中修改持久化信息。
save 900 1 表示在900秒内,至少更新了1条数据。Redis就将数据持久化到硬盘
save 300 10 表示在300内,至少更新了10条数据,Redis就会触发将数据持久化到硬盘
save 60 10000 表示60秒内,至少更新了10000条数据,Redis就会触发将数据持久化到硬盘
11.1.1 策略
1.自动:BGSAVE
按照配置文件中的条件满足就执行BGSAVE;非阻塞,Redis服务正常接收处理客户端请求;
Redis会folk()一个新的子进程来创建RDB文件,子进程处理完后会向父进程发送一个信号,通知它处理完毕,父进程用新的dump.rdb替代旧文件。
2.手动:SAVE
由客户端(redis-cli)发起SAVE命令;阻塞Redis服务,无法响应客户端请求;创建新的dump.rdb替代旧文件。
11.1.2 优点
1.执行效率高;
2.恢复大数据集速度较AOF快。
11.1.3 缺点
1.会丢失最近写入、修改的而未能持久化的数据;
2.folk过程非常耗时,会造成毫秒级不能响应客户端请求。
11.2 AOF(追加模式、文本重演)
AOF(Append only file),采用追加的方式保存,默认文件appendonly.aof。记录所有的写操作命令,在服务启动的时候使用这些命令就可以还原数据库。AOF默认关闭,需要在配置文件中手动开启。
11.2.1 写入机制
说明:AOF机制,添加了一个内存缓冲区(buffer)。
1.将内容写入缓冲区
2.当缓冲区被填满、或者用户手动执行fsync、或者系统根据指定的写入磁盘策略自动调用fdatasync命令,才将缓冲区里的内容真正写入磁盘里。
3.在缓冲区里的内容未写入磁盘之前,可能会丢失。
11.2.2 写入磁盘的策略
appendfsync选项,这个选项的值可以是always、everysec或者no
Always:服务器每写入一个命令,就调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,也不会丢失任何已经成功执行的命令数据
Everysec(默认):服务器每一秒重调用一次fdatasync,将缓冲区里面的命令写入到硬盘。这种模式下,服务器出现故障,最多只丢失一秒钟内的执行的命令数据
No:服务器不主动调用fdatasync,由操作系统决定何时将缓冲区里面的命令写入到硬盘。这种模式下,服务器遭遇意外停机时,丢失命令的数量是不确定的
运行速度:always的速度慢,everysec和no都很快
11.2.3 AOF重写机制
AOF文件过大,合并重复的操作,AOF会使用尽可能少的命令来记录。
重写过程
1.folk一个子进程负责重写AOF文件
2.子进程会创建一个临时文件写入AOF信息
3.父进程会开辟一个内存缓冲区接收新的写命令
4.子进程重写完成后,父进程会获得一个信号,将父进程接收到的新的写操作由子进程写入到临时文件中
5.新文件替代旧文件
重写的本质:就是将操作同一个键的命令,合并。从而减小AOF文件的体积
AOF重写触发机制
1.手动:客户端向服务器发送BGREWRITEAOF命令
2.自动:配置文件中的选项,自动执行BGREWRITEAOF命令
auto-aof-rewrite-min-size ,
触发AOF重写所需的最小体积:只要在AOF文件的体积大于等于size时,才会考虑是否需要进行AOF重写,这个选项用于避免对体积过小的AOF文件进行重写
auto-aof-rewrite-percentage
指定触发重写所需的AOF文件体积百分比:当AOF文件的体积大于auto-aof-rewrite-min-size指定的体积,并且超过上一次重写之后的AOF文件体积的percent %时,就会触发AOF重写。(如果服务器刚刚启动不久,还没有进行过AOF重写,那么使用服务器启动时载入的AOF文件的体积来作为基准值)。将这个值设置为0表示关闭自动AOF重写。
11.2.4 优点
写入机制:默认Everysec每秒执行,性能很好不阻塞服务,最多丢失一秒的数据;
重写机制:优化AOF文件,如果误操作了(FLUSHALL等),只要AOF未被重写,停止服务移除AOF文件尾部FLUSHALL命令,重启Redis,可以将数据集恢复到FLUSHALL 执行之前的状态。
11.2.5 缺点
1.相同数据集,AOF文件体积较RDB大了很多;
2.恢复数据库速度较RDB慢(文本,命令重演)。