上一篇复盘的是选择行和列,这是利用python操作数据的基础和根本。本文将总结基本的算术运算规则。
算术运算
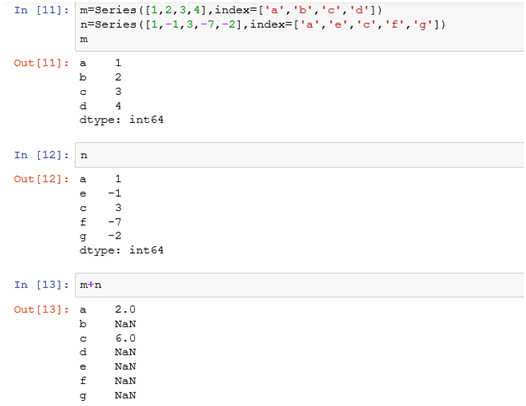
对于两个对象进行加减乘除的算数运算时,如果两个对象有不同的索引对,那么运算结果的索引就是该索引对的并集。而结果集索引对应的值是两个对象相同索引对应的值相加减乘除,不同的索引对应的值统一为NaN。比方说张三有梨子3个,苹果2个;李四有橘子1个,猕猴桃3个,苹果1个,梨子5个。那么张三和李四加起来的结果就是梨子8个,苹果3个,橘子未知,猕猴桃未知。这里的水果名即为索引,两者相同索引对应的值会相加,而不同索引对应的值将为NaN。
1.1 Series之间的运算
示例:
1.2 DataFrame之间的运算
示例:
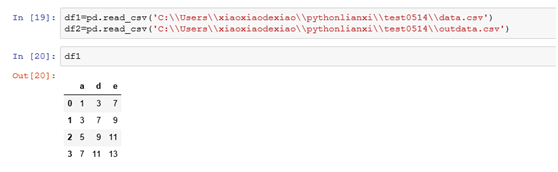

从上述例子上看可以发现DataFrame之间运算时,是行索引和列索引一起进行对齐操作,运算后的结果集的行索引是两者行索引的并集,结果集的列索引是两者列索引的并集。而行列对应的数值是df1和df2中相同行索引和相同列索引定位到的那个数值相加,如果两者的行索引或者列索引不相同数值将填充为NaN.
1.3 DataFrame与Series之间的运算
示例:


从以上示例可以看出两个相减时是从df1中匹配m中的列索引,匹配上了的就将df1的每一行都减去对应m的值。比如m中a,d是与df1相同的,那么df1的a,d两列的每一行都要减去m的a,d两个值。df1其他没匹配上的填充为NaN。
如果是按照行匹配,每列来运算,则利用轴标记来指定。
示例:
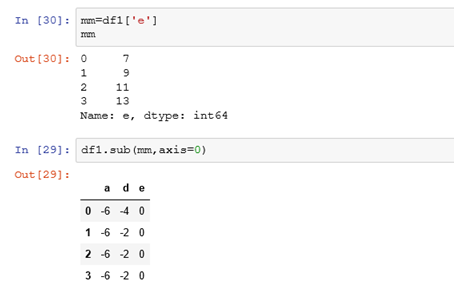
axis=0表示希望匹配的轴是行,按照行来匹配,减去每列的数值。