作业①:
代码展示:
import urllib
import prettytable as pt
from bs4 import BeautifulSoup
import requests
import re
import threading
global threads
a = {
'cookie': 'll="118200"; bid=0zPn59UdFfo; '
'_vwo_uuid_v2=D1121654C5B4AC9948740CF1CACD0A8CD|0a6ac8715f341d3a6a47d61efa74a39b; douban-fav-remind=1; '
'__yadk_uid=W8BIlRiVVagwGOeCGsNdzzjXWA8rn6hG; '
'__gads=ID=e77c87810eb936a2-2299f9f8bfc30009:T=1601483176:RT=1601483176:R:S=ALNI_MZlzhXCLWZzD_-Gl'
'-TFT_9ui_yNbw; ap_v=0,6.0; __utmz=30149280.1606266033.11.7.utmcsr=edu.cnblogs.com|utmccn=('
'referral)|utmcmd=referral|utmcct=/; __utmc=30149280; '
'__utma=30149280.1550450001.1597114843.1606266033.1606268353.12; ct=y; '
'RT=s=1606270295714&r=https%3A%2F%2Fmovie.douban.com%2Ftop250%3Fstart%3D0; '
'dbcl2="227264495:+V3P7NbJOM4"; ck=s0E7; '
'_pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1606270381%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; '
'_pk_id.100001.8cb4=f1e90477c87a1b31.1597077773.4.1606270381.1605018393.; _pk_ses.100001.8cb4=*; '
'push_noty_num=0; push_doumail_num=0; __utmt=1; __utmv=30149280.22726; '
'__utmb=30149280.19.9.1606270382807',
'user-agent': 'Mozilla/5,0'}
start_url = "https://movie.douban.com/top250?start="
tb = pt.PrettyTable(["排名", "电影名称", "导演", "主演", "上映时间", "国家", "电影类型", "评分", "评价人数", "引用", "文件路径"])
def start(url):
t = requests.get(url, headers=a)
t.encoding = 'utf-8' # 以'utf-8'编码
soup = BeautifulSoup(t.text, "html.parser")
return soup
def download(url, filename):
try:
req = urllib.request.Request(url, headers=a)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\" + filename + ".jpg", "wb")
fobj.write(data)
fobj.close()
print("download" + filename + "图片")
except Exception as err:
print(err)
def process(html,top_start):
top = top_start*25
lis = html.select("ol li div[class='item']")
print(len(lis))
for li in lis:
src = li.select("img")[0]["src"]
movie_name = li.select("div[class='hd'] span")[0].text
detail = li.select("div[class='bd'] p")[0].text.strip("")
if re.findall(r'导演: (.*?) ', detail):
director = re.findall(r'导演: (.*?) ', detail)[0]
else:
director = "not found director"
if re.findall(r'主演: (.*?) ', detail):
actor = re.findall(r'主演: (.*?) ', detail)[0]
else:
actor="not found actor"
detail = detail.split("
")[2]
year = re.findall(r'd+', detail)[0]
country = re.findall(r' / (.*) /', detail.replace(u'xa0', u' '))[0]
style = re.findall(r' / .* / (.*)', detail.replace(u'xa0', u' '))[0]
score = li.select('span[class="rating_num"]')[0].text
people = li.select('div[class="star"] span')[-1].text
if li.select('p span[class="inq"]'):
ying = li.select('p span[class="inq"]')[0].text
else:
ying = "not found 引用"
top = top+1
filepath="images/"+movie_name+".jpg"
tb.add_row([top,movie_name,director,actor,year,country,style,score,people,ying,filepath])
images = html.select("ol li div[class='item'] img")
for image in images:
try:
src = image["src"]
name = image["alt"]
T = threading.Thread(target=download, args=(src, name))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
for i in range(0,10):
url=start_url+str(i*25)
html=start(url)
process(html,i)
print(tb)结果展示:
没有点进电影详情界面,内容上会出现导演、主演、引言缺失的情况
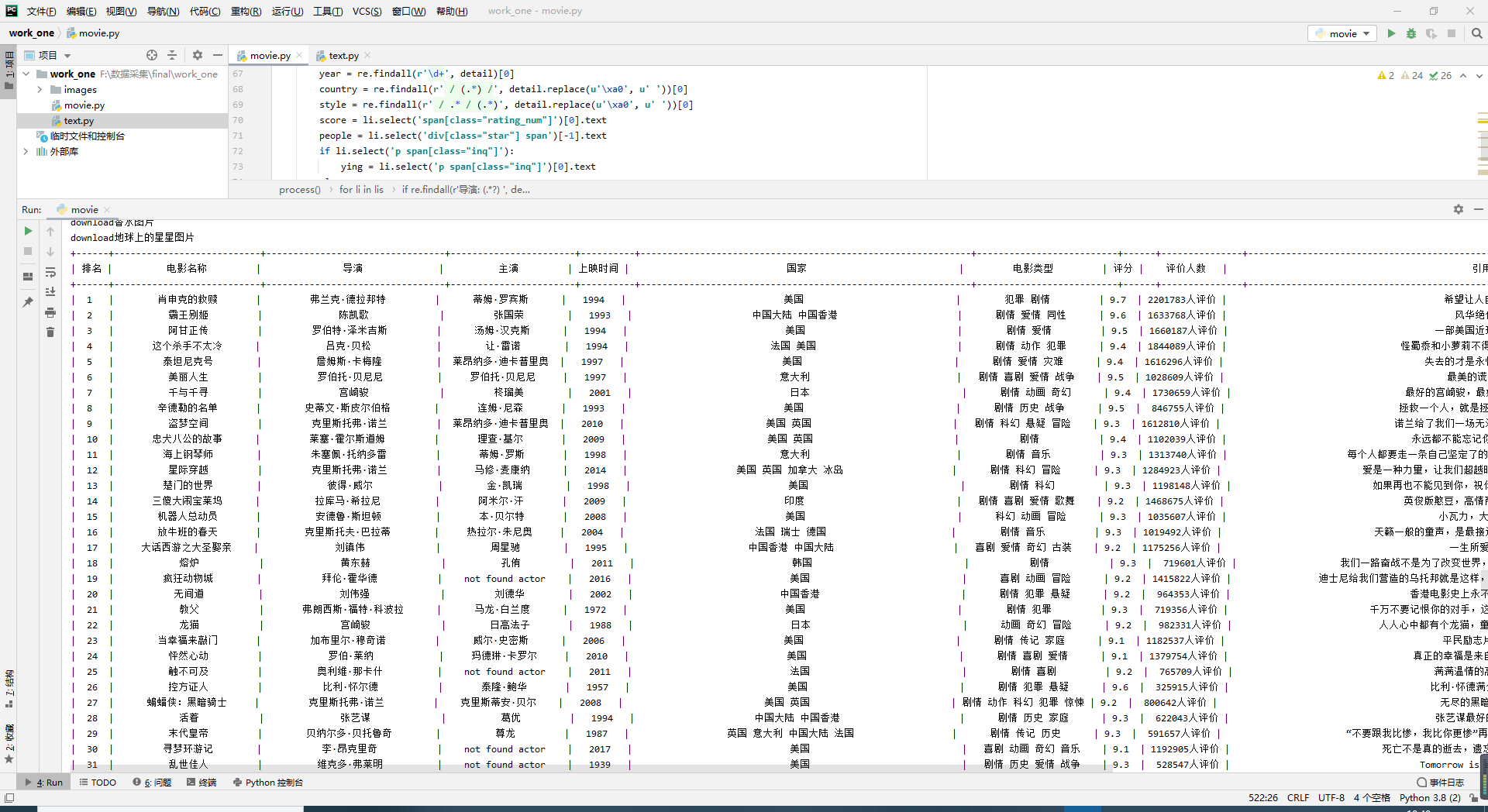
部分图片电影信息爬取后多线程才下载完

心得体会:
在本次爬取过程中发现

其中的空格是" ;"存在的,编码后是'/xa0',正则时不方便匹配,用replace替换成空格,以及本作业目标网站存在反爬的机制,后面使用自己登录后的cookie才正常爬取。
作业②:
代码展示:
spider部分:
import urllib
import requests
import scrapy
from bs4 import UnicodeDammit
from spider.items import UniversityItem
class UniversitySpider(scrapy.Spider):
name = 'university'
#allowed_domains = ['www.shanghairanking.cn/rankings/bcur/2020.io']
start_urls = 'http://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def start_requests(self):
url = UniversitySpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
print('start')
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//table[@class = 'rk-table']//tbody/tr")
print(len(lis))
for li in lis:
sNo=li.xpath("./td[position()=1]/text()").extract_first().replace(" ","").strip("
")
schoolName=li.xpath("./td[position()=2]/a/text()").extract_first().strip("
").replace(" ","")
city=li.xpath("./td[position()=3]/text()").extract_first().strip("
").replace(" ","")
print(sNo,schoolName,city)
try:
info_url = "https://www.shanghairanking.cn" + li.xpath("./td[position()=2]/a/@href").extract_first()
print(info_url)
req = requests.get(info_url)
req.encoding = 'utf-8'
info_data = req.text
info_selector = scrapy.Selector(text=info_data)
info = info_selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
officalUrl = info_selector.xpath("//div[@class='univ-website']/a/text()").extract_first()
mFile = sNo + '.jpg'
print(mFile)
src = info_selector.xpath("//td[@class='univ-logo']/img/@src").extract_first()
req = urllib.request.Request(src, headers=UniversitySpider.headers)
resp = urllib.request.urlopen(req)
data = resp.read()
fobj = open("download\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
item = UniversityItem()
item['sNo'] = sNo if sNo else ""
item['schoolName'] = schoolName if schoolName else ""
item['city'] = city if city else ""
item['officalUrl'] = officalUrl if officalUrl else ""
item['info'] = info if info else ""
item['mFile'] = mFile if mFile else ""
yield item
except Exception as err:
print(err)
except Exception as err:
print(err)
pipline部分:
import pymysql
class SpiderPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table University")
except:
pass
self.cursor.execute(
"create table University(sNo int,schoolName varchar(32),city varchar(16),officalUrl varchar(64),"
"info text,mFile varchar(16));")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened: self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("录入",self.count,"所大学")
def process_item(self, item, spider):
try:
print(item["sNo"])
print(item["schoolName"])
print(item["city"])
print(item["officalUrl"])
print(item["info"])
print(item["mFile"])
print()
if self.opened:
self.cursor.execute(
"insert into University(sNo,schoolName,city,officalUrl,info,mFile) values(%s,%s,%s,%s,%s,%s)",
(item["sNo"], item["schoolName"], item["city"], item["officalUrl"], item["info"], item["mFile"]))
self.count += 1
except Exception as err:
print(err)
return item
item部分:
import scrapy
class UniversityItem(scrapy.Item):
sNo=scrapy.Field()
schoolName=scrapy.Field()
city=scrapy.Field()
officalUrl=scrapy.Field()
info=scrapy.Field()
mFile=scrapy.Field()
结果展示:
爬取过程中出现几所大学详情界面无法载入的情况,后面个人游览器点击也无法载入,可能是访问过于频繁的原因
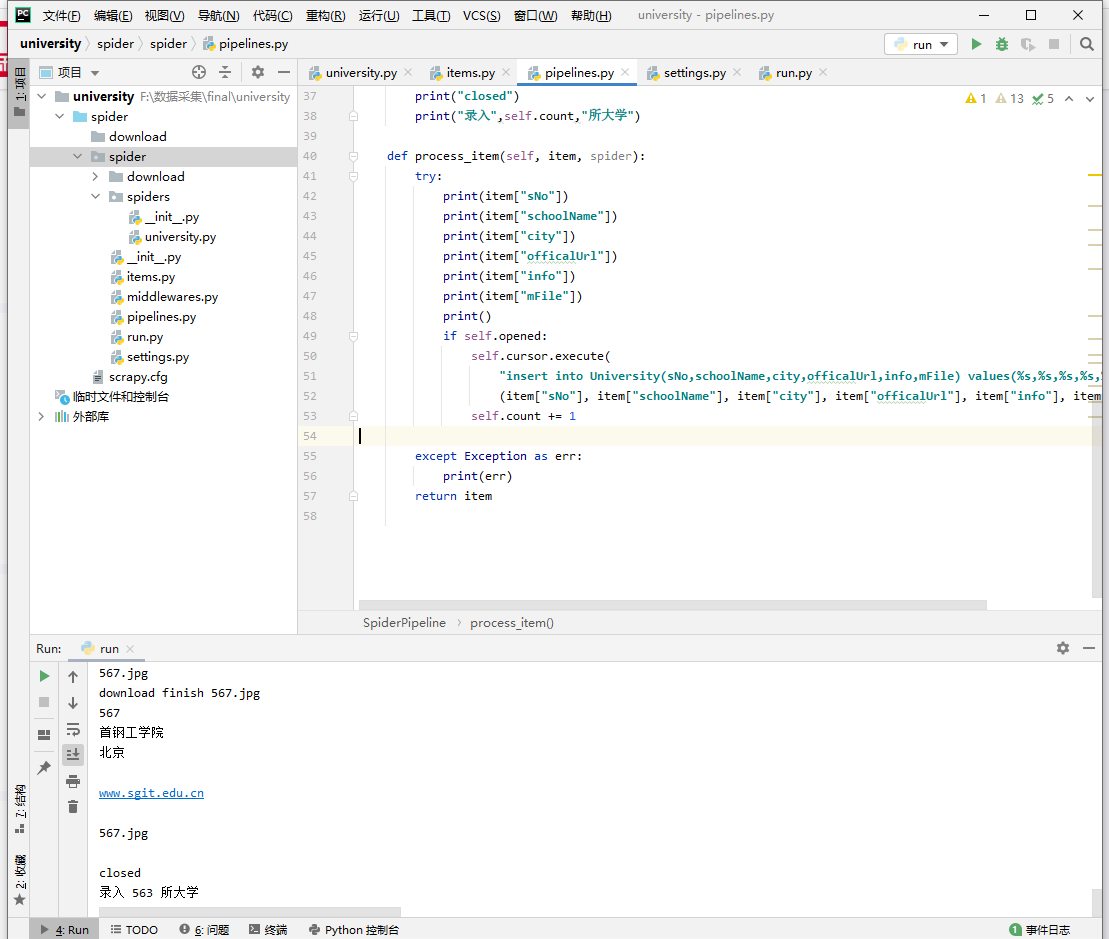
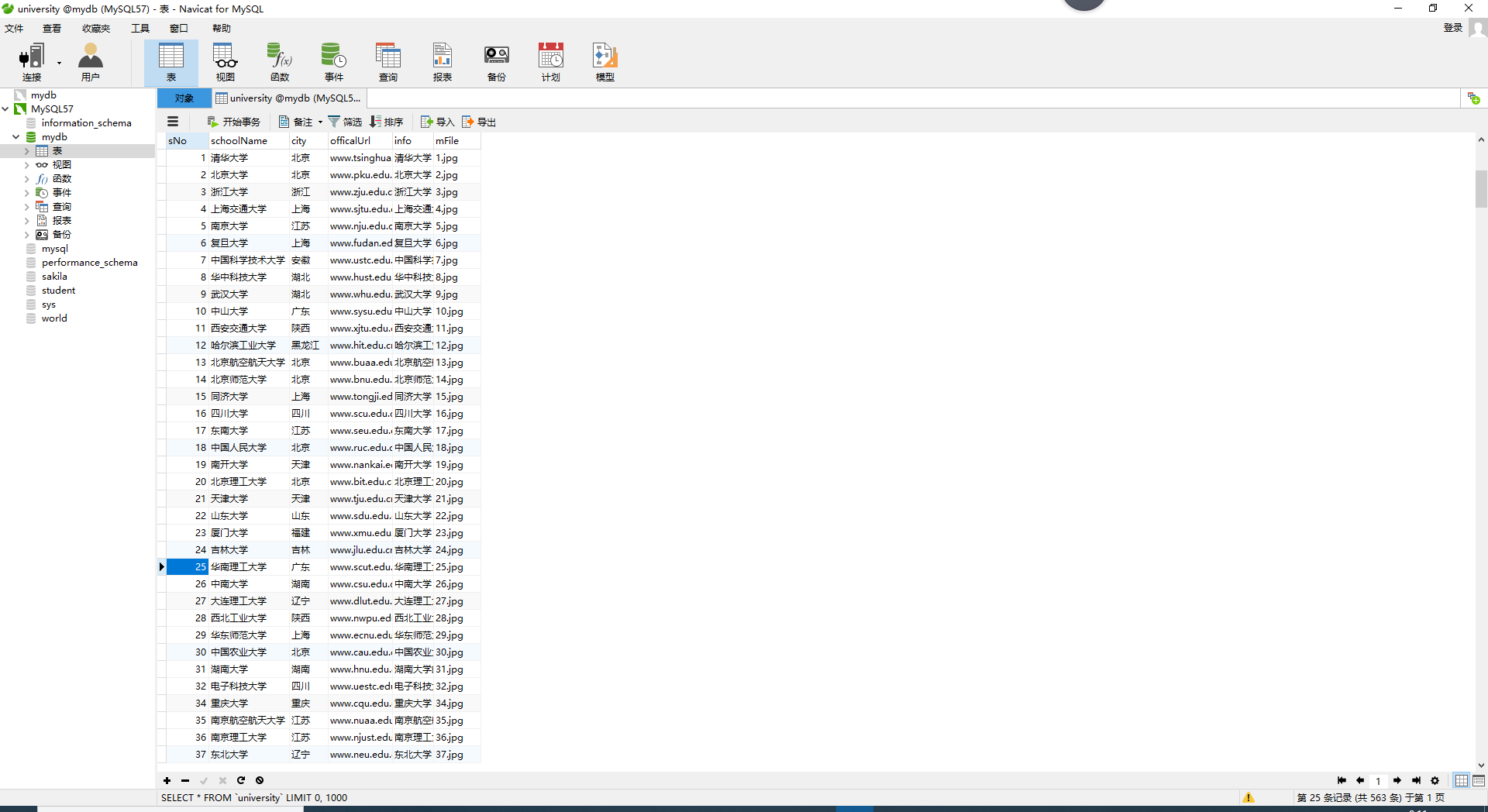

心得体会:
回顾scrapy框架的使用,以及Xpath方法,结合之前的知识不会感觉难度太大。
作业③:
代码展示:
import time
from selenium import webdriver
import pymysql
source_url="https://www.icourse163.org/channel/2001.htm"
driver=webdriver.Chrome()
driver.get(source_url)
driver.maximize_window()
login=driver.find_element_by_xpath("//*[@id='j-topnav']")
login.click()
time.sleep(3);
othrtlog = driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']");
othrtlog.click();
time.sleep(2);
driver.find_element_by_xpath("/html/body/div[12]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]").click()
time.sleep(2);
driver.switch_to.frame(driver.find_element_by_xpath("/html/body/div[12]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe"))
time.sleep(1)
driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input").send_keys("123456")
#定位到输入密码的位置,输入密码
driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]").send_keys("********")
#点击登录按钮
time.sleep(1);
driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a").click()
time.sleep(5);
driver.find_element_by_xpath("//*[@id='g-container']/div[1]/div/div/div/div[7]/div[3]/div/div").click()
time.sleep(3);
def open():
try:
con = pymysql.connect(host="localhost", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
cursor = con.cursor(pymysql.cursors.DictCursor)
try:
cursor.execute("drop table University")
except:
pass
cursor.execute(
"create table University(sNo int,schoolName varchar(32),city varchar(16),officalUrl varchar(64),"
"info text,mFile varchar(16));")
except Exception as err:
print(err)
def course(driver,cursor,count):
time.sleep(1)
lis=driver.find_elements_by_xpath("//div[@class='course-card-wrapper']")
for li in lis:
li.click()
window = driver.window_handles
driver.switch_to.window(window[1])
time.sleep(1)
driver.find_element_by_xpath("//*[@id='g-body']/div[3]/div/div/div/a").click()
time.sleep(1)
window = driver.window_handles
driver.switch_to.window(window[2])
time.sleep(1)
cCollage=driver.find_element_by_xpath('//*[@id="j-teacher"]/div/a/img').get_attribute('alt')
cCourse =driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
cCount =driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text.replace("
","")
cBrief = driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
cProcess=driver.find_element_by_xpath("//*[@id='course-enroll-info']/div/div[1]/div[2]/div[1]").text
team = driver.find_element_by_xpath(
"//*[@id='j-teacher']/div/div/div[2]/div/div[@class='um-list-slider_con']").text.split("
")
cTeacher = team[0]
no = len(team)
cTeam = ""
for i in range(0, no):
if (i % 2 == 0) & (i != 0):
cTeam = cTeam + "/" + team[i]
elif (i % 2 == 0):
cTeam = cTeam + team[i]
print(cTeam)
print(count, cCourse, cTeacher, cTeam, cCollage, cProcess, cCount, cBrief)
count=count+1
cursor.execute("insert into mooc_mine(id, cCourse, cTeacher, cTeam, cCollage, cProcess, cCount, cBrief) "
"values( % s, % s, % s, % s, % s, % s, % s, % s)",
(count, cCourse, cTeacher, cTeam, cCollage, cProcess, cCount, cBrief))
con.commit()
driver.close()
driver.switch_to.window(window[1])
time.sleep(1)
driver.close()
driver.switch_to.window(window[0])
time.sleep(1)
try:
driver.find_element_by_xpath(
"//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-disable-gh']")
except Exception as err:
print(err)
nextPage = driver.find_element_by_xpath(
"//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']")
nextPage.click()
course(driver,cursor,count)
def connect():
con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
cursor = con.cursor(pymysql.cursors.DictCursor)
try:
cursor.execute("drop table mooc_mine")
except:
pass
cursor.execute(
'create table mooc_mine(id int,cCourse varchar(32),cTeacher varchar(16),cTeam varchar(64),cCollage varchar(32),cProcess varchar(64),'
'cCount varchar(64),cBrief text);')
return con,cursor
count=0
con,cursor=connect()
course(driver,cursor,count)
con.commit()
con.close()
结果展示:
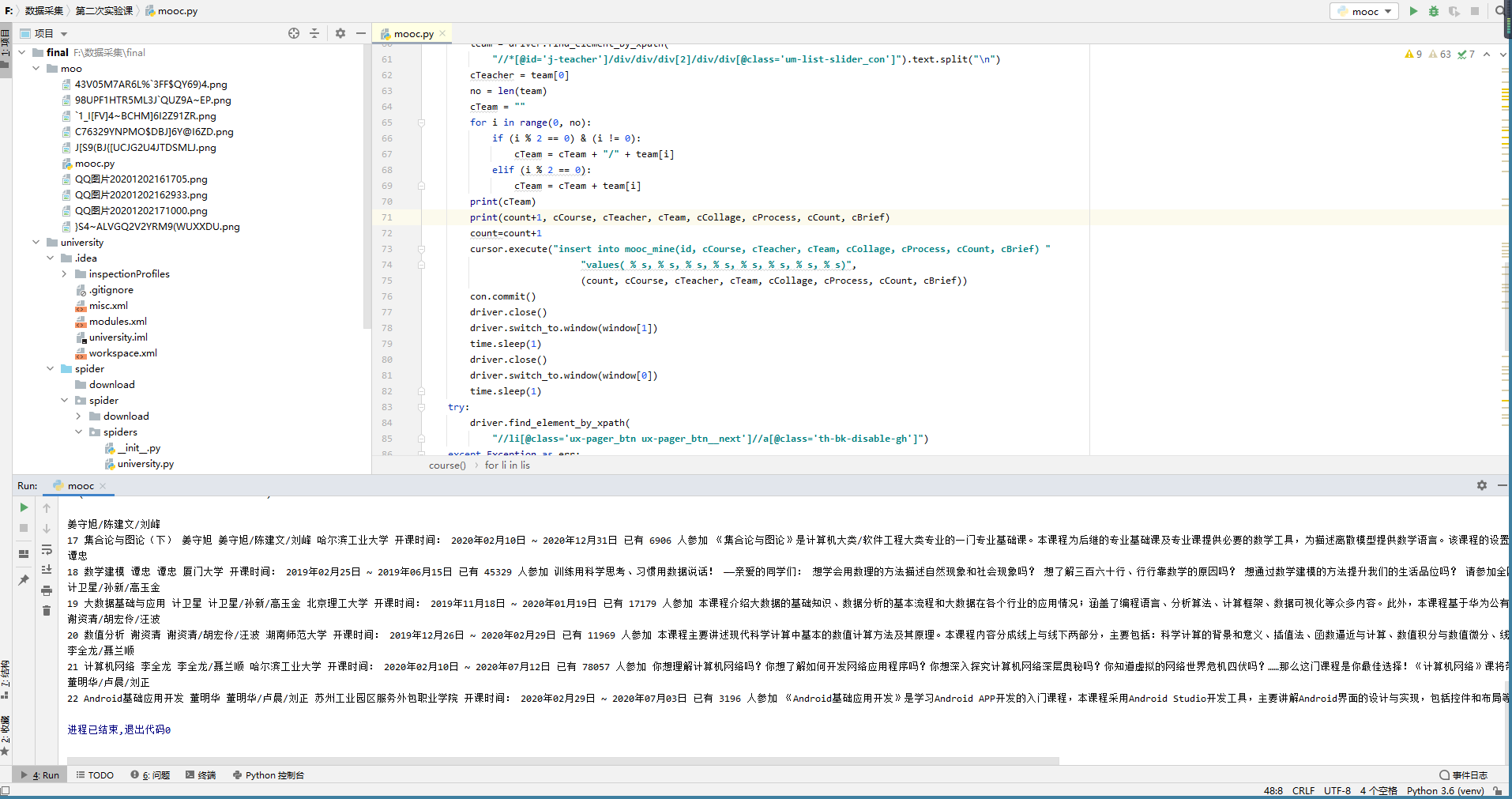
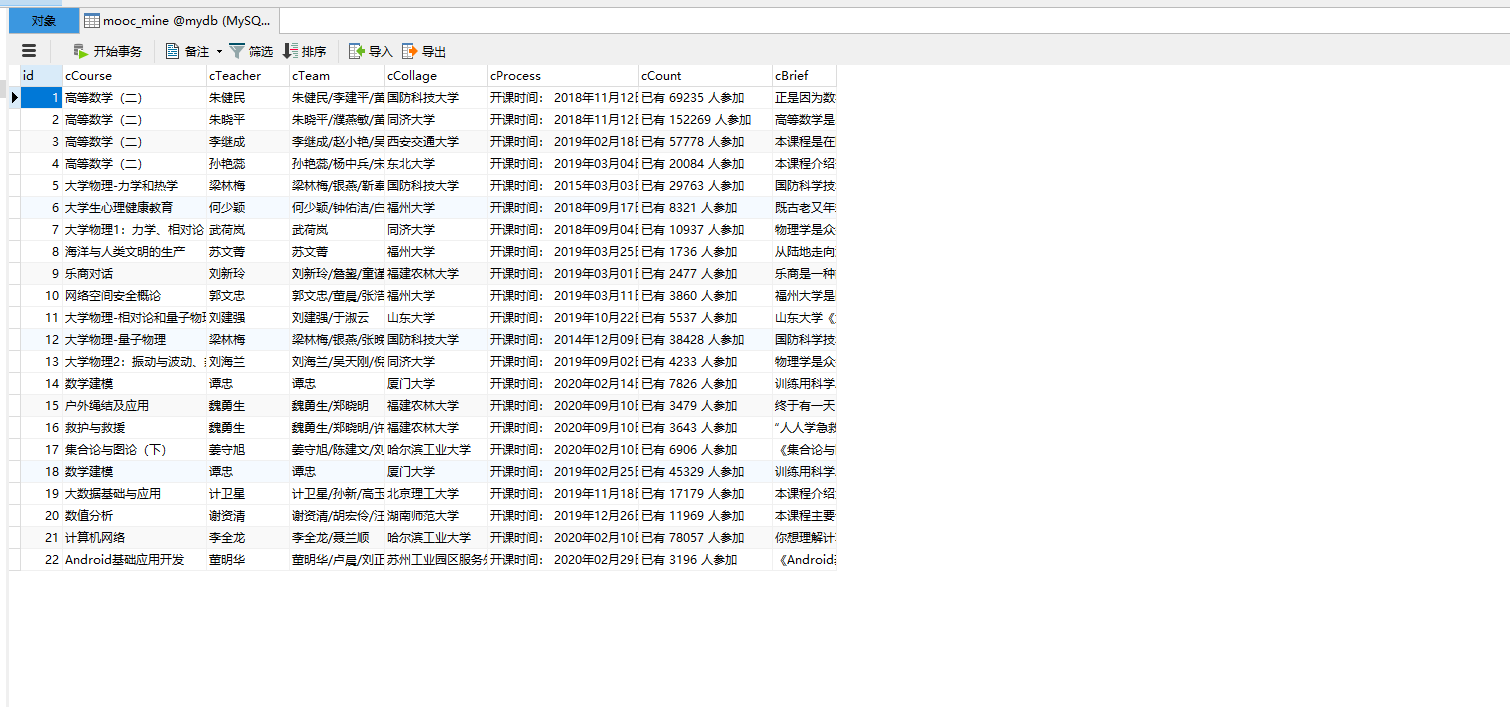
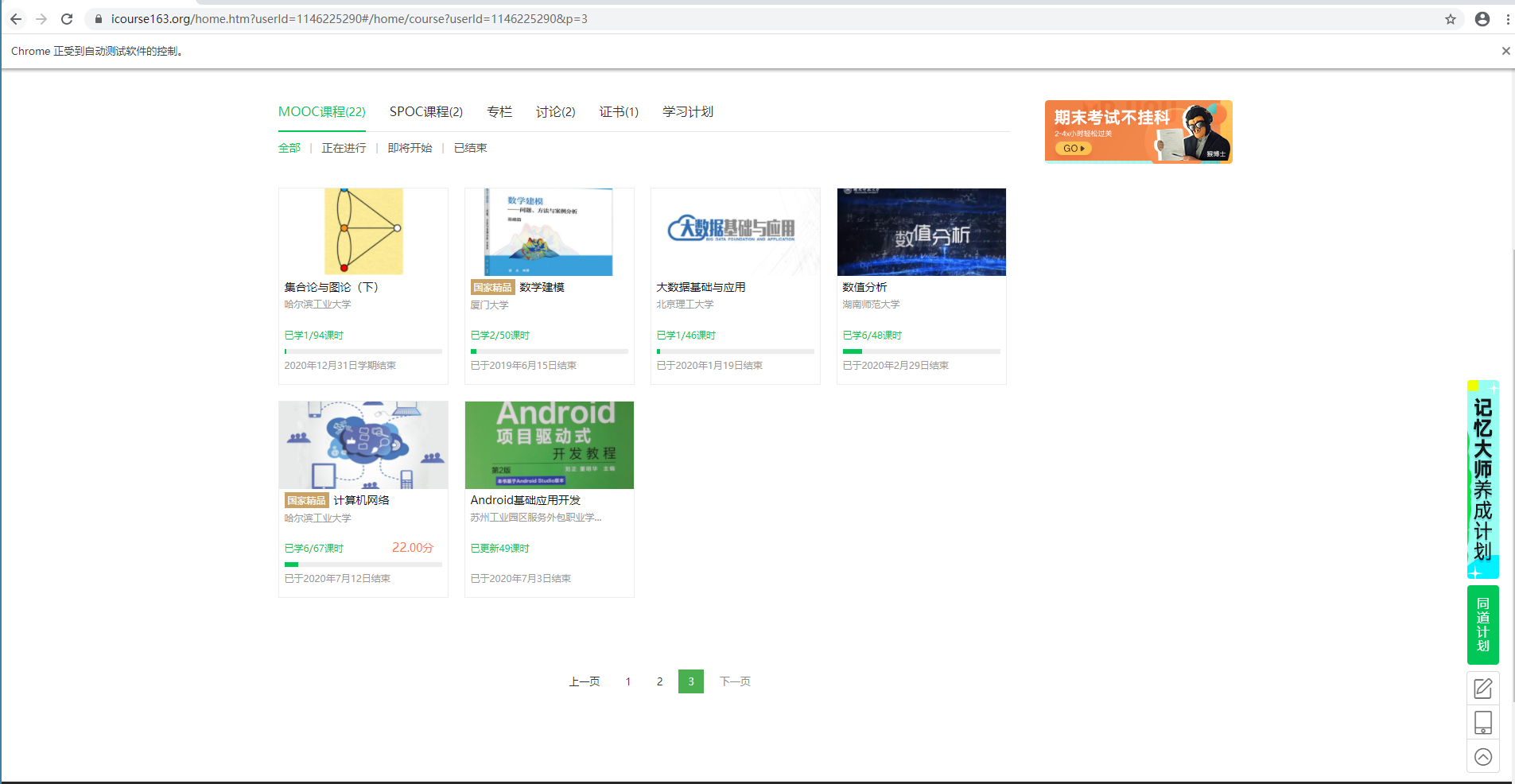
gif:
心得体会:
就按照上次差不多的步骤实现作业,不同在于课程详情方面要多跳转一个页面。