数据分析
py的就业方向
web方向
爬虫和数据分析
自动化运维
人工智能
数据分析历史
以前使用的语言是R语言进行数据分析的,BI(商业智能部)
R语言能做的事,python也能做,并且写的代码非常少
数据分析的介绍
数据分析的步骤
提出需求
产品经理或者领导
数据的来源
公司足够大,那每天产生的数据(Nginx日志数据),就足够我们分析使用
买数据
开始数据的清洗
通过删除,修改没替换等方式保证数据的准确性
得出结论
使用图表的方式
常见数据分析库
- numpy
- pandas
- matplotlib 画图
写代码的工具
anaconda 是一个软件,有一个Jupyter notebook
Jupyter notebook
ipython
numpy
简介
使用numpy进行数据分析
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
安装
pip install numpy
使用
NumPy Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构:
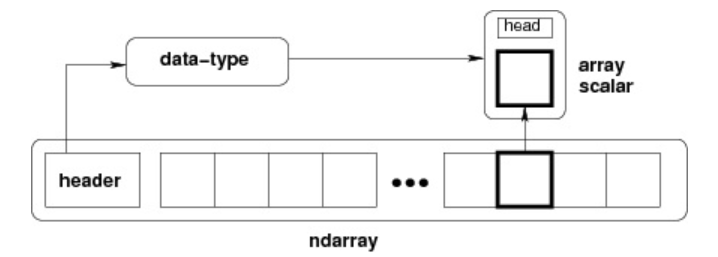
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
ndarray是一个包含了相同元素类型和大小的多维数组。
创建数组:
1、使用系统方法
empty(shape[, dtype, order]) # 根据给定的参数创建一个ndarray数组,值用随机数填充
例:
>>> np.empty([2, 2])
array([[ -9.74499359e+001, 6.69583040e-309],
[ 2.13182611e-314, 3.06959433e-309]])
empty_like(a[, dtype, order, subok]) #和empty不同的是,需要给出一个array的模板,就是a参数,新生成的ndarray继承了a的shape和dtype
例:
>>> a = ([1,2,3], [4,5,6])
>>> np.empty_like(a)
array([[-1073741821, -1073741821, 3], #random
[ 0, 0, -1073741821]])
eye(N[, M, k, dtype]) #生成一个N行M列的数组,K指定一条斜线,这条斜线上的值都是1,数组的其他元素维0
例:生成一个5行4列的数组,索引为1的斜线上全部是1,其他元素为0
>>> np.eye(5,4,1)
array([[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
identity(n[, dtype]) #生成一个正方形的数组即N×N类型的数组,且索引万恶哦0的斜线上维1,其他元素维0
例:
>>> np.identity(3)
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
ones(shape[, dtype, order]) #生成一个指定shape和dtype的数组,用1填充
例:
>>> np.ones(5)
array([ 1., 1., 1., 1., 1.])
>>> np.ones((2, 1))
array([[ 1.],
[ 1.]])
ones_like(a[, dtype, order, subok]) #和ones的区别就是需要给定一个dnarray模板,新生成的array继承了a的shape和dtype
例:
>>> x = np.arange(6)
>>> x = x.reshape((2, 3))
>>> x
array([[0, 1, 2],
[3, 4, 5]])
>>> np.ones_like(x)
array([[1, 1, 1],
[1, 1, 1]])
zeros(shape[, dtype, order]) #根据给定的shape,和dtype生成一个由0填充的数组
例:
>>> np.zeros(5)
array([ 0., 0., 0., 0., 0.])
zeros_like(a[, dtype, order, subok]) #根据a模板生成一个新的用0 填充的ndarray数组
例:
>>> x = np.arange(6)
>>> x = x.reshape((2, 3))
>>> x
array([[0, 1, 2],
[3, 4, 5]])
>>> np.zeros_like(x)
array([[0, 0, 0],
[0, 0, 0]])
full(shape, fill_value[, dtype, order]) #用指定的值填充数组
例:
>>> np.full((2, 2), 10)
array([[10, 10],
[10, 10]])
full_like(a, fill_value[, dtype, order, subok]) #根据a模板的shape和dtype生成一个数组,如果指定的填充数不是a的dtype类型,会向下取整,这时候也可以指定新数组的dtype类型。
例:
>>> x = np.arange(6, dtype=np.int)
>>> np.full_like(x, 1)
array([1, 1, 1, 1, 1, 1])
>>> np.full_like(x, 0.1) #如果full_value设置为1.2则就是用1填充
array([0, 0, 0, 0, 0, 0])
>>> np.full_like(x, 0.1, dtype=np.double)
array([ 0.1, 0.1, 0.1, 0.1, 0.1, 0.1])
>>> np.full_like(x, np.nan, dtype=np.double)
array([ nan, nan, nan, nan, nan, nan])
用指定的数据填充
array(object[, dtype, copy, order, subok, ndmin]) #用对象直接填充数组
例:
>>> np.array([1, 2, 3]) #一维数组
array([1, 2, 3])
>>> np.array([[1, 2], [3, 4]]) #二维数组
array([[1, 2],
[3, 4]])
>>> np.array([1, 2, 3], ndmin=2) #只有一个元素的二维数组
array([[1, 2, 3]])
>>> np.array(np.mat('1 2; 3 4')) #从子类创建
array([[1, 2],
[3, 4]])
asarray(a[, dtype, order]) #把lists, lists of tuples, tuples, tuples of tuples, tuples of lists and ndarrays转化为array
例:
>>> a = [1, 2]
>>> np.asarray(a)
array([1, 2])
asanyarray(a[, dtype, order]) #通过ndarray的子类创建array
>>> a = [1, 2]
>>> np.asanyarray(a)
array([1, 2])
ascontiguousarray(a[, dtype]) #返回一个地址连续的数组(C order)
>>> x = np.arange(6).reshape(2,3)
>>> np.ascontiguousarray(x, dtype=np.float32)
array([[ 0., 1., 2.],
[ 3., 4., 5.]], dtype=float32)
>>> x.flags['C_CONTIGUOUS']
True
asmatrix(data[, dtype]) # 把数组转化为矩阵,新的变量没有copy数据,只是指向原有的数据
>>> x = np.array([[1, 2], [3, 4]])
>>> m = np.asmatrix(x)
>>> x[0,0] = 5
>>> m
matrix([[5, 2], [3, 4]])
copy(a[, order]) #顾名思义就是复制的意思
>>> x = np.array([1, 2, 3])
>>> y = x
>>> z = np.copy(x)
>>> x[0] = 10
>>> x[0] == y[0]
True
>>> x[0] == z[0]
False
frombuffer(buffer[, dtype, count, offset]) #把buffer数据转化为1维数组ps:如果数据不是机器字节顺序,需要指定他的dtype类型
>>> s = 'hello world'
>>> np.frombuffer(s, dtype='S1', count=5, offset=6)
array(['w', 'o', 'r', 'l', 'd'],
dtype='|S1')
frombuffer(buffer[, dtype, count, offset]) #从文件读取数据 ps:该方法不长用用save替代
fromfunction(function, shape, **kwargs) #用方法计算出来的数据填充数组
>>> np.fromfunction(lambda i, j: i + j, (3, 3), dtype=int)
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
fromiter(iterable, dtype[, count]) #通过迭代器生成一个一维数组
>>> iterable = (x*x for x in range(5))
>>> np.fromiter(iterable, np.float)
array([ 0., 1., 4., 9., 16.])
fromstring(string[, dtype, count, sep]) #把二进制流或者字符串转化维数组
>>> np.fromstring('x01x02', dtype=np.uint8)
array([1, 2], dtype=uint8)
>>> np.fromstring('1 2', dtype=int, sep=' ')
array([1, 2])
>>> np.fromstring('1, 2', dtype=int, sep=',')
array([1, 2])
>>> np.fromstring('x01x02x03x04x05', dtype=np.uint8, count=3)
array([1, 2, 3], dtype=uint8)
arange([start,] stop[, step,][, dtype])
#根据给定的区间创建连续的值
>>> np.arange(3)
array([0, 1, 2])
>>> np.arange(3.0)
array([ 0., 1., 2.])
>>> np.arange(3,7)
array([3, 4, 5, 6])
>>> np.arange(3,7,2)
array([3, 5])
numpu.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None) #arrange一样,主要是生成浮点型
>>> np.linspace(2.0, 3.0, num=5)
array([ 2. , 2.25, 2.5 , 2.75, 3. ])
>>> np.linspace(2.0, 3.0, num=5, endpoint=False)
array([ 2. , 2.2, 2.4, 2.6, 2.8])
>>> np.linspace(2.0, 3.0, num=5, retstep=True)
(array([ 2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
numpy.logspace(start,stop,num=50,endpoint=True,base=10.0,dtype=None) #log函数.base默认值为10
>>> np.logspace(2.0, 3.0, num=4)
array([ 100. ,
215.443469 ,
464.15888336,
1000. ])
>>> np.logspace(2.0, 3.0, num=4, endpoint=False)
array([ 100. ,
177.827941 ,
316.22776602,
562.34132519])
>>> np.logspace(2.0, 3.0, num=4, base=2.0)
array([ 4. ,
5.0396842 ,
6.34960421,
8. ])
numpy.geomspace(start,stop,num=50,endpoint=True,dtype=None) #几何级增长
>>> np.geomspace(1, 1000, num=4)
array([ 1., 10., 100., 1000.])
>>> np.geomspace(1, 1000, num=3, endpoint=False)
array([ 1., 10., 100.])
>>> np.geomspace(1, 1000, num=4, endpoint=False)
array([ 1. ,
5.62341325,
31.6227766 ,
177.827941 ])
>>> np.geomspace(1, 256, num=9)
array([ 1., 2., 4., 8., 16., 32., 64., 128., 256.])
numpy.emshgrid(*xi,**kwargs) #把向量坐标转化为矩阵坐标;在二维度数组中长度为M,N的的俩个数组作为输入:如果indexing='ij',则shape(M,N)如果indexing='xy'则shape(N.M)
>>> nx, ny = (3, 2)
>>> x = np.linspace(0, 1, nx)
>>> y = np.linspace(0, 1, ny)
>>> xv, yv = np.meshgrid(x, y)
>>> xv
array([[ 0. , 0.5, 1. ],
[ 0. , 0.5, 1. ]])
>>> yv
array([[ 0., 0., 0.],
[ 1., 1., 1.]])
numpy.diag(v,k=0) #提取对角或构建一个对角阵
>>> x = np.arange(9).reshape((3,3))
>>> xarray([[0, 1, 2],
[3, 4, 5], [6, 7, 8]])
>>> np.diag(x)
array([0, 4, 8])
>>> np.diag(x, k=1)
array([1, 5])
>>> np.diag(x, k=-1
array([3, 7])
numpy.diagflat(v,k=0) #一个扁平输入作为一个二维数组的对角
>>> np.diagflat([[1,2], [3,4]])
array([[1, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]])
numpy.tri(N,M=None,k=0,dtype=<type 'float'>) #这个不会翻译,但是看数据有点映像
>>> np.tri(3, 5, 2, dtype=int)
array([[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]])
numpy.vander(x,N=None,incresing=False) # 范德蒙式,程序不重要,重要的是科学计算
>>> x = np.array([1, 2, 3, 5])
>>> N = 3
>>> np.vander(x, N)
array([[ 1, 1, 1],
[ 4, 2, 1],
[ 9, 3, 1],
[25, 5, 1]])
numpy.mat(data,dtype=None) #输入转化为矩阵,创建一个新变量,指向旧的数据
>>> x = np.array([[1, 2], [3, 4]])
>>> m = np.asmatrix(x)
>>> x[0,0] = 5
>>> m
matrix([[5, 2], [3, 4]])
numpy.bmat(obj,ldict=None,gdict=None) #用字符串,嵌套序列,或者数组创建矩阵
>>> A = np.mat('1 1; 1 1')
>>> B = np.mat('2 2; 2 2')
>>> C = np.mat('3 4; 5 6')
>>> D = np.mat('7 8; 9 0')
>>> np.bmat([[A, B], [C, D]])
matrix([[1, 1, 2, 2],
[1, 1, 2, 2],
[3, 4, 7, 8],
[5, 6, 9, 0]])
>>> np.bmat(np.r_[np.c_[A, B], np.c_[C, D]])
matrix([[1, 1, 2, 2],
[1, 1, 2, 2],
[3, 4, 7, 8],
[5, 6, 9, 0]])
>>> np.bmat('A,B; C,D')
matrix([[1, 1, 2, 2],
[1, 1, 2, 2],
[3, 4, 7, 8],
[5, 6, 9, 0]])
实例
#!/usr/bin/env python
# coding: utf-8
# In[21]:
import numpy as np
# ## 为啥使用numpy
# 计算数组的总数
# In[22]:
shop_car = [2,3,10,3]
shop_price = [10,20,1010,23]
# In[23]:
shop_car_np = np.array(shop_car)
# In[24]:
shop_price_np = np.array(shop_price)
# In[25]:
shop_car_np
# In[26]:
shop_price_np
# In[27]:
# 利用array进行求和
np.sum(shop_car_np * shop_price_np)
# ## 常见属性
# ### 一维数组
# In[29]:
arr = np.array([1,1,23,42,1,])
# In[30]:
arr # 简单的ndarray一维数组
# In[31]:
arr.dtype # 数组的数据类型
# In[32]:
arr.size # 数组元素的个数
# In[33]:
arr.ndim # 数组的维度
# In[34]:
arr.shape # 数组的个数 (元组的形式)
# ### 二维数组
# In[36]:
arr2 = np.array([[1,2,3,4,5],[6,7,8,9,0]])
# In[37]:
arr2
# In[39]:
arr2.ndim
# In[40]:
arr2.shape # 数组的个数,前面是行,后面是列 2行5列
# 数组的转置 T
#
# In[41]:
arr2.T
# ### 数据类型的转换
# In[43]:
arr
# In[44]:
arr.dtype
# In[45]:
arr.astype('float') # 强制的转换为指定的数据类型
# ### ndarray数组的创建方式
# In[46]:
arr3 = np.array([1,2,3,4,5,6],dtype='float')
# In[47]:
arr3
# numpy版的arange
# In[48]:
np.arange(1,9)
# In[54]:
np.arange(0,10)
# linspace 创建数组
# In[57]:
np.linspace(1,10,num=5) # num控制分割数量
# In[56]:
np.linspace(1,10,num=5,endpoint=False) # endpoint 控制最后一位
# In[ ]:
# In[60]:
np.zeros(5)
# In[61]:
np.zeros((2,3),dtype='int')
# In[62]:
np.ones(5)
# In[63]:
np.ones((3,4))
# 生成随机数组
# In[64]:
np.empty((2,3))
# In[65]:
get_ipython().run_line_magic('pinfo', 'np.eye')
# In[ ]:
# 默认生成5行5列的数组,并且数组的对角线默认是1
# In[67]:
np.eye(5,dtype='int')
# ## ndarray的索引
# 一维数组
# In[68]:
arr
# In[70]:
#### 列表中怎么通过索引获取值,在这里也是一样的
arr[2]
# 二维数组
# In[71]:
arr2 # 分为行索引与列索引
# In[73]:
arr2[0,2] # 逗号前面是行索引,后面是列索引
# ### 切片
# 顾前不顾后
# In[78]:
arr
#
# In[81]:
arr[1:3]
# 二维数组
# In[82]:
arr2
# 切出 2,3 7,8 # 和索引使用的方法一致,前面行索引,后面列索引
# In[90]:
arr2[0:2,1:3]
# #### 布尔型索引
# In[91]:
arr
# 查询arr中大于4的所有数据
# In[94]:
arr > 4
# In[95]:
arr[arr>4]
# In[96]:
arr2
# In[97]:
arr2[arr2 > 3]
# ### 通用函数
# In[101]:
a = -4
# In[104]:
np.abs(a) # 绝对值
# In[105]:
np.ceil(4.3) # 向上取整
# In[106]:
np.floor(4.6) # 向下取整
# In[109]:
np.rint(4.6) # 四舍五入取整
# In[108]:
np.rint(4.3)
# In[110]:
np.modf(5.6)
# isnan # 判断某一数据是否是nan == not a number(不是数字)
# In[113]:
np.nan
# In[114]:
arr
# In[115]:
np.sum(arr)
# In[116]:
np.cumsum(arr)
# ### 随机数
# In[119]:
np.random.rand()
# In[120]:
np.random.rand(10) # 随机生成10个0-1之间的数字
# In[121]:
np.random.randint(5)
# In[123]:
np.random.choice(6,4) # 随机生成3个 0-5之间的数
# In[124]:
arr
# In[127]:
np.random.shuffle(arr) # 随机打乱给定的数组
# In[128]:
arr
# In[129]:
arr
# 转换为二维数组
# In[133]:
arr.reshape(5,1) # 必须数组元素对的上
Anaconda
1. 简介
Anaconda在英文中是“蟒蛇”,所以Anaconda的图标就像一个收尾互相咬住的“蟒蛇”。
简单来说,Anaconda是包管理器和环境管理器,Jupyter notebook 可以将数据分析的代码、图像和文档全部组合到一个web文档中。
下载
目前最新版本是 python 3.6,默认下载也是 Python 3.6。
安装
参考安装教程
Anaconda 的下载文件比较大(约 500 MB),因为Anaconda附带了 Python 中最常用的数据科学包。
如果计算机上已经安装了 Python,安装不会对你有任何影响。实际上,脚本和程序使用的默认 Python 是 Anaconda 附带的 Python。
2. 使用
为什么安装
1)Anaconda 附带了一大批常用数据科学包,它附带了 conda、Python 和 150 多个科学包及其依赖项。因此你可以立即开始处理数据。
2)管理包
Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的。
在数据分析中,你会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
3)管理环境
为什么需要管理环境呢?
比如你在A项目中用了 Python 2,而新的项目B老大要求使用Python 3,而同时安装两个Python版本可能会造成许多混乱和错误。这时候 conda就可以帮助你为不同的项目建立不同的运行环境。
还有很多项目使用的包版本不同,比如不同的pandas版本,不可能同时安装两个 Numpy 版本,你要做的应该是,为每个 Numpy 版本创建一个环境,然后项目的对应环境中工作。这时候conda就可以帮你做到,而且conda不会影响系统自带的python。
测试安装
cmd中输入conda list查看安装的内容
在开始界面Anaconda中点击Jupyter Notebook即可打开浏览器
设置Anaconda镜像
使用conda install 包名 安装需要的Python非常方便,但是官方的服务器在国外,因此下载速度很慢,国内清华大学提供了Anaconda的仓库镜像,我们只需要配置Anaconda的配置文件,添加清华的镜像源,然后将其设置为第一搜索渠道即可cmd命令行下分别执行以下命令:
(参考 https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
配置完后可以测试一下,安装第三方包明显神速
3. 包管理
安装Anacond之后,我们就可以很方便的管理安装包(安装,卸载,更新)。
1. 安装包
conda 的包管理功能和pip 是一样的,当然你选择pip 来安装包也是没问题的。
1. #安装 matplotlib
2. conda install matplotlib
2. 卸载包
1. # 删除包
2. conda remove matplotlib
3. 更新包
1. # 包更新
2. conda update matplotlib
4. 查询已经安装的包
1. # 查看已安装的包
2. conda list
4.环境管理
conda 可以为你不同的项目建立不同的运行环境。
1. 创建python2.7版本的环境
#创建python2.7版本的环境
conda create -n python27 python=2.7
上面的命令中,python27是设置环境的名称(-n是指该命令后面的python27是你要创建环境的名称)
注意:创建环境时,可以指定要安装在环境中的Python版本。当你同时使用 Python 2.x 和 Python 3.x 中的代码时这很有用。
2. 进入环境
#进入我刚创建的python27环境
conda activate python27
进入之后,你可以在终端提示符中看到环境名称(python27)。当然,当你进入环境后,可以用conda list 查看环境中默认的安装包。

3. 离开环境
#离开当前环境
deactivate
4. 共享环境
共享环境非常有用,它能让其他人安装你代码中使用的所有包,并确保这些包的版本正确。比如你开发了一个系统,你要提交给项目部署系统的人来部署你的项目,但是他们并不知道你当时开发时使用的是哪个python版本,以及使用了哪些包和包的版本。这怎么办呢?你可以在你当前的环境的终端中使用:
#将你当前的环境保存到文件中包保存为YAML文件
conda env export > environment.yaml
将你当前的环境保存到文件中包保存为YAML文件(包括Pyhton版本和所有包的名称)。命令的第一部分 conda env export 用于输出环境中的所有包的名称(包括 Python 版本)。你在终端中上可以看到导出的环境文件路径。在 GitHub 上共享代码时,最好同样创建环境文件并将其包括在代码库中。这能让其他人更轻松地安装你的代码的所有依赖项。
导出的环境文件,在其他电脑环境中如何使用呢?
首先在conda中进入你的环境,比如conda activate python27。然后在使用以下命令更新你的环境:
#其中-f表示你要导出文件在本地的路径,所以/path/to/environment.yml要换成你本地的实际路径
conda env update -f=/path/to/environment.yml
对于不使用conda 的用户,我们通常还会使用以下命令将一个 txt文件导出并包括在其中:
pip freeze > environment.txt
然后我将该文件包含在项目的代码库中,其他项目成员即使在他的电脑上没有安装conda也可以使用该文件来安装和我一样的开发环境:
他在自己的电脑上进入python命令环境,然后运行以下命令就可以安装该项目需要的包:
1. #其中C:UsersMicrostrongenviroment.txt是该文件在你电脑上的实际路径。
2. pip install -r C:UsersMicrostrongenviroment.txt
5. 列出环境
有时候会忘记自己创建的环境名称,这时候用 conda env list 就可以列出你创建的所有环境。
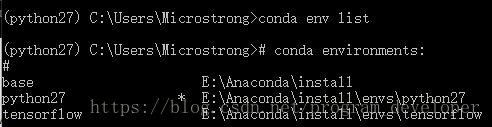
你会看到环境的列表,而且你当前所在环境的旁边会有一个星号。默认的环境(即当你不在选定环境中时使用的环境)名为 base。
6. 删除环境
如果你不再使用某个环境,可以使用以下命令。
1. #删除指定的环境(在这里环境名为 python27)。
2. conda env remove -n python27
Jupyter Notebook
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享文学化程序文档,支持实时代码,数学方程,可视化和 markdown。 用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等
1. 安装
使用Anaconda安装
上文有介绍
使用pip命令安装
有经验的Python用户,可以使用Python的包管理器pip而不是Anaconda 来安装Jupyter 。
如果已经安装了Python 3:
python3 -m pip install --upgrade pip
pi3 install jupyter
如果已经安装了Python 2:
python2 -m pip install --upgrade pip
pip2 install jupyter
但推荐使用Anaconda,自带了Numpy、Scipy、Matplotlib等多种python开发包和Jupyter Notebook!
2. 运行
成功安装Jupyter Notebook后,在Terminal (Mac / Linux)或Command Prompt(Windows)中运行以下命令就可打开Jupyter Notebook
jupyter notebook
执行上面命令之后, Jupyter Notebook 将在你的默认浏览器中打开,网址为:http://localhost:8888/tree
或者在开始菜单页面直接打开软件
3. 使用
主面板
打开Notebook,可以看到主面板。在菜单栏中有Files(文件)、Running(运行)、Clusters(集群)、三个选项。用到最多的是Files,我们可以在这里完成notebook的新建、重命名、复制等操作。
Files 基本上列出了所有的文件,
Running 显示你当前已经打开的终端和Notebooks,
Clusters 由 IPython parallel 包提供,用于并行计算。
要打开一个新的 Jupyter Notebook,请单击页面右侧的“New”选项卡。在这里,你有四个选项可供选择:
⦁ Python 3
⦁ Text File (文本文件)
⦁ Folder (文件夹)
⦁ Terminal (终端)
在 "Text File" 选项中,你会得到一个空白的文档。输入你喜欢的任何字母,单词和数字。它基本上是一个文本编辑器(类似于 Ubuntu 上的应用程序)。你也可以选择一种语言(支持非常多的语言),然后用该语言来写一个脚本。你还可以查找和替换文件中的单词。
在 "Folder" 选项中, 顾名思义它的功能就是创建文件夹。你可以创建一个新文件夹来放入文件,重新命名或者删除它。
"Terminal" 的工作方式与你的 Mac 电脑或 Linux 电脑上的终端完全相同(或者 Windows 上的 cmd )。它在你的Web浏览器中支持终端会话。在这个终端中输入 python ,可以写 python 脚本了。
创建python文件
从“New”选项中选择 "Python 3" 选项。你会看到如下的截图:

代码上方的菜单栏提供了操作单元格的各种选项:
insert (添加),edit (编辑),cut (剪切),move cell up/down (上下移动单元格),run cells(在单元格中运行代码),interupt (停止代码),save (保存工作),以及 restart (重新启动内核)

在下拉菜单中(如上所示),你有四个选项:
Code - 这是你输入代码的地方
Markdown - 这是你输入文本的地方。你可以在运行代码后添加结论,添加注释等。
Raw NBConvert - 这是一个命令行工具,可将你的笔记本转换为另一种格式(如 HTML)
Heading - 你可以将标题添加到单独的小节并使你的 Notebook 看起来干净整洁。这个选项现在已经集成到 Markdown 选项中。添加一个“##”,以确保在你之后输入的内容将被视为标题
4.编辑界面
一个notebook的编辑界面主要由四部分组成:名称、菜单栏、工具条以及单元(Cell),如下图所示:

1.名称
1.在这里,我们可以修改notebook的名字,直接点击当前名称,弹出对话框进行修改:

2.菜单栏详解
2.1 File

2.2 Edit

2.3 View

2.4 Insert

2.5 Cell

2.6 Kernel

2.7 Help

3. 工具条
工具条中的功能基本上在菜单中都可以实现,这里是为了能更快捷的操作,将一些常用按钮放了出来。下图是对各按钮的解释。

4 .单元(Cell)
在单元中我们可以编辑文字、编写代码、绘制图片等等。对于单元的详细内容放在第五节中介绍。
两种模式
对于Notebook中的单元,有两种模式:
- 命令模式(Command Mode)
- 编辑模式(Edit Mode)
在不同模式下我们可以进行不同的操作

如上图,在编辑模式(Edit Mode)下,右上角出现一只铅笔的图标,单元左侧边框线呈现出绿色,点Esc键或运行单元格(ctrl-enter)切换回命令模式。

在命令模式(Command Mode)下,铅笔图标消失,单元左侧边框线呈现蓝色,按Enter键或者双击cell变为编辑状态。
快捷键
1.运行当前单元格代码:crtl + enter
2.运行当前单元格并选中下一个单元格:shift + enter
编辑模式:鼠标闪动,并且框的颜色是绿色
命令行模式:按esc到命令行模式,颜色编程蓝色
3.删除当前单元格:在命令行模式下, 按dd即可
4.在当前单元格的上方添加一个单元格:在命令行模式下, 按a(above)即可添加
5.在当前单元格的下方添加一个单元格:在命令行模式下,按b(below)即可添加
6.代码和markdown进行切换:在命令行模式下,按m进行切换
一旦进入命令模式(即没有活动单元格),就可以尝试以下快捷键:
-
A 键将在选中单元格上方插入新单元格
-
B 键将在选中单元格下方插入一个单元格
-
要删除单元格,请连续按两次 D 键
-
要撤消已删除的单元格,请按 Z 键
-
Y 键将当前的选中单元格变成代码单元格
-
按住 Shift + 向上或向下箭头键可以选择多个单元格。在多选模式下,按 Shift + M 会合并选中的单元格
-
F 键会弹出 “查找和替换” 菜单
处于编辑模式时(在命令模式下按 Enter 键进入编辑模式),你会发现以下快捷键非常好用:
-
Ctrl + Home 转到单元格的开头
-
Ctrl + S 会保存你的工作
-
和上面提过的一样,Ctrl + Enter 将运行你的整个单元格
-
Alt + Enter 不仅会运行你的单元格,它还会在下方添加一个新的单元格
-
Ctrl + Shift + F 打开命令选项板
-
按tab键查看提示信息或者补全命令
-
在一个库、方法或变量前加上 ?,就可以获得它的一个快速语法说明
-
使用分号可以阻止该行函数的结果输出
5. jupyter扩展
扩展可以有效提高你的 Jupyter Notebooks 的生产力。安装和使用扩展的最佳工具之一是 Nbextensions。它需要两个简单的步骤来安装(也有其他方法,但我发现这是最方便的):
安装
第1步:用 pip 来安装它:
pip install jupyter_contrib_nbextensions
第2步:安装关联的 JavaScript 和 CSS 文件
jupyter contrib nbextension install --user
完成此操作后,你会在 Jupyter Notebook 主页顶部看到一个 Nbextensions 选项卡。这里面有很多非常棒的扩展供你使用
启用
要启用一个扩展,只需点击它来激活。我在下面提到了4个我认为最有用的扩展:
Code prettify:重新格式化和美化代码块的内容
Printview:这个扩展添加了一个工具栏按钮来调用当前 Notebook 的 jupyter nbconvert,并可选择在新的浏览器标签中显示转换后的文件
Scratchpad:这个扩展增加一个便捷单元格,它可以让你运行你的代码而不必修改你的 Notebook。这是一个非常方便的扩展,特别是当你想要测试你的代码,但不想在你的活动Notebook上做这件事。
Table of Contents (2):这个扩展可以收集你的 Notebook 中的所有标题,并将它们显示在一个浮动窗口中
6. 其他
保存和共享你的 Notebook
这是 Jupyter Notebook 中最重要和最棒的功能之一。当我需要写博客文章,但我的代码和注释都保存在 Jupyter 文件中时,我需要先将它们转换为另一种格式。请记住,这些 Notebooks 采用 json 格式,在共享它时这并不是很有帮助。我无法在电子邮件或博客上发布不同的单元格或代码块,对吧?
进入 Files 菜单,你会看到一个 Download As 选项:

你可以将你的 Notebook 保存为 7 个选项中的任何一个。最常用的是 .ipynb 文件,这样其他人就可以在自己的机器上复制代码;或者保存为 .html 文件, 这样会打开一个网页(当你想要保存嵌入在 Notebook 中的图像时,这会派上用场)
你也可以使用 nbconvert 选项手动将你的 Notebook 转换为不同的格式,如 HTML 或 PDF。
你还可以使用 jupyterhub,它允许你在其服务器上托管 Notebooks 并与多个用户共享。许多顶尖的研究项目都使用这个功能用于协作。
最佳实践
虽然单独工作可能很有趣, 但大多数时候你会发现自己是在一个团队中工作。在这种情况下,遵循指导方针和最佳实践非常重要,这样可以确保你的代码和 Jupyter Notebooks 被正确标注,以便与你的团队成员保持一致。下面我列出了一些最佳实践指南,你在 Jupyter Notebooks 上工作时一定要遵循以下指南:
对于任何程序员来说最重要的事情之一:始终确保为代码添加合适的注释!
确保你有代码所需的文档。
考虑一个命名方案,并坚持在所有代码中使用以确保一致性。这样其他人更容易读懂你的代码。
无论你需要什么库,在 Notebooks 开始时导入它们(并在它们旁边添加注释,说明导入它们的目的)。
确保代码中行与行之间有适当间隔,不要把循环和函数放在同一行中。
有时候你会发现你的文件变得非常繁重。看看有没有方法隐藏你认为对于以后参考不太重要的代码。 Notebooks 看起来整洁干净, 让人赏心悦目也非常重要。
Matplotlib 可以很漂亮整洁地展示你的 Notebook,看看怎么使用它!
另一个提示! 当你想创建演示文稿时,首先想到的工具是 PowerPoint 和 Google Slides。其实你的 Jupyter Notebooks 也可以创建幻灯片!还记得我说它超级灵活吗? 我一点都没有夸大。
要将你的 Notebooks 转换为幻灯片,请转到 View -> Cell Toolbar,然后单击 Slideshow。看!现在,每个代码块都在右侧显示一个 Slide Type 的下拉选项。它提供了以下 5 个选项:

好好试一试每一个选项以更好地理解它,它会改变你呈现你的代码的方式!